
1.進程同步/串列(鎖) 進程之間數據不共用,但共用同一套文件系統,所以訪問同一個文件,或同一個列印終端,沒有問題,但共用帶來的是競爭容易錯亂,如搶票時。這就需讓進程一個個的進去保證數據安全,也就是加鎖處理,Lock 併發,效率高,但是競爭同一個文件時,導致數據混亂 加鎖,由併發改成了串列,犧牲了運 ...
1.進程同步/串列(鎖)
進程之間數據不共用,但共用同一套文件系統,所以訪問同一個文件,或同一個列印終端,沒有問題,但共用帶來的是競爭容易錯亂,如搶票時。這就需讓進程一個個的進去保證數據安全,也就是加鎖處理,Lock
併發,效率高,但是競爭同一個文件時,導致數據混亂
加鎖,由併發改成了串列,犧牲了運行效率,但避免數據競爭
以模擬搶票為例:


1 # 註意:首先在當前文件目錄下創建一個名為db的文件 2 # 文件db的內容為:{"count":1},只有這一行數據,並且註意,每次運行完了之後,文件中的1變成了0,你需要手動將0改為1,然後在去運行代碼。 3 # 註意一定要用雙引號,不然json無法識別 4 # 加鎖保證數據安全,不出現混亂 5 from multiprocessing import Process,Lock 6 import time,json,random 7 8 9 # 查看剩餘票數 10 def search(i): 11 dic=json.load(open('db')) # 打開文件,直接load文件中的內容,拿到文件中的包含剩餘票數的字典 12 print('客戶%s查看剩餘票數%s' %(i,dic['count'])) 13 14 15 # 搶票 16 def get(i): 17 dic = json.load(open('db')) 18 time.sleep(0.1) # 模擬讀數據的網路延遲,那麼進程之間的切換,所有人拿到的字典都是{"count": 1},也就是每個人都拿到了這一票。 19 if dic['count'] > 0: 20 dic['count'] -= 1 21 time.sleep(random.randint(0,1)) # 模擬寫數據的網路延遲 22 json.dump(dic,open('db','w')) 23 # 若不加限制最終導致,每個人顯示都搶到了票,這就出現了問題 24 print('客戶%s購票成功'%i) 25 else: 26 print('sorry,客戶%s 沒票了親!'%i) 27 28 29 def task(i,lock): 30 search(i) 31 # 搶票時是發生數據變化的時候,所以我們將鎖加到這裡,讓進程串列執行 32 lock.acquire() # 加鎖 33 get(i) 34 lock.release() # 解鎖 35 36 37 if __name__ == '__main__': 38 lock = Lock() # 創建一個鎖 39 for i in range(10): # 模擬併發10個客戶端搶票 40 p = Process(target=task,args=(i,lock,)) # 將鎖作為參數傳給task函數 41 p.start()加鎖模擬搶票
總結:
加鎖可以保證多個進程修改同一塊數據時,同一時間只能有一個任務可以進行修改,即串列的修改,速度是慢了,但犧牲了速度卻保證了數據安全。
因此需一種解決方案能夠兼顧:1、效率高(多個進程共用一塊記憶體的數據)2、幫我們處理好鎖問題。這就是 mutiprocessing 模塊提供的基於消息的IPC通信機制:隊列和管道(見後續)。
2.進程守護
子進程是不會隨著主進程結束而結束,子進程全部執行完後,程式才結束,那如果需求主進程結束,子進程必須跟著結束,怎麼辦?這就需要用到守護進程了!
運用:如,系統關機,其他一切都要跟著結束
1 import time 2 from multiprocessing import Process 3 4 def func1(m): 5 time.sleep(1) 6 print('我是func1',m) 7 8 9 # 註意:進程之間是互相獨立的,主進程代碼運行結束,不管有沒有運行完,守護進程隨即終止 10 if __name__ == '__main__': 11 p = Process(target=func1,args=(666,)) 12 p.daemon = True # 守護進程,在start之前 13 p.start() 14 15 print('主進程執行結束')
總結:
其一:守護進程會在主進程代碼執行結束後就終止
其二:守護進程內無法再開啟子進程,否則出異常
3.隊列
進程之間互相隔離,要實現進程間通信(IPC),multiprocessing模塊支持 隊列和管道,這兩種方式都是使用消息傳遞隊列就像一個特殊的列表,但是可以設置固定長度,並且從前面插入數據,從後面取出數據,先進先出,取出就沒有這個數據了。
方法介紹:
1 ''' 2 q = Queue([maxsize]) 3 創建共用的進程隊列。maxsize是隊列中允許的最大項數。如果省略此參數,則無大小限制。底層隊列使用管道和鎖定實現。另外,還需要運行支持線程以便隊列中的數據傳輸到底層管道中。 4 Queue的實例q具有以下方法: 5 6 q.get( [ block [ ,timeout ] ] ) 7 返回q中的一個項目。如果q為空,此方法將阻塞,直到隊列中有項目可用為止。block用於控制阻塞行為,預設為True. 如果設置為False,將引發Queue.Empty異常(定義在Queue模塊中)。timeout是可選超時時間,用在阻塞模式中。如果在制定的時間間隔內沒有項目變為可用,將引發Queue.Empty異常。 8 9 q.get_nowait( ) 10 同q.get(False)方法。 11 12 q.put(item [, block [,timeout ] ] ) 13 將item放入隊列。如果隊列已滿,此方法將阻塞至有空間可用為止。block控制阻塞行為,預設為True。如果設置為False,將引發Queue.Empty異常(定義在Queue庫模塊中)。timeout指定在阻塞模式中等待可用空間的時間長短。超時後將引發Queue.Full異常。 14 15 q.qsize() 16 返回隊列中目前項目的正確數量。此函數的結果並不可靠,因為在返回結果和在稍後程式中使用結果之間,隊列中可能添加或刪除了項目。在某些系統上,此方法可能引發NotImplementedError異常。 17 18 19 q.empty() 20 如果調用此方法時 q為空,返回True。如果其他進程或線程正在往隊列中添加項目,結果是不可靠的。也就是說,在返回和使用結果之間,隊列中可能已經加入新的項目。 21 22 q.full() 23 如果q已滿,返回為True. 由於線程的存在,結果也可能是不可靠的(參考q.empty()方法) 24 25 '''
示例代碼:
1 from multiprocessing import Process,Queue 2 # Queue 先進先出 fifo first in first out,隊列裡面的數據,只能取一次,取出就沒了 3 4 q = Queue(3) # Queue(參數)可理解成一個可限制長度(參數)的列表 5 # 添加數據 6 # print(q.full()) 7 q.put(4) 8 q.put(3) 9 q.put(2) 10 # print(q.full()) # 查看序列是否滿了,但不可信的(如多進程時) 11 12 # 取出數據 13 print('---------') 14 # print(q.empty()) 15 print(q.get()) 16 print(q.get()) 17 print(q.get()) 18 # print(q.empty()) # 查看序列是否空了,但是不可信的(如多進程時) 19 print('---------') 20 print(q.get()) # 超出長度會一直停在這等待,直到有數據給他 21 22 # 用try優化上面代碼 23 # for i in range(4): 24 # try: 25 # s = q.get_nowait() 26 # # s = q.get(False) # 等同nowait 27 # print('=====',s) 28 # 29 # except: 30 # print('沒有數據了,去乾別的吧...') 31 #隊列參考代碼
基於隊列的進程通信:
1 from multiprocessing import Process,Queue 2 3 4 def func(q): 5 # 拿出數據 6 res = q.get() 7 print(res) 8 print(q.get()) 9 10 11 if __name__ == '__main__': 12 q = Queue(5) 13 q.put('hello') # 添加數據 14 q.put('emmm') 15 p = Process(target=func,args=(q,)) 16 p.start() 17 18 print('主進程結束') 19 20 # 隊列的數據是安全的,先進先出,且取一次出來就沒有了View Code
4.生產消費模式
線上程世界里,生產者就是生產數據的線程,消費者就是消費數據的線程。在多線程開發當中,如果生產者處理速度很快,而消費者處理速度很慢,那麼生產者就必須等待消費者處理完,才能繼續生產數據。同樣的道理,如果消費者的處理能力大於生產者,那麼消費者就必須等待生產者。為瞭解決這個問題我們需要通過一個容器(緩衝區)來解決生產者和消費者的強耦合問題。
生產消費模式圖解:
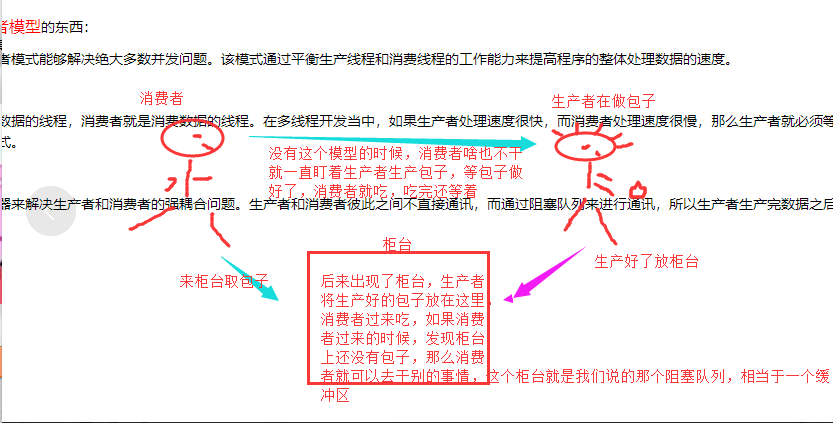
基於隊列來實現一個生產者消費者模型:
1 # 解耦合 2 import time 3 from multiprocessing import Process,Queue 4 5 6 def producer(q): 7 for i in range(10): 8 time.sleep(0.5) 9 q.put('包子%s號'%i) 10 print('包子%s號做好了'%i) 11 q.put(None) # None表示沒有 防止後面死迴圈 12 13 14 def consumer(q): 15 while 1: 16 baozi = q.get() 17 if baozi == None: 18 break 19 time.sleep(1) 20 print('%s被吃掉了'%baozi) 21 22 23 if __name__ == '__main__': 24 q = Queue(10) # 創建一個隊列,耦合生產者和消費者,p1和p2共用q(獨立於進程的一個空間) 25 p1 = Process(target=producer,args=(q,)) 26 p2 = Process(target=consumer,args=(q,)) 27 p1.start() 28 p2.start()View Code
總結:
1 # 生產者消費者模型總結 2 3 # 程式中有兩類角色 4 一類負責生產數據(生產者) 5 一類負責處理數據(消費者) 6 7 # 引入生產者消費者模型為瞭解決的問題是: 8 平衡生產者與消費者之間的工作能力,從而提高程式整體處理數據的速度 9 10 # 如何實現: 11 生產者 < -->隊列 <—— > 消費者 12 # 生產者消費者模型實現類程式的解耦和 13 14 生產者消費者模型總結
5.joinableQueue
有多個生產者和多個消費者時,由於隊列是進程安全的,一個進程拿走了結束信號,另外一個進程就拿不到了,所以使用時需要消費者發送消息給生產者已使用。
1 #JoinableQueue([maxsize]):這就像是一個Queue對象,但隊列允許項目的使用者通知生成者項目已經被成功處理。通知進程是使用共用的信號和條件變數來實現的。 2 3 #參數介紹: 4 maxsize是隊列中允許最大項數,省略則無大小限制。 5 #方法介紹: 6 JoinableQueue的實例p除了與Queue對象相同的方法之外還具有: 7 q.task_done():使用者使用此方法發出信號,表示q.get()的返回項目已經被處理。如果調用此方法的次數大於從隊列中刪除項目的數量,將引發ValueError異常 8 q.join():生產者調用此方法進行阻塞,直到隊列中所有的項目均被處理。阻塞將持續到隊列中的每個項目均調用q.task_done()方法為止,也就是隊列中的數據全部被get拿走了。
1 import time 2 from multiprocessing import Process,JoinableQueue 3 4 def producer(q): 5 for i in range(10): 6 time.sleep(0.5) 7 q.put('包子%s號'%i) 8 print('包子%s號生產完畢'%i) 9 print('aaaaaaaaaaaaa') 10 q.join() # 11 print('包子賣完了') 12 13 def consumer(q): 14 while 1: 15 baozi = q.get() 16 time.sleep(0.8) 17 print('%s被吃掉了'%baozi) 18 q.task_done() # 給隊列發送一個任務處理完了的信號 19 20 if __name__ == '__main__': 21 22 q = JoinableQueue() 23 p1 = Process(target=producer,args=(q,)) 24 p2 = Process(target=consumer,args=(q,)) 25 p2.daemon = True 26 p1.start() 27 p2.start() 28 p1.join() # 主進程等著生產者進程的結束才結束 ,生產者結束意味著q獲得了10個task_done的信號,簡單示例
1 # 與queque類似,多了 q.task_done() q.join() 2 from multiprocessing import Process,JoinableQueue 3 import time,random,os 4 5 6 def consumer(q): 7 while True: 8 res=q.get() 9 # time.sleep(random.randint(1,3)) 10 time.sleep(random.random()) 11 print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) 12 q.task_done() # 向q.join()發送一次信號,證明一個數據已經被取走並執行完了 13 14 15 def producer(name,q): 16 for i in range(10): 17 # time.sleep(random.randint(1,3)) 18 time.sleep(random.random()) 19 res='%s%s' %(name,i) 20 q.put(res) 21 print('\033[44m%s 生產了 %s\033[0m' %(os.getpid(),res)) 22 print('%s生產結束'%name) 23 q.join() # 生產完畢,使用此方法進行阻塞,直到隊列中所有項目均被處理。 24 print('%s生產結束~~~~~~'%name) 25 26 27 if __name__ == '__main__': 28 q=JoinableQueue() 29 # 生產者們:即廚師們 30 p1=Process(target=producer,args=('包子',q)) 31 p2=Process(target=producer,args=('骨頭',q)) 32 p3=Process(target=producer,args=('泔水',q)) 33 34 # 消費者們:即吃貨們 35 c1=Process(target=consumer,args=(q,)) 36 c2=Process(target=consumer,args=(q,)) 37 c1.daemon=True 38 c2.daemon=True 39 # 如果不加守護,那麼主進程結束不了,但是加了守護之後,必須確保生產者的內容生產完並且被處理完了,所有必須還要在主進程給生產者設置join,才能確保生產者生產的任務被執行完了,並且能夠確保守護進程在所有任務執行完成之後才隨著主進程的結束而結束。 40 41 # 開始 42 p_l=[p1,p2,p3,c1,c2] 43 for p in p_l: 44 p.start() 45 46 p1.join() # 我要確保你的生產者進程結束了,生產者進程的結束標志著你生產的所有的人任務都已經被處理完了 47 p2.join() 48 p3.join() 49 print('主程式')稍複雜示例參考

