
到目前為止,我們只考慮了實時系統上的調度。事實上, Linux可以做得更好些。除了支持多個CPU之外,內核也提供其他幾種與調度相關的增強功能,在以後幾節里會論述。但請註意,這些增強功能大大增加了調度器的複雜性,因此我主要考慮簡化的情形,目的在於說明實質性的原理,而不考慮所有的邊界情形和調度中出現的奇 ...
到目前為止,我們只考慮了實時系統上的調度。事實上, Linux可以做得更好些。除了支持多個CPU之外,內核也提供其他幾種與調度相關的增強功能,在以後幾節里會論述。但請註意,這些增強功能大大增加了調度器的複雜性,因此我主要考慮簡化的情形,目的在於說明實質性的原理,而不考慮所有的邊界情形和調度中出現的奇異情況。
1. SMP調度
多處理器系統上,內核必須考慮幾個額外的問題,以確保良好的調度。
- CPU負荷必須儘可能公平地在所有的處理器上共用。如果一個處理器負責3個併發的應用程式,而另一個只能處理空閑進程,那是沒有意義的。
- 進程與系統中某些處理器的親合性(affinity)必須是可設置的。例如在4個CPU系統中,可以將計算密集型應用程式綁定到前3個CPU,而剩餘的(互動式)進程則在第4個CPU上運行。
- 內核必須能夠將進程從一個CPU遷移到另一個。但該選項必須謹慎使用,因為它會嚴重危害性能。在小型SMP系統上CPU高速緩存是最大的問題。對於真正大型系統, CPU與遷移進程此前使用的物理記憶體距離可能有若幹米,因此對該進程記憶體的訪問代價高昂。
進程對特定CPU的親合性 ,定義在task_struct的 cpus_allowed 成 員 中 。 Linux 提供了sched_setaffinity系統調用,可修改進程與CPU的現有分配關係。
1.1 數據結構的擴展
在SMP系統上,每個調度器類的調度方法必須增加兩個額外的函數:
<sched.h>
struct sched_class {
...
#ifdef CONFIG_SMP
unsigned long (*load_balance) (struct rq *this_rq, int this_cpu,
struct rq *busiest, unsigned long max_load_move,
struct sched_domain *sd, enum cpu_idle_type idle,
int *all_pinned, int *this_best_prio);
int (*move_one_task) (struct rq *this_rq, int this_cpu,
struct rq *busiest, struct sched_domain *sd,
enum cpu_idle_type idle);
#endif
...
}雖然其名字稱之為load_balance,但這些函數並不直接負責處理負載均衡。每當內核認為有必要重新均衡時,核心調度器代碼都會調用這些函數。特定於調度器類的函數接下來建立一個迭代器,使得核心調度器能夠遍歷所有可能遷移到另一個隊列的備選進程,但各個調度器類的內部結構不能因為迭代器而暴露給核心調度器。 load_balance函數指針採用了一般性的函數load_balance,而move_one_task則使用了iter_move_one_task。這些函數用於不同的目的。
- iter_move_one_task從最忙碌的就緒隊列移出一個進程,遷移到當前CPU的就緒隊列。
- load_balance則允許從最忙的就緒隊列分配多個進程到當前CPU,但移動的負荷不能比max_load_move更多
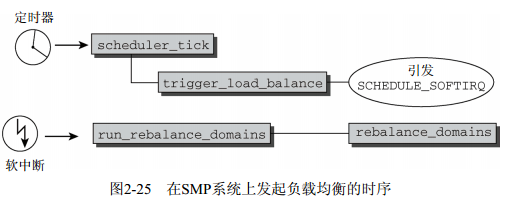
負載均衡處理過程是如何發起的?在SMP系統上,周期性調度器函數scheduler_tick按上文所述完成所有系統都需要的任務之後,會調用trigger_load_balance函數。這會引發SCHEDULE_SOFTIRQ軟中斷softIRQ(硬體中斷的軟體模擬,更多細節請參見第14章),該中斷確保會在適當的時機執行run_rebalance_domains。該函數最終對當前CPU調用rebalance_domains,實現負載均衡。
時序如圖2-25所示。
為執行重新均衡的操作,內核需要更多信息。因此在SMP系統上,就緒隊列增加了額外的欄位:
kernel/sched.c
struct rq {
...
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* 用於主動均衡 */
int active_balance;
int push_cpu;
/*該就緒隊列的CPU: */
int cpu;
struct task_struct *migration_thread;
struct list_head migration_queue;
#endif
...
}就緒隊列是特定於CPU的,因此cpu表示了該就緒隊列所屬的處理器。內核為每個就緒隊列提供了一個遷移線程,可以接收遷移請求,這些請求保存在鏈表migration_queue中。這樣的請求通常發源於調度器自身,但如果進程被限制在某一特定的CPU集合上,而不能在當前執行的CPU上繼續運行時,也可能出現這樣的請求。內核試圖周期性地均衡就緒隊列,但如果對某個就緒隊列效果不佳,則隊必須使用主動均衡(active balancing)。如果需要主動均衡,則將active_balance設置為非零值,而cpu則記錄了從哪個處理器發起的主動均衡請求。
此外,所有的就緒隊列組織為調度域(scheduling domain)。這可以將物理上鄰近或共用高速緩存的CPU群集起來,應優先選擇在這些CPU之間遷移進程。但在“普通”的SMP系統上,所有的處理器都包含在一個調度域中。因此我不會詳細討論該結構,要提的一點是該結構包含了大量參數,可以通過/proc/sys/kernel/cpuX/domainY設置。其中包括了在多長時間之後發起負載均衡(包括最大/最小時間間隔),導致隊列需要重新均衡的最小不平衡值,等等。此外該結構還管理一些欄位,可以在運行時設置,使得內核能夠跟蹤記錄上一次均衡操作在何時執行,下一次將在何時執行。
那麼load_balance做什麼呢?該函數會檢測在上一次重新均衡操作之後是否已經過去了足夠的時間,在必要的情況下通過調用load_balance發起一輪新的重新均衡操作。該函數的代碼流程圖如圖2-26所示。請註意,我在該圖中描述的是一個簡化的版本,因為SMP調度器必須處理大量邊邊角角的情況。如果都畫出來,相關的細節會擾亂圖中真正的實質性操作。

首先該函數必須標識出哪個隊列工作量最大。該任務委托給find_busiest_queue,後者對一個特定的就緒隊列調用。函數迭代所有處理器的隊列(或確切地說,當前調度組中的所有處理器),比較其負荷權重。最忙的隊列就是最後找到的負荷值最大的隊列。
在find_busiest_queue標識出一個非常繁忙的隊列之後,如果至少有一個進程在該隊列上執行(否則負載均衡就沒多大意義),則使用move_tasks將該隊列中適當數目的進程遷移到當前隊列。move_tasks函數接下來會調用特定於調度器類的load_balance方法。
在選擇被遷移的進程時,內核必須確保所述的進程:
- 目前沒有運行或剛結束運行,因為對運行進程而言, CPU高速緩存充滿了進程的數據,遷移該進程則完全抵消了高速緩存帶來的好處;
- 根據其CPU親合性,可以在與當前隊列關聯的處理器上執行。
如果均衡操作失敗(例如,遠程隊列上所有進程都有較高的內核內部優先順序值,即較低的nice值),那麼將喚醒負責最忙的就緒隊列的遷移線程。為確保主動負載均衡執行得比上述方法更積極一點, load_balance會設置最忙的就緒隊列的active_balance標誌,並將發起請求的CPU記錄到rq->cpu。
1.2 遷移線程
遷移線程用於兩個目的。一個是用於完成發自調度器的遷移請求,另外一個是用於實現主動均衡。遷移線程是一個執行migration_thread的內核線程。該函數的代碼流程圖如圖2-27所示。
migration_thread內部是一個無限迴圈,在無事可做時進入睡眠狀態。首先,該函數檢測是否需要主動均衡。如果需要,則調用active_load_balance滿足該請求。該函數試圖從當前就緒隊列移出一個進程,且移至發起主動均衡請求CPU的就緒隊列。它使用move_one_task完成該工作,後者又對所有的調度器類,分別調用特定於調度器類的move_one_task函數,直至其中一個成功。註意,這些函數移動進程時會嘗試比load_balance更激烈的方法。例如,它們不進行此前提到的優先順序比較,因此它們更有可能成功。
完成主動負載均衡之後,遷移線程會檢測migrate_req鏈表中是否有來自調度器的待決遷移請求。如果沒有,則線程發出重調度請求。否則,用__migrate_task完成相關請求,該函數會直接移出所要求的進程,而不再與調度器類進一步交互。
1.3 核心調度器的改變
除了上述增加的特性之外,在SMP系統上還需要對核心調度器的現存方法作一些修改。雖然到處都是一些小的細節變化,與單處理器系統相比最重要的差別如下所示。
- 在用exec系統調用啟動一個新進程時,是調度器跨越CPU移動該進程的一個良好的時機。事實上,該進程尚未執行,因此將其移動到另一個CPU不會帶來對CPU高速緩存的負面效應。exec系統調用會調用掛鉤函數sched_exec,其代碼流程圖如圖2-28所示。sched_balance_self挑選當前負荷最少的CPU(而且進程得允許在該CPU上運行)。如果不是當前CPU,那麼會使用sched_migrate_task,向遷移線程發送一個遷移請求。
- 完全公平調度器的調度粒度與CPU的數目是成比例的。系統中處理器越多,可以採用的調度粒度就越大。 sysctl_sched_min_granularity和sysctl_sched_latency都乘以校正因數1+log2(nr_cpus) , 其 中 nr_cpus 表 示 現 有 的 CPU 的 數 目 。 但 它 們 不 能 超 出 200 毫 秒 。sysctl_sched_wakeup_granularity也需要乘以該因數,但沒有上界。
2. 調度域和控制組
在此前對調度器代碼的討論中,調度器並不直接與進程交互,而是處理可調度實體。這使得可以實現組調度:進程置於不同的組中,調度器首先在這些組之間保證公平,然後在組中的所有進程之間保證公平。舉例來說,這使得可以向每個用戶授予相同的CPU時間份額。在調度器確定每個用戶獲得多長時間之後,確定的時間間隔以公平的方式分配到該用戶的進程。事實上,這意味著一個用戶運行的進程越多,那麼每個進程獲得的CPU份額就越少。但用戶獲得的總時間不受進程數目的影響。
把進程按用戶分組不是唯一可能的做法。內核還提供了控制組(control group),該特性使得通過特殊文件系統cgroups可以創建任意的進程集合,甚至可以分為多個層次。該情形如圖2-29所示。

為反映內核中的此種層次化情形, struct sched_entity增加了一個成員,用以表示這種層次結構:
<sched.h>
struct sched_entity {
...
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
...
#endif
...
}所有調度類相關的操作,都必須考慮到調度實體的這種子結構。舉例來說,考慮一下在完全公平調度器將進程加入就緒隊列的實際代碼:
kernel/sched_fair.c
static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int wakeup)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, wakeup);
wakeup = 1;
}
}for_each_sched_entity會遍歷由sched_entity的parent成員定義的調度層次結構,每個實體都加入到就緒隊列。
請註意, for_each_sched_entity實際上是一個平凡的迴圈。如果未選擇支持組調度,則會退化為只執行一次迴圈體中的代碼,因此又恢復了先前的討論所描述的行為特性。
3. 內核搶占和低延遲相關工作
我們現在把註意力轉向內核搶占,該特性用來為系統提供更平滑的體驗,特別是在多媒體環境下。與此密切相關的是內核進行的低延遲方面的工作,我會稍後討論。
3.1 內核搶占
如上所述,在系統調用後返回用戶狀態之前,或者是內核中某些指定的點上,都會調用調度器。這確保除了一些明確指定的情況之外,內核是無法中斷的,這不同於用戶進程。 如果內核處於相對耗時較長的操作中,比如文件系統或記憶體管理相關的任務,這種行為可能會帶來問題。內核代表特定的進程執行相當長的時間,而其他進程則無法運行。這可能導致系統延遲增加,用戶體驗到“緩慢的”響應。如果多媒體應用長時間無法得到CPU,則可能發生視頻和音頻漏失現象。
在編譯內核時啟用對內核搶占的支持,則可以解決這些問題。如果高優先順序進程有事情需要完成,那麼在啟用內核搶占的情況下,不僅用戶空間應用程式可以被中斷,內核也可以被中斷。切記,內核搶占和用戶層進程被其他進程搶占是兩個不同的概念!
內核搶占是在內核版本2.5開發期間增加的。儘管使內核可搶占所需的改動非常少,但該機制不像搶占用戶空間進程那樣容易實現。如果內核無法一次性完成某些操作(例如,對數據結構的操作),那麼可能出現競態條件而使得系統不一致。在多處理器系統上出現的同樣的問題會在第5章論述。
因此內核不能在任意點上被中斷。幸運的是,大多數不能中斷的點已經被SMP實現標識出來了,並且在實現內核搶占時可以重用這些信息。內核的某些易於出現問題的部分每次只能由一個處理器訪問,這些部分使用所謂的自旋鎖保護:到達危險區域(亦稱之為臨界區)的第一個處理器會獲得鎖,在離開該區域時釋放該鎖。另一個想要訪問該區域的處理器在此期間必須等待,直到第一個處理器釋放鎖為止。只有此時它才能獲得鎖併進入臨界區。
如果內核可以被搶占,即使單處理器系統也會像是SMP系統。考慮正在臨界區內部工作的內核被搶占的情形。下一個進程也在核心態操作,湊巧也想要訪問同一個臨界區。這實際上等價於兩個處理器在臨界區中工作,我們必須防止這種情形。每次內核進入臨界區時,我們必須停用內核搶占。
內核如何跟蹤它是否能夠被搶占?回想一下,可知系統中的每個進程都有一個特定於體繫結構的struct thread_info實例。該結構也包含了一個搶占計數器(preemption counter):
<asm-arch/thread_info.h>
struct thread_info {
...
int preempt_count; /* 0 => 可搶占, <0 => BUG */
...
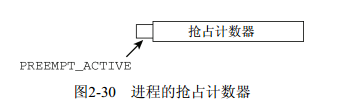
}在調用調度器之前,搶占計數器的值設置為PREEMPT_ACTIVE。這設置了搶占計數器中的一個標誌位,使之有一個很大的值,這樣就不受普通的搶占計數器加1操作的影響了,如圖2-30所示。它向schedule函數表明,調度不是以普通方式引發的,而是由於內核搶占。在內核重調度之後,代碼流程回到當前進程。此時標誌位已經再次移除,這可能是在一段時間之後,此間的這段時間供搶先的進程執行。
此前我忽略了該標誌與schedule的關係,因此必須在這裡討論。我們知道,如果進程目前不處於可運行狀態,則調度器會用deactivate_task停止其活動。實際上,如果調度是由搶占機制發起的(查看搶占計數器中是否設置了PREEMPT_ACTIVE),則會跳過該操作:
kernel/sched.c
asmlinkage void __sched schedule(void) {
...
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely((prev->state & TASK_INTERRUPTIBLE) &&unlikely(signal_pending(prev)))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, 1);
}
}
...
}這確保了儘可能快速地選擇下一個進程,而無需停止當前進程的活動。如果一個高優先順序進程在等待調度,則調度器類將會選擇該進程,使其運行。
該方法只是觸發內核搶占的一種方法。另一種激活搶占的可能方法是在處理了一個硬體中斷請求之後。如果處理器在處理中斷請求後返回核心態(返回用戶狀態則沒有影響),特定於體繫結構的彙編常式會檢查搶占計數器值是否為0,即是否允許搶占,以及是否設置了重調度標誌,類似於preempt_schedule的處理。如果兩個條件都滿足,則調用調度器,這一次是通過preempt_schedule_irq,表明搶占請求發自中斷上下文。該函數和preempt_schedule之間的本質區別是, preempt_schedule_irq調用時停用了中斷,防止中斷造成遞歸調用。
根據本節講述的方法可知,啟用了搶占特性的內核能夠比普通內核更快速地用緊急進程替代當前進程。
3.2 低延遲
當然,即使沒有啟用內核搶占,內核也很關註提供良好的延遲時間。例如,這對於網路伺服器是很重要的。儘管此類環境不需要內核搶占引入的開銷,但內核仍然應該以合理的速度響應重要的事件。例如,如果一網路請求到達,需要守護進程處理,那麼該請求不應該被執行繁重IO操作的資料庫過度延遲。我已經討論了內核提供的一些用於緩解該問題的措施: CFS和內核搶占中的調度延遲。第5章中將討論的實時互斥量也有助於解決該問題,但還有一個與調度有關的操作能夠對此有所幫助。
基本上,內核中耗時長的操作不應該完全占據整個系統。相反,它們應該不時地檢測是否有另一個進程變為可運行,併在必要的情況下調用調度器選擇相應的進程運行。該機制不依賴於內核搶占,即使內核連編時未指定支持搶占,也能夠降低延遲。
發起有條件重調度的函數是cond_resched。其實現如下:
kernel/sched.c
int __sched cond_resched(void)
{
if (need_resched() && !(preempt_count() & PREEMPT_ACTIVE))
__cond_resched();
return 1;
}
return 0;
}need_resched檢查是否設置了TIF_NEED_RESCHED標誌,代碼另外還保證內核當前沒有被搶占①,因此允許重調度。只要兩個條件滿足,那麼__cond_resched會處理必要的細節並調用調度器。
如何使用cond_resched?舉例來說,考慮內核讀取與給定記憶體映射關聯的記憶體頁的情況。這可以通過無限迴圈完成,直至所有需要的數據讀取完畢:
for (;;)
/* 讀入數據 */
if (exit_condition)
continue;如果需要大量的讀取操作,可能耗時會很長。由於進程運行在內核空間中,調度器無法象在用戶空間那樣撤銷其CPU,假定也沒有啟用內核搶占。通過在每個迴圈迭代中調用cond_resched,即可改進此種情況
for (;;)
cond_resched();
/* 讀入數據 */
if (exit_condition)
continue;內核代碼已經仔細核查過,以找出長時間運行的函數,併在適當之處插入對cond_resched的調用。即使沒有顯式內核搶占,這也能夠保證較高的響應速度。
遵循長期以來的UNIX內核傳統, Linux的進程狀態也支持可中斷的和不可中斷的睡眠。但在2.6.25的開發周期中,又添加了另一個狀態: TASK_KILLABLE。 ①處於此狀態進程正在睡眠,不響應非致命信號,但可以被致命信號殺死,這剛好與TASK_UNINTERRUPTIBLE相反。在撰寫本書時,內核中適用於TASK_KILLABLE睡眠之處,都還沒有修改。
在內核2.6.25和2.6.26開發期間,調度器的清理相對而言是比較多的。 在這期間增加的一個新特性是實時組調度。這意味著,通過本章介紹的組調度框架,現在也可以處理實時進程了。
另外,調度器相關的文檔移到了一個專用目錄Documentation/scheduler/下,舊的O(1)調度器的相關文檔都已經過時,因而刪除了。有關實時組調度的文檔可以參考Documentation/scheduler/sched-rt-group.txt。


