(註:從微信公眾:CloudGeek複製過來,格式略微錯亂,更好閱讀體驗請移步公眾號,二維碼在文末) 今天我們來跟一下predicates的整個過程;predicate這個詞應該是“斷言、斷定”的意思,在這裡我們姑且翻譯為“預選”,雖然不符合這個單詞的本意,但是在schedule過程中predica ...
(註:從微信公眾:CloudGeek複製過來,格式略微錯亂,更好閱讀體驗請移步公眾號,二維碼在文末)

今天我們來跟一下predicates的整個過程;predicate這個詞應該是“斷言、斷定”的意思,在這裡我們姑且翻譯為“預選”,雖然不符合這個單詞的本意,但是在schedule過程中predicate過程做的事情確實還是叫“預選”比較好理解!
上一講我們提到predicate過程的入口在findNodesThatFit這個函數,所以今天我們從這個函數入手,看看這裡面有哪些玄機。這個函數在:pkg/scheduler/core/generic_scheduler.go:289,聲明如下:
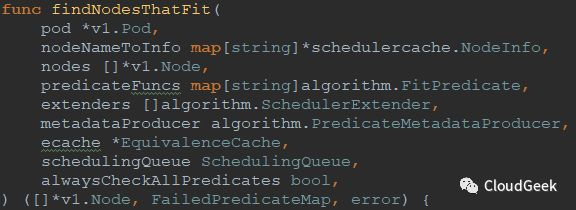
可以看到有不少參數,我們理一下這些參數都是什麼:
- pod *v1.Pod,
//表示一個pod - nodeNameToInfo map[string]*schedulercache.NodeInfo,
//NodeInfo是node級別的信息集合,裡面包含v1.Node,pods,usedPorts等node上的信息;nodeNameToInfo也就是一個node的name到NodeInfo的映射 - nodes []*v1.Node,
//node列表,可用的node集合 - predicateFuncs map[string]algorithm.FitPredicate,
//predicate函數的別名到具體函數的映射,這裡的string類似:PodFitsHostPorts;後面的FitPredicate類型是一個func類型:type FitPredicate func(pod *v1.Pod, meta PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []PredicateFailureReason, error);這個函數類型判斷一個pod能否跑在一個node上 - extenders []algorithm.SchedulerExtender,
//SchedulerExtender是一個介面類型,表示的是一個外部的處理過程,主要用於某些資源不是直接由k8s管理的場景下,調度決策需要外部介入時調用 - metadataProducer algorithm.PredicateMetadataProducer,
//PredicateMetadataProducer是一個函數類型,入參是pod和nodeNameToInfo,返回值是PredicateMetadata,PredicateMetadata是一個interface類型,這個類型表示predicate metadata支持的所有access操作,包含3個函數:ShallowCopy()/AddPod()/RemovePod();這個interface的實現是struct:predicateMetadata,這個struct包含pod、podPorts、serviceAffinityInUse等屬性 - ecache *EquivalenceCache,
//結構體EquivalenceCache主要包含1:一個以node name為key,AlgorithmCache為value的map;2:一個獲取equivalence pod的函數。AlgorithmCache這個結構體存儲了一個lru.Cache類型的屬性,lru是最近最少使用的意思,groupcache里實現的這個Cache - schedulingQueue SchedulingQueue,
//這個interface保存一個等待被調度的pods隊列,有Add()、Pop()等函數 - alwaysCheckAllPredicates bool,
//是否檢查所有的predicate
咋看你肯定感覺迷糊,略抓狂,這麼多東西咋個理解呢,,,別急,咱再看一下一個關鍵類型,然後靜下心來往後看完,再回過頭看是不是理解了這裡的所有參數:
1、上面的FitPredicate類型源碼里解釋如下:
// FitPredicate is a function that indicates(標示) if a pod fits into an existing node. The failure information is given by the error.入參有3個,分別是:
- pod *v1.Pod
- meta PredicateMetadata
- nodeInfo *schedulercache.NodeInfo
返回值是:
- bool
- []PredicateFailureReason
- error
也就是說給定一個pod和一個node,這個函數需要判斷這個pod能否跑在這個node上,能否體現在返回值bool類型上;然後如果失敗了,也就是不能的情況,需要返回PredicateFailureReason集合,也就是失敗的原因們。這個PredicateFailureReason是個interface,看一眼定義就很清晰了,特別簡單:

ok,我們接著看findNodesThatFit函數的返回值:
1.[]*v1.Node,
2.FailedPredicateMap,
//這個返回值是map[string][]algorithm.PredicateFailureReason類型,這個類型就是上面截圖中那個
3.error
到這裡我們可以初步判斷findNodesThatFit函數的輸入是一個pod和一堆nodes和xxx,返回值是可以跑這個pod的node集合和xxx,xxx先不考慮,我們專註一下這裡的一個pod和N個node,返回值是M個node,M<=N.
這個函數的邏輯並不複雜,我們撇開裡面主要的子函數podFitsOnNode後過程大致如下圖:
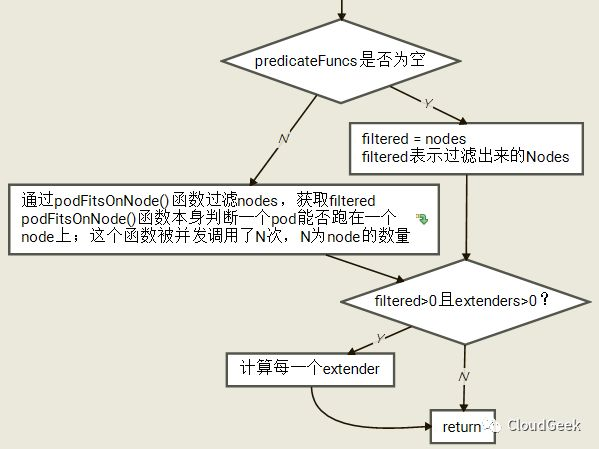
這裡我們稍微看一下這裡的checkNode函數是怎麼被併發調用的:
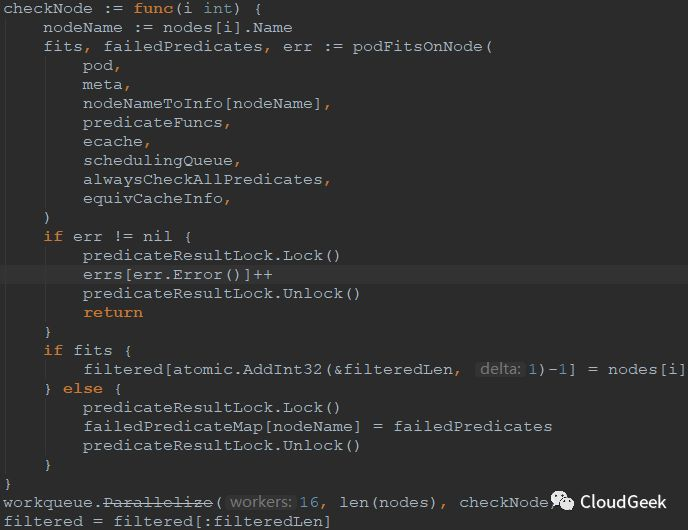
如上圖,checkNode是一個函數類型,明顯predicateFuncs都在這個內嵌函數中執行了。這個內嵌函數的調用在截圖的倒數第二行:workqueue.Parallelize(16, len(nodes), checkNode);這個函數的入參是16,nodes的數量,checkNode這個函數,跟進去看一下可以知道這裡的邏輯,不複雜不過挺有意思:
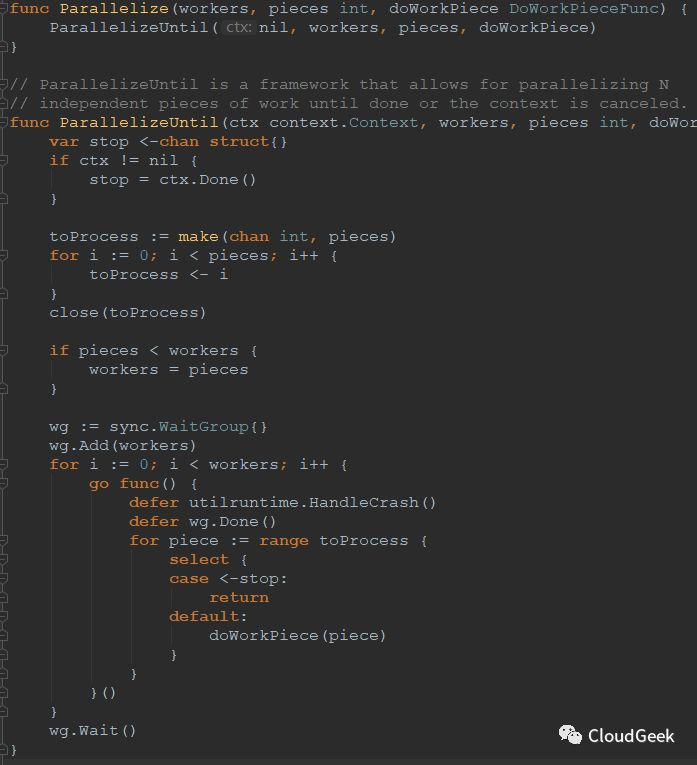
上面的workers是16,pieces是node數量,doWorkPiece就是checkNode這個函數,這個函數的參數還記得嗎?是一個int類型的i;ParallelizeUntil這個函數中寫入了pieces個數據到toProcess,也就是node的數量,然後就close掉了這個channal,也就是這個channal被讀完就廢了。然後判斷如果node數量少於workers,也就是少於16的話,則workers=16;最後開了workers個goroutines, 也就是最多16個併發來消費toProcess,也就是最多16個併發來計算N個checkNode任務,每個checkNode任務處理一個node上的predicate functions計算過程。
好,下麵看podFitsOnNode了,先略看函數聲明:
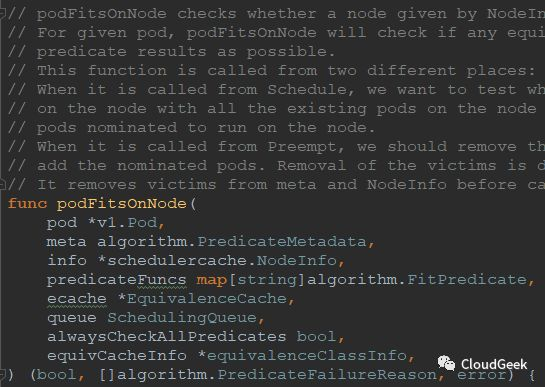
可以看到這裡的註釋不少,大致翻譯過來是這個意思:podFitsOnNode檢查一個以NodeInfo形式提供的node是否能夠通過給定的predicate functions篩選;對於一個給定的pod,podFitsOnNode會檢查node上是否有已經存在的等價的pod,如果存在則嘗試儘量重用這個pod緩存的predicate結果信息。這個函數會從2個不同的入口被調用:Schedule and Preempt,當從Schedule進入時,本函數檢測一個node在考慮所有已存在pods和被指定將跑到這個node上是所有更高優先順序或者相同優先順序(和當前要被調度的pod比較)的pod都跑起來的情況下能否跑現在這個被調度的pod.;;;就解釋到這裡,下麵我們還是老規矩,看看入參和返回值:
入參:
- pod *v1.Pod,
- meta algorithm.PredicateMetadata,
- info *schedulercache.NodeInfo,
//上一個函數的nodeNameToInfo[nodeName]獲取到的NodeInfo
- predicateFuncs map[string]algorithm.FitPredicate,
- ecache *EquivalenceCache,
- queue SchedulingQueue,
- alwaysCheckAllPredicates bool,
- equivCacheInfo *equivalenceClassInfo,
返回值:
- bool,
- []algorithm.PredicateFailureReason,
//上層函數返回值中的FailedPredicateMap是map[string][]algorithm.PredicateFailureReason類型
- error
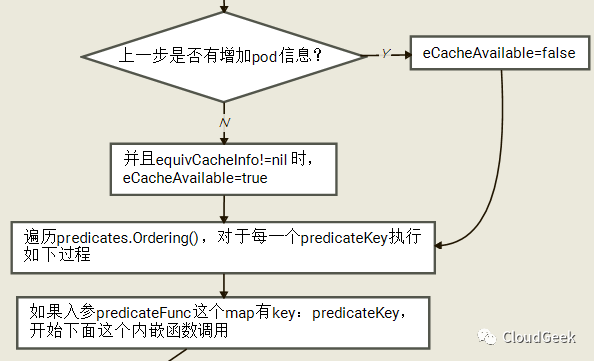
這裡沒有逐個解釋,基本和上層函數的參數對應得上,findNodesThatFit解釋哪些nodes能夠跑給定的pod,而podFitsOnNode解釋給定node能否跑給定pod.我們先看一下這個過程的簡要流程圖(2次迴圈考慮第一次的情況):

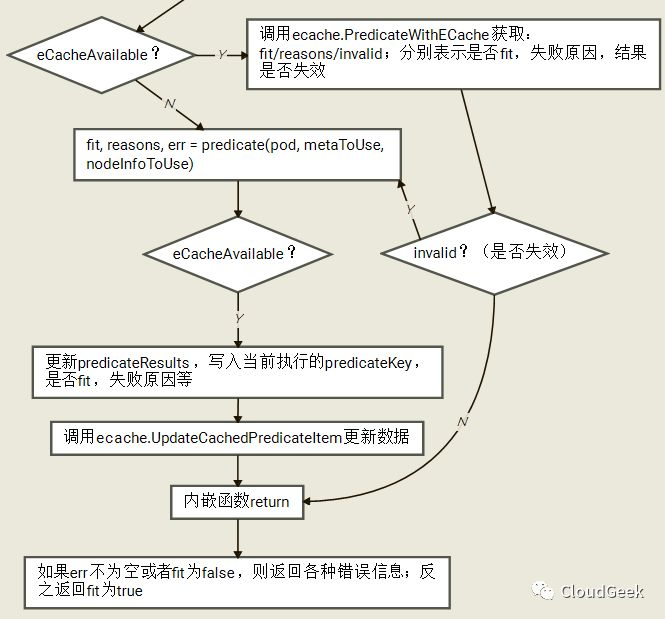
看一下代碼:predicateResults := make(map[string]HostPredicate)這一行的string標識predicate名稱,HostPredicate類型是:
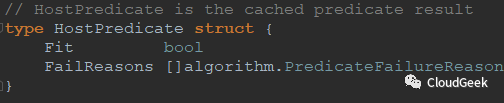
這個i從0到1只跑2遍的for迴圈中分歧點只有如下這個if:
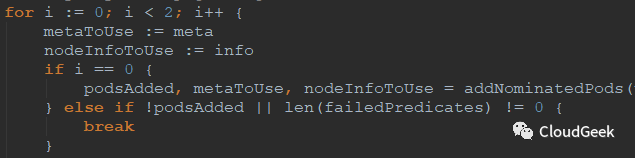
如上,在i為0時調用到了addNominatedPods函數,這個函數把更高或者相同優先順序的pod(待運行到本node上的)信息增加到meta和nodeInfo中,也就是對應考慮這些nominated都Running的場景;後面i為1對應的就是不考慮這些pod的場景。對於這個2遍過程,註釋里是這樣解釋的:
如果這個node上“指定”了更高或者相等優先順序的pods(也就是優先順序不低於本pod的一群pods將要跑在這個node上),我們運行predicates過程當這些pods信息全被加到meta和nodeInfo中的情況。如果所有的predicates過程成功了,我們再次運行這些predicates過程在這些pods信息沒有被加到meta和nodeInfo的情況。這樣第二次過程可能會因為一些pod間的親和性策略過不了(因為這些計劃要跑的pods沒有跑,所以可能親和性被破壞)。這裡其實基於2點考慮:1、有親和性要求的pod如果認為這些nominated pods在,則在這些nominated pods不在的情況下會異常;2、有反親和性要求的pod如果認為這些nominated pods不在,則在這些nominated pods在的情況下會異常。
我們接著看predicate函數主要是怎樣被調用的:
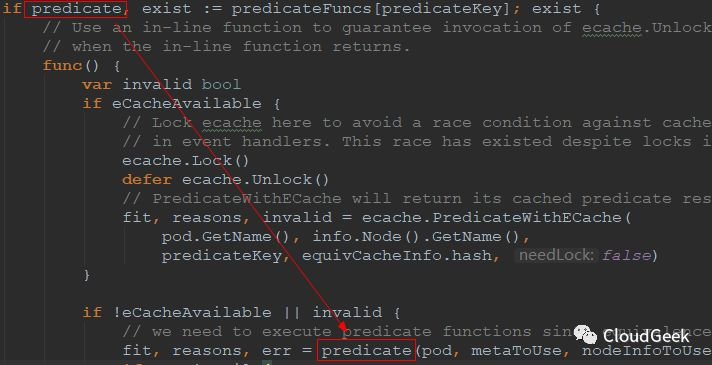
如上,predicate是FitPredicate類型的一個對象,也就是對應具體的predicate函數,所以下麵的predicate(pod, metaToUse, nodeInfoToUse)也就對應一個具體的predicate函數的執行。
最後我們瞄一眼具體的predicate函數是怎麼定義的:
一個predicate函數類似這樣:
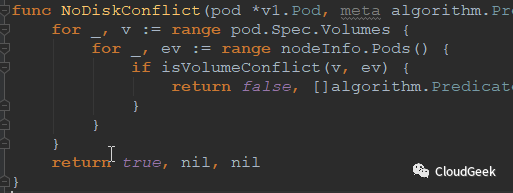
這樣被註冊:

紫色部分的常量對應一個個字元串描述:
行,剩下的我們下回分解~