
@[toc] Hadoop所用安裝包和配置文件等我找到最方便使用的方式再上傳到博客,如果有需要也歡迎找我分享。 這篇博客是建立在我另一篇博客的基礎上,建議先瀏覽博文 "大數據入門第一篇:maven項目的搭建" 在windows下, 1.導包Hadoop包 我用的是破解版的文件,不需要安裝,直接解壓到 ...
目錄
- 1.導包Hadoop包
- 2.配置環境變數
- 3.把winutil包拷貝到Hadoop bin目錄下
- 4.把Hadoop.dll放到system32下
- 5.檢測Hadoop是否正常安裝
- 6.容易出現的錯誤:
@
Hadoop所用安裝包和配置文件等我找到最方便使用的方式再上傳到博客,如果有需要也歡迎找我分享。
- 這篇博客是建立在我另一篇博客的基礎上,建議先瀏覽博文
大數據入門第一篇:maven項目的搭建
在windows下,
1.導包Hadoop包
我用的是破解版的文件,不需要安裝,直接解壓到D盤下

2.配置環境變數
- 接下來配置環境變數,相信配置過jdk的同學們對這一步應該不算陌生。
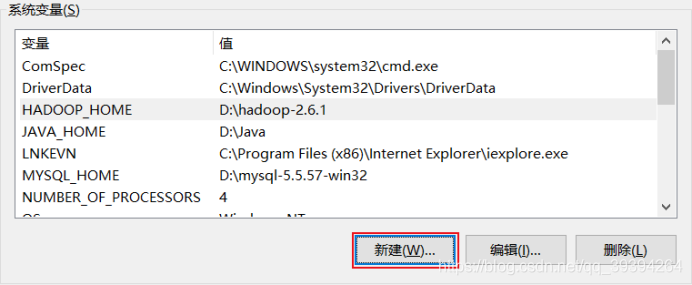
我的電腦——>屬性——>高級系統設置——>環境變數——>系統變數——>編輯Path,增加 %HADOOP_HOME%\bin ——>新建一個變數名為 HADOOP_HOME,變數值為 hadoop安裝路徑的系統變數——>確定操作——>完成
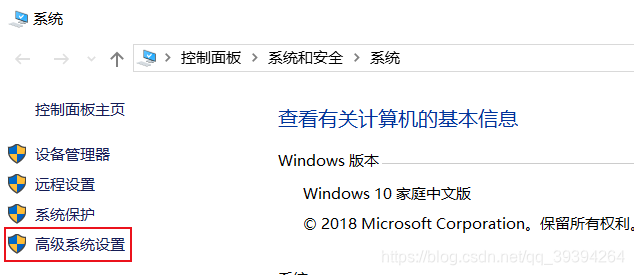
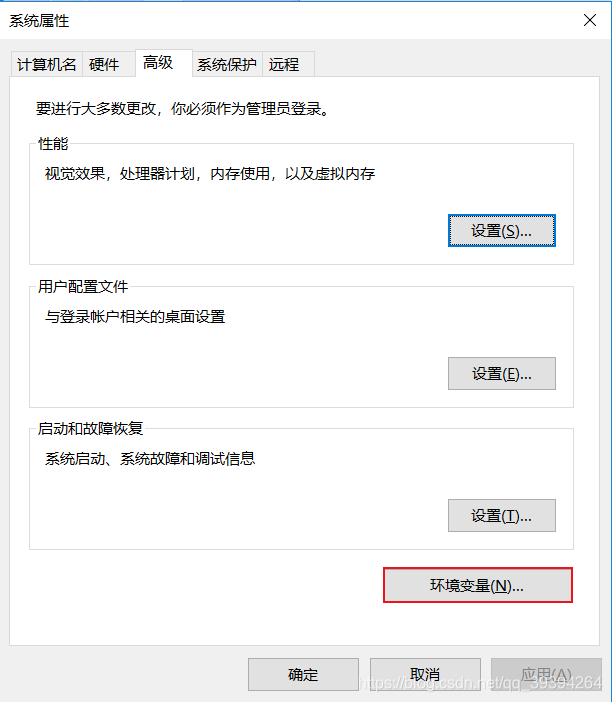
找到系統變數,編輯Path
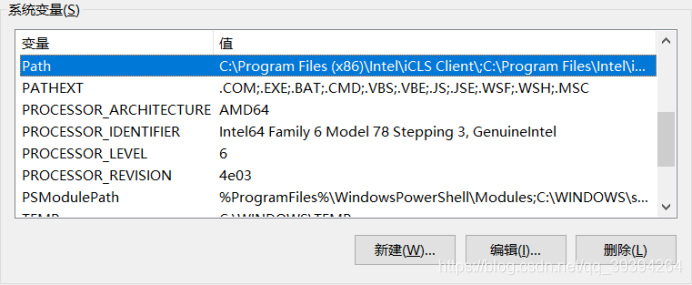
加上 %HADOOP_HOME%\bin即可
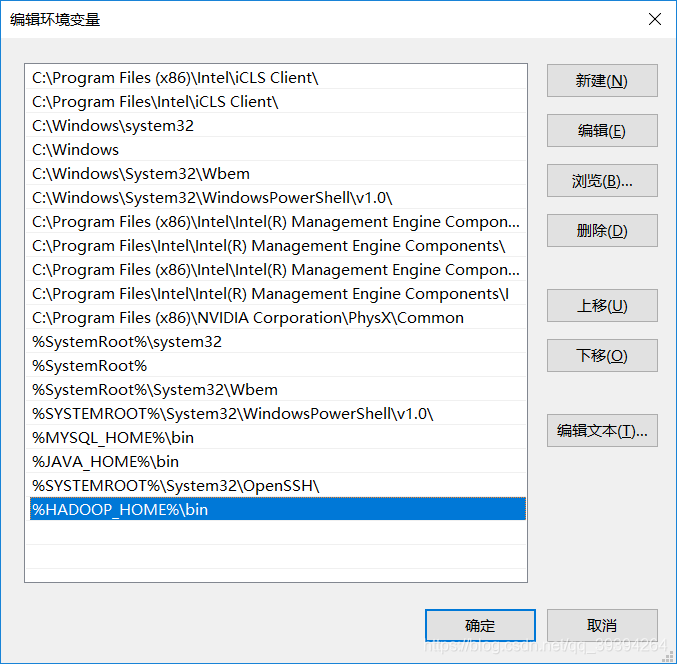
確定之後,新建一個系統變數
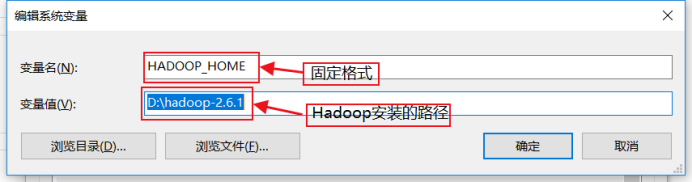
然後依次確定剛纔的操作,配置環境變數工作完成。
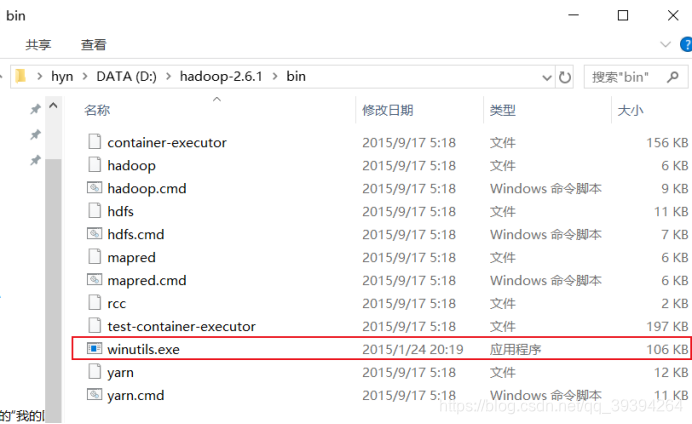
3.把winutil包拷貝到Hadoop bin目錄下
4.把Hadoop.dll放到system32下
路徑:C:\Windows\System32

5.檢測Hadoop是否正常安裝
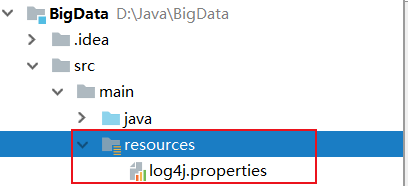
5.1在maven項目中檢測,將配置文件放入resource包下
5.2然後通過一個簡單的wordcount程式檢測Hadoop是否安裝成功
先在本地電腦寫一個txt文件,內容隨便輸入,
如:

5.3保存好之後,寫程式:
(檢測這裡將程式複製過去就可以,先不用理解,後續學習)
package com.oracle.demo.mr;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCount {
public class WcMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(" ");
for (String s:strs){
Text outkey = new Text(s);
IntWritable outvalue = new IntWritable(1);
context.write(outkey,outvalue);
}
}
}
public class WcReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable n:values){
count += n.get();
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapperClass(com.oracle.demo.mr.WcMapper.class);
job.setReducerClass(com.oracle.demo.mr.WcReduce.class);
FileInputFormat.setInputPaths(job,new Path("E:\\BigData\\input.txt"));
FileOutputFormat.setOutputPath(job,new Path("E:\\BigData\\output"));
job.waitForCompletion(true);
}
}註意:

運行之後控制台顯示:
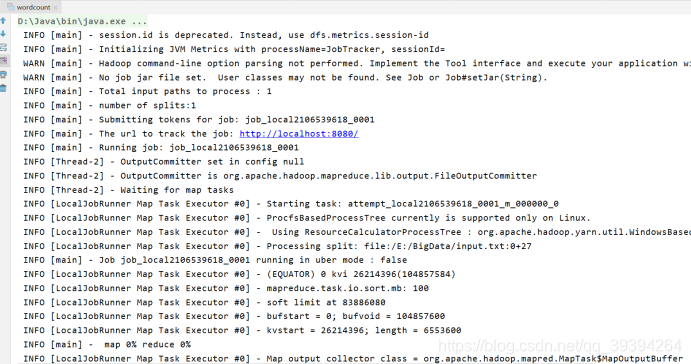
。。。
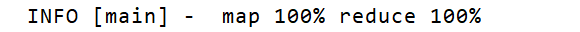
。。。

表示運行成功,沒有錯誤
5.4最後我們打開輸出文件查看:
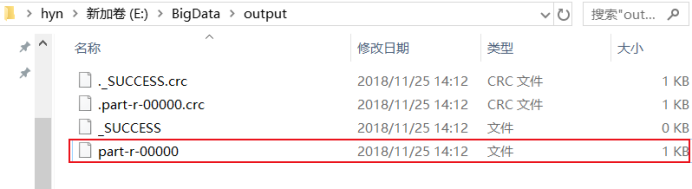
結果是:
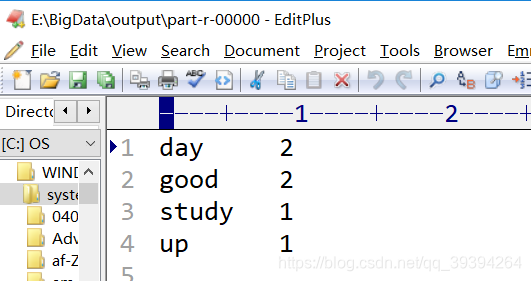
此刻,表示Hadoop安裝成功,大功告成了。
6.容易出現的錯誤:
6.1.導包錯誤
6.2.輸出文件存在
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/E:/BigData/output already exists
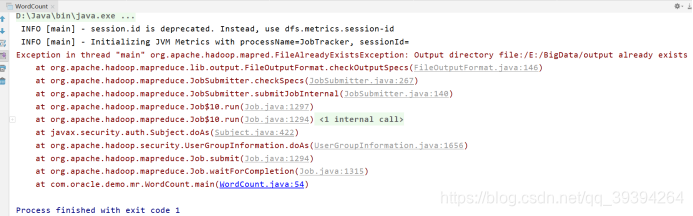
如何解決:之前運行的輸出文件刪除即可。
6.3.環境搭建或配置等錯誤

這篇博客是我自己安裝完之後寫出來的,如果過程中有什麼疏漏或者疑問,歡迎和我交流。安裝過程中也許會遇到一些自己解決不了的錯誤,不要急躁,慢慢找方法解決就好了,希望你能成為一個優秀的程式員。

