
1 記憶體管理域zone 為了支持NUMA模型,也即CPU對不同記憶體單元的訪問時間可能不同,此時系統的物理記憶體被劃分為幾個節點(node), 一個node對應一個記憶體簇bank,即每個記憶體簇被認為是一個節點 首先, 記憶體被劃分為結點. 每個節點關聯到系統中的一個處理器, 內核中表示為 的實例. 系統中 ...
1 記憶體管理域zone
為了支持NUMA模型,也即CPU對不同記憶體單元的訪問時間可能不同,此時系統的物理記憶體被劃分為幾個節點(node), 一個node對應一個記憶體簇bank,即每個記憶體簇被認為是一個節點
- 首先, 記憶體被劃分為結點. 每個節點關聯到系統中的一個處理器, 內核中表示為
pg_data_t的實例. 系統中每個節點被鏈接到一個以NULL結尾的pgdat_list鏈表中,而其中的每個節點利用pg_data_tnode_next欄位鏈接到下一節.而對於PC這種UMA結構的機器來說, 只使用了一個成為contig_page_data的靜態pg_data_t結構. - 接著各個節點又被劃分為記憶體管理區域, 一個管理區域通過struct zone_struct描述, 其被定義為zone_t, 用以表示記憶體的某個範圍, 低端範圍的16MB被描述為ZONE_DMA, 某些工業標準體繫結構中的(ISA)設備需要用到它, 然後是可直接映射到內核的普通記憶體域ZONE_NORMAL,最後是超出了內核段的物理地址域ZONE_HIGHMEM, 被稱為高端記憶體. 是系統中預留的可用記憶體空間, 不能被內核直接映射.
下麵我們就來詳解講講記憶體管理域的內容zone
2 為什麼要將記憶體node分成不同的區域zone
NUMA結構下, 每個處理器CPU與一個本地記憶體直接相連, 而不同處理器之前則通過匯流排進行進一步的連接, 因此相對於任何一個CPU訪問本地記憶體的速度比訪問遠程記憶體的速度要快, 而Linux為了相容NUMAJ結構, 把物理記憶體相依照CPU的不同node分成簇, 一個CPU-node對應一個本地記憶體pgdata_t.
這樣已經很好的表示物理記憶體了, 在一個理想的電腦系統中, 一個頁框就是一個記憶體的分配單元, 可用於任何事情:存放內核數據, 用戶數據和緩衝磁碟數據等等. 任何種類的數據頁都可以存放在任頁框中, 沒有任何限制.
但是Linux內核又把各個物理記憶體節點分成個不同的管理區域zone, 這是為什麼呢?
因為實際的電腦體繫結構有硬體的諸多限制, 這限制了頁框可以使用的方式. 尤其是, Linux內核必須處理80x86體繫結構的兩種硬體約束.
- ISA匯流排的直接記憶體存儲DMA處理器有一個嚴格的限制 : 他們只能對RAM的前16MB進行定址
- 在具有大容量RAM的現代32位電腦中, CPU不能直接訪問所有的物理地址, 因為線性地址空間太小, 內核不可能直接映射所有物理記憶體到線性地址空間, 我們會在後面典型架構(x86)上記憶體區域劃分詳細講解x86_32上的記憶體區域劃分
因此Linux內核對不同區域的記憶體需要採用不同的管理方式和映射方式, 因此內核將物理地址或者成用zone_t表示的不同地址區域
3 記憶體管理區類型zone_type
前面我們說了由於硬體的一些約束, 低端的一些地址被用於DMA, 而在實際記憶體大小超過了內核所能使用的現行地址的時候, 一些高地址處的物理地址不能簡單持久的直接映射到內核空間. 因此內核將記憶體的節點node分成了不同的記憶體區域方便管理和映射.
Linux使用enum zone_type來標記內核所支持的所有記憶體區域
3.1 記憶體區域類型zone_type
zone_type結構定義在include/linux/mmzone.h, 其基本信息如下所示
enum zone_type
{
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};不同的管理區的用途是不一樣的,ZONE_DMA類型的記憶體區域在物理記憶體的低端,主要是ISA設備只能用低端的地址做DMA操作。ZONE_NORMAL類型的記憶體區域直接被內核映射到線性地址空間上面的區域(line address space),ZONE_HIGHMEM將保留給系統使用,是系統中預留的可用記憶體空間,不能被內核直接映射。
3.2 不同的記憶體區域的作用
在記憶體中,每個簇所對應的node又被分成的稱為管理區(zone)的塊,它們各自描述在記憶體中的範圍。一個管理區(zone)由struct zone結構體來描述,在linux-2.4.37之前的內核中是用typedef struct zone_struct zone_t數據結構來描述)
管理區的類型用zone_type表示, 有如下幾種
| 管理記憶體域 | 描述 |
|---|---|
| ZONE_DMA | 標記了適合DMA的記憶體域. 該區域的長度依賴於處理器類型. 這是由於古老的ISA設備強加的邊界. 但是為了相容性, 現代的電腦也可能受此影響 |
| ZONE_DMA32 | 標記了使用32位地址字可定址, 適合DMA的記憶體域. 顯然, 只有在53位系統中ZONE_DMA32才和ZONE_DMA有區別, 在32位系統中, 本區域是空的, 即長度為0MB, 在Alpha和AMD64系統上, 該記憶體的長度可能是從0到4GB |
| ZONE_NORMAL | 標記了可直接映射到記憶體段的普通記憶體域. 這是在所有體繫結構上保證會存在的唯一記憶體區域, 但無法保證該地址範圍對應了實際的物理地址. 例如, 如果AMD64系統只有兩2G記憶體, 那麼所有的記憶體都屬於ZONE_DMA32範圍, 而ZONE_NORMAL則為空 |
| ZONE_HIGHMEM | 標記了超出內核虛擬地址空間的物理記憶體段, 因此這段地址不能被內核直接映射 |
| ZONE_MOVABLE | 內核定義了一個偽記憶體域ZONE_MOVABLE, 在防止物理記憶體碎片的機制memory migration中需要使用該記憶體域. 供防止物理記憶體碎片的極致使用 |
| ZONE_DEVICE | 為支持熱插拔設備而分配的Non Volatile Memory非易失性記憶體 |
| MAX_NR_ZONES | 充當結束標記, 在內核中想要迭代系統中所有記憶體域, 會用到該常亮 |
根據編譯時候的配置, 可能無需考慮某些記憶體域. 如在64位系統中, 並不需要高端記憶體, 因為AM64的linux採用4級頁表,支持的最大物理記憶體為64TB, 對於虛擬地址空間的劃分,將0x0000,0000,0000,0000 – 0x0000,7fff,ffff,f000這128T地址用於用戶空間;而0xffff,8000,0000,0000以上的128T為系統空間地址, 這遠大於當前我們系統中的記憶體空間, 因此所有的物理地址都可以直接映射到內核中, 不需要高端記憶體的特殊映射. 可以參見Documentation/x86/x86_64/mm.txt
ZONE_MOVABLE和ZONE_DEVICE其實是和其他的ZONE的用途有異,
- ZONE_MOVABLE在防止物理記憶體碎片的機制中需要使用該記憶體區域,
- ZONE_DEVICE筆者也第一次知道了,理解有錯的話歡迎大家批評指正, 這個應該是為支持熱插拔設備而分配的Non Volatile Memory非易失性記憶體,
關於ZONE_DEVICE, 具體的信息可以參見[ATCH v2 3/9mm: ZONE_DEVICE for “device memory”
While pmem is usable as a block device or via DAX mappings to userspace
there are several usage scenarios that can not target pmem due to its
lack of struct page coverage. In preparation for “hot plugging” pmem
into the vmemmap add ZONE_DEVICE as a new zone to tag these pages
separately from the ones that are subject to standard page allocations.
Importantly “device memory” can be removed at will by userspace
unbinding the driver of the device.
3.3 典型架構(x86)上記憶體區域劃分
對於x86機器,管理區(記憶體區域)類型如下分佈
| 類型 | 區域 |
|---|---|
| ZONE_DMA | 0~15MB |
| ZONE_NORMAL | 16MB~895MB |
| ZONE_HIGHMEM | 896MB~物理記憶體結束 |
而由於32位系統中, Linux內核虛擬地址空間只有1G, 而0~895M這個986MB被用於DMA和直接映射, 剩餘的物理記憶體被成為高端記憶體. 那內核是如何藉助剩餘128MB高端記憶體地址空間是如何實現訪問可以所有物理記憶體?
當內核想訪問高於896MB物理地址記憶體時,從0xF8000000 ~ 0xFFFFFFFF地址空間範圍內找一段相應大小空閑的邏輯地址空間,借用一會。借用這段邏輯地址空間,建立映射到想訪問的那段物理記憶體(即填充內核PTE頁面表),臨時用一會,用完後歸還。這樣別人也可以借用這段地址空間訪問其他物理記憶體,實現了使用有限的地址空間,訪問所有所有物理記憶體
關於高端記憶體的內容, 我們後面會專門抽出一章進行講解
因此, 傳統和X86_32位系統中, 前16M劃分給ZONE_DMA, 該區域包含的頁框可以由老式的基於ISAS的設備通過DMA使用”直接記憶體訪問(DMA)”, ZONE_DMA和ZONE_NORMAL區域包含了記憶體的常規頁框, 通過把他們線性的映射到現行地址的第4個GB, 內核就可以直接進行訪問, 相反ZONE_HIGHME包含的記憶體頁不能由內核直接訪問, 儘管他們也線性地映射到了現行地址空間的第4個GB. 在64位體繫結構中, 線性地址空間的大小遠遠好過了系統的實際物理地址, 內核可知直接將所有的物理記憶體映射到線性地址空間, 因此64位體繫結構上ZONE_HIGHMEM區域總是空的.
4 管理區結構zone_t
一個管理區(zone)由
struct zone結構體來描述(linux-3.8~目前linux4.5),而在linux-2.4.37之前的內核中是用struct zone_struct數據結構來描述), 他們都通過typedef被重定義為zone_t類型
zone對象用於跟蹤諸如頁面使用情況的統計數, 空閑區域信息和鎖信息
裡面保存著記憶體使用狀態信息,如page使用統計, 未使用的記憶體區域,互斥訪問的鎖(LOCKS)等.
4.1 struct zone管理域數據結構
struct zone在linux/mmzone.h中定義, 在linux-4.7的內核中可以使用include/linux/mmzone.h來查看其定義
struct zone
{
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
* 分別為各種記憶體域指定了若幹頁
* 用於一些無論如何都不能失敗的關鍵性記憶體分配。
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this zone's LRU. Maintained by the pageout code.
* 不活動頁的比例,
* 接著是一些很少使用或者大部分情況下是只讀的欄位:
* wait_table wait_table_hash_nr_entries wait_table_bits
* 形成等待列隊,可以等待某一頁可供進程使用 */
unsigned int inactive_ratio;
/* 指向這個zone所在的pglist_data對象 */
struct pglist_data *zone_pgdat;
/*/這個數組用於實現每個CPU的熱/冷頁幀列表。內核使用這些列表來保存可用於滿足實現的“新鮮”頁。但冷熱頁幀對應的高速緩存狀態不同:有些頁幀很可能在高速緩存中,因此可以快速訪問,故稱之為熱的;未緩存的頁幀與此相對,稱之為冷的。*/
struct per_cpu_pageset __percpu *pageset;
/*
* This is a per-zone reserve of pages that are not available
* to userspace allocations.
* 每個區域保留的不能被用戶空間分配的頁面數目
*/
unsigned long totalreserve_pages;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT
* 只記憶體域的第一個頁幀 */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;
unsigned long spanned_pages; /* 總頁數,包含空洞 */
unsigned long present_pages; /* 可用頁數,不包哈空洞 */
/* 指向管理區的傳統名字, "DMA", "NROMAL"或"HIGHMEM" */
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
/*
* wait_table -- the array holding the hash table
* wait_table_hash_nr_entries -- the size of the hash table array
* wait_table_bits -- wait_table_size == (1 << wait_table_bits)
*
* The purpose of all these is to keep track of the people
* waiting for a page to become available and make them
* runnable again when possible. The trouble is that this
* consumes a lot of space, especially when so few things
* wait on pages at a given time. So instead of using
* per-page waitqueues, we use a waitqueue hash table.
*
* The bucket discipline is to sleep on the same queue when
* colliding and wake all in that wait queue when removing.
* When something wakes, it must check to be sure its page is
* truly available, a la thundering herd. The cost of a
* collision is great, but given the expected load of the
* table, they should be so rare as to be outweighed by the
* benefits from the saved space.
*
* __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
* primary users of these fields, and in mm/page_alloc.c
* free_area_init_core() performs the initialization of them.
*/
/* 進程等待隊列的散列表, 這些進程正在等待管理區中的某頁 */
wait_queue_head_t *wait_table;
/* 等待隊列散列表中的調度實體數目 */
unsigned long wait_table_hash_nr_entries;
/* 等待隊列散列表數組大小, 值為2^order */
unsigned long wait_table_bits;
ZONE_PADDING(_pad1_)
/* free areas of different sizes
頁面使用狀態的信息,以每個bit標識對應的page是否可以分配
是用於伙伴系統的,每個數組元素指向對應階也表的數組開頭
以下是供頁幀回收掃描器(page reclaim scanner)訪問的欄位
scanner會跟據頁幀的活動情況對記憶體域中使用的頁進行編目
如果頁幀被頻繁訪問,則是活動的,相反則是不活動的,
在需要換出頁幀時,這樣的信息是很重要的: */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below 描述當前記憶體的狀態, 參見下麵的enum zone_flags結構 */
unsigned long flags;
/* Write-intensive fields used from the page allocator, 保存該描述符的自旋鎖 */
spinlock_t lock;
ZONE_PADDING(_pad2_)
/* Write-intensive fields used by page reclaim */
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock; /* LRU(最近最少使用演算法)活動以及非活動鏈表使用的自旋鎖 */
struct lruvec lruvec;
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
* 在空閑頁的數目少於這個點percpu_drift_mark的時候
* 當讀取和空閑頁數一樣的記憶體頁時,系統會採取額外的工作,
* 防止單CPU頁數漂移,從而導致水印被破壞。
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics 記憶體域的統計信息, 參見後面的enum zone_stat_item結構 */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;| 欄位 | 描述 |
|---|---|
| watermark | 每個 zone 在系統啟動時會計算出 3 個水位值, 分別為 WMAKR_MIN, WMARK_LOW, WMARK_HIGH 水位, 這在頁面分配器和 kswapd 頁面回收中會用到 |
| lowmem_reserve[MAX_NR_ZONES] | zone 中預留的記憶體, 為了防止一些代碼必須運行在低地址區域,所以事先保留一些低地址區域的記憶體 |
| pageset | page管理的數據結構對象,內部有一個page的列表(list)來管理。每個CPU維護一個page list,避免自旋鎖的衝突。這個數組的大小和NR_CPUS(CPU的數量)有關,這個值是編譯的時候確定的 |
| lock | 對zone併發訪問的保護的自旋鎖 |
| free_area[MAX_ORDER] | 頁面使用狀態的信息,以每個bit標識對應的page是否可以分配 |
| lru_lock | LRU(最近最少使用演算法)的自旋鎖 |
| wait_table | 待一個page釋放的等待隊列哈希表。它會被wait_on_page(),unlock_page()函數使用. 用哈希表,而不用一個等待隊列的原因,防止進程長期等待資源 |
| wait_table_hash_nr_entries | 哈希表中的等待隊列的數量 |
| zone_pgdat | 指向這個zone所在的pglist_data對象 |
| zone_start_pfn | 和node_start_pfn的含義一樣。這個成員是用於表示zone中的開始那個page在物理記憶體中的位置的present_pages, spanned_pages: 和node中的類似的成員含義一樣 |
| name | zone的名字,字元串表示: “DMA”,”Normal” 和”HighMem” |
| totalreserve_pages | 每個區域保留的不能被用戶空間分配的頁面數目 |
| ZONE_PADDING | 由於自旋鎖頻繁的被使用,因此為了性能上的考慮,將某些成員對齊到cache line中,有助於提高執行的性能。使用這個巨集,可以確定zone->lock,zone->lru_lock,zone->pageset這些成員使用不同的cache line. |
| managed_pages | zone 中被伙伴系統管理的頁面數量 |
| spanned_pages | zone 中包含的頁面數量 |
| present_pages | zone 中實際管理的頁面數量. 對一些體繫結構來說, 其值和 spanned_pages 相等 |
| lruvec | LRU 鏈表集合 |
| vm_stat | zone 計數 |
4.2 ZONE_PADDING將數據保存在高速緩衝行
該結構比較特殊的地方是它由ZONE_PADDING分隔的幾個部分. 這是因為堆zone結構的訪問非常頻繁.在多處理器系統中, 通常會有不同的CPU試圖同時訪問結構成員. 因此使用鎖可以防止他們彼此干擾, 避免錯誤和不一致的問題. 由於內核堆該結構的訪問非常頻繁, 因此會經常性地獲取該結構的兩個自旋鎖zone->lock和zone->lru_lock
由於
struct zone結構經常被訪問到, 因此這個數據結構要求以L1 Cache對齊. 另外, 這裡的ZONE_PADDING( )讓zone->lock和zone_lru_lock這兩個很熱門的鎖可以分佈在不同的Cahe Line中.一個記憶體node節點最多也就幾個zone, 因此 zone 數據結構不需要像 struct page 一樣關心數據結構的大小,
那麼數據保存在CPU高速緩存中, 那麼會處理得更快速. 高速緩衝分為行, 每一行負責不同的記憶體區.內核使用ZONE_PADDING巨集生成”填充”欄位添加到結構中, 以確保每個自旋鎖處於自身的緩存行中
ZONE_PADDING巨集定義在include/linux/mmzone.h?v4.7, line 105
/*
* zone->lock and zone->lru_lock are two of the hottest locks in the kernel.
* So add a wild amount of padding here to ensure that they fall into separate
* cachelines. There are very few zone structures in the machine, so space
* consumption is not a concern here.
*/
#if defined(CONFIG_SMP)
struct zone_padding
{
char x[0];
} ____cacheline_internodealigned_in_smp;
#define ZONE_PADDING(name) struct zone_padding name;
#else
#define ZONE_PADDING(name)
#endif內核還用了____cacheline_internodealigned_in_smp,來實現最優的高速緩存行對其方式.
該巨集定義在include/linux/cache.h
#if !defined(____cacheline_internodealigned_in_smp)
#if defined(CONFIG_SMP)
#define ____cacheline_internodealigned_in_smp \
__attribute__((__aligned__(1 << (INTERNODE_CACHE_SHIFT))))
#else
#define ____cacheline_internodealigned_in_smp
#endif
#endif4.3 水印watermark[NR_WMARK]與kswapd內核線程
Zone的管理調度的一些參數watermarks水印, 水存量很小(MIN)進水量,水存量達到一個標準(LOW)減小進水量,當快要滿(HIGH)的時候,可能就關閉了進水口
WMARK_LOW, WMARK_LOW, WMARK_HIGH就是這個標準
enum zone_watermarks
{
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])在linux-2.4中, zone結構中使用如下方式表示水印, 參照include/linux/mmzone.h?v=2.4.37, line 171
typedef struct zone_watermarks_s
{
unsigned long min, low, high;
} zone_watermarks_t;
typedef struct zone_struct {
zone_watermarks_t watermarks[MAX_NR_ZONES];在Linux-2.6.x中標準是直接通過成員pages_min, pages_low and pages_high定義在zone結構體中的, 參照include/linux/mmzone.h?v=2.6.24, line 214
當系統中可用記憶體很少的時候,系統進程kswapd被喚醒, 開始回收釋放page, 水印這些參數(WMARK_MIN, WMARK_LOW, WMARK_HIGH)影響著這個代碼的行為
每個zone有三個水平標準:watermark[WMARK_MIN], watermark[WMARK_LOW], watermark[WMARK_HIGH],幫助確定zone中記憶體分配使用的壓力狀態
| 標準 | 描述 |
|---|---|
| watermark[WMARK_MIN] | 當空閑頁面的數量達到page_min所標定的數量的時候, 說明頁面數非常緊張, 分配頁面的動作和kswapd線程同步運行. WMARK_MIN所表示的page的數量值,是在記憶體初始化的過程中調用free_area_init_core中計算的。這個數值是根據zone中的page的數量除以一個>1的繫數來確定的。通常是這樣初始化的ZoneSizeInPages/12 |
| watermark[WMARK_LOW] | 當空閑頁面的數量達到WMARK_LOW所標定的數量的時候,說明頁面剛開始緊張, 則kswapd線程將被喚醒,並開始釋放回收頁面 |
| watermark[WMARK_HIGH] | 當空閑頁面的數量達到page_high所標定的數量的時候, 說明記憶體頁面數充足, 不需要回收, kswapd線程將重新休眠,通常這個數值是page_min的3倍 |
- 如果空閑頁多於pages_high = watermark[WMARK_HIGH], 則說明記憶體頁面充足, 記憶體域的狀態是理想的.
- 如果空閑頁的數目低於pages_low = watermark[WMARK_LOW], 則說明記憶體頁面開始緊張, 內核開始將頁回收到硬碟.
- 如果空閑頁的數目低於pages_min = watermark[WMARK_MIN], 則記憶體頁面非常緊張, 頁回收工作的壓力就比較大
4.3 記憶體域標誌
記憶體管理域zone_t結構中的flags欄位描述了記憶體域的當前狀態
// http://lxr.free-electrons.com/source/include/linux/mmzone.h#L475
struct zone
{
/* zone flags, see below */
unsigned long flags;
}它允許使用的標識用enum zone_flags標識, 該枚舉標識定義在include/linux/mmzone.h?v4.7, line 525, 如下所示
enum zone_flags
{
ZONE_RECLAIM_LOCKED, /* prevents concurrent reclaim */
ZONE_OOM_LOCKED, /* zone is in OOM killer zonelist 記憶體域可被回收*/
ZONE_CONGESTED, /* zone has many dirty pages backed by
* a congested BDI
*/
ZONE_DIRTY, /* reclaim scanning has recently found
* many dirty file pages at the tail
* of the LRU.
*/
ZONE_WRITEBACK, /* reclaim scanning has recently found
* many pages under writeback
*/
ZONE_FAIR_DEPLETED, /* fair zone policy batch depleted */
};| flag標識 | 描述 |
|---|---|
| ZONE_RECLAIM_LOCKED | 防止併發回收, 在SMP上系統, 多個CPU可能試圖併發的回收億i個記憶體域. ZONE_RECLAIM_LCOKED標誌可防止這種情況: 如果一個CPU在回收某個記憶體域, 則設置該標識. 這防止了其他CPU的嘗試 |
| ZONE_OOM_LOCKED | 用於某種不走運的情況: 如果進程消耗了大量的記憶體, 致使必要的操作都無法完成, 那麼內核會使徒殺死消耗記憶體最多的進程, 以獲取更多的空閑頁, 該標誌可以放置多個CPU同時進行這種操作 |
| ZONE_CONGESTED | 標識當前區域中有很多臟頁 |
| ZONE_DIRTY | 用於標識最近的一次頁面掃描中, LRU演算法發現了很多髒的頁面 |
| ZONE_WRITEBACK | 最近的回收掃描發現有很多頁在寫回 |
| ZONE_FAIR_DEPLETED | 公平區策略耗盡(沒懂) |
4.4 記憶體域統計信息vm_stat
記憶體域struct zone的vm_stat維護了大量有關該記憶體域的統計信息. 由於其中維護的大部分信息曲面沒有多大意義
// http://lxr.free-electrons.com/source/include/linux/mmzone.h#L522
struct zone
{
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
}vm_stat的統計信息由enum zone_stat_item枚舉變數標識, 定義在include/linux/mmzone.h?v=4.7, line 110
enum zone_stat_item
{
/* First 128 byte cacheline (assuming 64 bit words) */
NR_FREE_PAGES,
NR_ALLOC_BATCH,
NR_LRU_BASE,
NR_INACTIVE_ANON = NR_LRU_BASE, /* must match order of LRU_[IN]ACTIVE */
NR_ACTIVE_ANON, /* " " " " " */
NR_INACTIVE_FILE, /* " " " " " */
NR_ACTIVE_FILE, /* " " " " " */
NR_UNEVICTABLE, /* " " " " " */
NR_MLOCK, /* mlock()ed pages found and moved off LRU */
NR_ANON_PAGES, /* Mapped anonymous pages */
NR_FILE_MAPPED, /* pagecache pages mapped into pagetables.
only modified from process context */
NR_FILE_PAGES,
NR_FILE_DIRTY,
NR_WRITEBACK,
NR_SLAB_RECLAIMABLE,
NR_SLAB_UNRECLAIMABLE,
NR_PAGETABLE, /* used for pagetables */
NR_KERNEL_STACK,
/* Second 128 byte cacheline */
NR_UNSTABLE_NFS, /* NFS unstable pages */
NR_BOUNCE,
NR_VMSCAN_WRITE,
NR_VMSCAN_IMMEDIATE, /* Prioritise for reclaim when writeback ends */
NR_WRITEBACK_TEMP, /* Writeback using temporary buffers */
NR_ISOLATED_ANON, /* Temporary isolated pages from anon lru */
NR_ISOLATED_FILE, /* Temporary isolated pages from file lru */
NR_SHMEM, /* shmem pages (included tmpfs/GEM pages) */
NR_DIRTIED, /* page dirtyings since bootup */
NR_WRITTEN, /* page writings since bootup */
NR_PAGES_SCANNED, /* pages scanned since last reclaim */
#ifdef CONFIG_NUMA
NUMA_HIT, /* allocated in intended node */
NUMA_MISS, /* allocated in non intended node */
NUMA_FOREIGN, /* was intended here, hit elsewhere */
NUMA_INTERLEAVE_HIT, /* interleaver preferred this zone */
NUMA_LOCAL, /* allocation from local node */
NUMA_OTHER, /* allocation from other node */
#endif
WORKINGSET_REFAULT,
WORKINGSET_ACTIVATE,
WORKINGSET_NODERECLAIM,
NR_ANON_TRANSPARENT_HUGEPAGES,
NR_FREE_CMA_PAGES,
NR_VM_ZONE_STAT_ITEMS
};內核提供了很多方式來獲取當前記憶體域的狀態信息, 這些函數大多定義在include/linux/vmstat.h?v=4.7
4.5 Zone等待隊列表(zone wait queue table)
struct zone中實現了一個等待隊列, 可用於等待某一頁的進程, 內核將進程排成一個列隊, 等待某些條件. 在條件變成真時, 內核會通知進程恢復工作.
struct zone
{
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
}| 欄位 | 描述 |
|---|---|
| wait_table | 待一個page釋放的等待隊列哈希表。它會被wait_on_page(),unlock_page()函數使用. 用哈希表,而不用一個等待隊列的原因,防止進程長期等待資源 |
| wait_table_hash_nr_entries | 哈希表中的等待隊列的數量 |
| wait_table_bits | 等待隊列散列表數組大小, wait_table_size == (1 << wait_table_bits) |
當對一個page做I/O操作的時候,I/O操作需要被鎖住,防止不正確的數據被訪問。進程在訪問page前,wait_on_page_locked函數,使進程加入一個等待隊列
訪問完成後,UnlockPage函數解鎖其他進程對page的訪問。其他正在等待隊列中的進程被喚醒。每個page都可以有一個等待隊列,但是太多的分離的等待隊列使得花費太多的記憶體訪問周期。替代的解決方法,就是將所有的隊列放在struct zone數據結構中
也可以有一種可能,就是struct zone中只有一個隊列,但是這就意味著,當一個page unlock的時候,訪問這個zone里記憶體page的所有休眠的進程將都被喚醒,這樣就會出現擁堵(thundering herd)的問題。建立一個哈希表管理多個等待隊列,能解決這個問題,zone->wait_table就是這個哈希表。哈希表的方法可能還是會造成一些進程不必要的喚醒。但是這種事情發生的機率不是很頻繁的。下麵這個圖就是進程及等待隊列的運行關係:
等待隊列的哈希表的分配和建立在free_area_init_core函數中進行。哈希表的表項的數量在wait_table_size() 函數中計算,並且保持在zone->wait_table_size成員中。最大4096個等待隊列。最小是NoPages / PAGES_PER_WAITQUEUE的2次方,NoPages是zone管理的page的數量,PAGES_PER_WAITQUEUE被定義256
zone->wait_table_bits用於計算:根據page 地址得到需要使用的等待隊列在哈希表中的索引的演算法因數. page_waitqueue()函數負責返回zone中page所對應等待隊列。它用一個基於struct page虛擬地址的簡單的乘法哈希演算法來確定等待隊列的.
page_waitqueue()函數用GOLDEN_RATIO_PRIME的地址和“右移zone→wait_table_bits一個索引值”的一個乘積來確定等待隊列在哈希表中的索引的。
Zone的初始化, 在kernel page table通過paging_init()函數完全建立起z來以後,zone被初始化。下麵章節將描述這個。當然不同的體繫結構這個過程肯定也是不一樣的,但它們的目的卻是相同的:確定什麼參數需要傳遞給free_area_init()函數(對於UMA體繫結構)或者free_area_init_node()函數(對於NUMA體繫結構)。這裡省略掉NUMA體繫結構的說明。
free_area_init()函數的參數:
unsigned long *zones_sizes: 系統中每個zone所管理的page的數量的數組。這個時候,還沒能確定zone中那些page是可以分配使用的(free)。這個信息知道boot memory allocator完成之前還無法知道。
4.6 冷熱頁與Per-CPU上的頁面高速緩存
內核經常請求和釋放單個頁框. 為了提升性能, 每個記憶體管理區都定義了一個每CPU(Per-CPU)的頁面高速緩存. 所有”每CPU高速緩存”包含一些預先分配的頁框, 他們被定義滿足本地CPU發出的單一記憶體請求.
struct zone的pageset成員用於實現冷熱分配器(hot-n-cold allocator)
struct zone
{
struct per_cpu_pageset __percpu *pageset;
};內核說頁面是熱的, 意味著頁面已經載入到CPU的高速緩存, 與在記憶體中的頁相比, 其數據訪問速度更快. 相反, 冷頁則不再高速緩存中. 在多處理器系統上每個CPU都有一個或者多個告訴緩存. 各個CPU的管理必須是獨立的.
儘管記憶體域可能屬於一個特定的NUMA結點, 因而關聯到某個特定的CPU。 但其他CPU的告訴緩存仍然可以包含該記憶體域中的頁面. 最終的效果是, 每個處理器都可以訪問系統中的所有頁, 儘管速度不同. 因而, 特定於記憶體域的數據結構不僅要考慮到所屬NUMA結點相關的CPU, 還必須照顧到系統中其他的CPU.
pageset是一個指針, 其容量與系統能夠容納的CPU的數目的最大值相同.
數組元素類型為per_cpu_pageset, 定義在include/linux/mmzone.h?v4.7, line 254 如下所示
struct per_cpu_pageset {
struct per_cpu_pages pcp;
#ifdef CONFIG_NUMA
s8 expire;
#endif
#ifdef CONFIG_SMP
s8 stat_threshold;
s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS];
#endif
};該結構由一個per_cpu_pages pcp變數組成, 該數據結構定義如下, 位於include/linux/mmzone.h?v4.7, line 245
struct per_cpu_pages {
int count; /* number of pages in the list 列表中的頁數 */
int high; /* high watermark, emptying needed 頁數上限水印, 在需要的情況清空列表 */
int batch; /* chunk size for buddy add/remove, 添加/刪除多頁塊的時候, 塊的大小 */
/* Lists of pages, one per migrate type stored on the pcp-lists 頁的鏈表*/
struct list_head lists[MIGRATE_PCPTYPES];
};| 欄位 | 描述 |
|---|---|
| count | 記錄了與該列表相關的頁的數目 |
| high | 是一個水印. 如果count的值超過了high, 則表明列表中的頁太多了 |
| batch | 如果可能, CPU的高速緩存不是用單個頁來填充的, 而是歐諾個多個頁組成的塊, batch作為每次添加/刪除頁時多個頁組成的塊大小的一個參考值 |
| list | 一個雙鏈表, 保存了當前CPU的冷頁或熱頁, 可使用內核的標準方法處理 |
在內核中只有一個子系統會積極的嘗試為任何對象維護per-cpu上的list鏈表, 這個子系統就是slab分配器.
- struct per_cpu_pageset具有一個欄位, 該欄位
- struct per_cpu_pages則維護了鏈表中目前已有的一系列頁面, 高極值和低極值決定了何時填充該集合或者釋放一批頁面, 變數決定了一個塊中應該分配多少個頁面, 並最後決定在頁面前的實際鏈表中分配多少各頁面
4.7 記憶體域的第一個頁幀zone_start_pfn
struct zone中通過zone_start_pfn成員標記了記憶體管理區的頁面地址.
然後內核也通過一些全局變數標記了物理記憶體所在頁面的偏移, 這些變數定義在mm/nobootmem.c?v4.7, line 31
unsigned long max_low_pfn;
unsigned long min_low_pfn;
unsigned long max_pfn;
unsigned long long max_possible_pfn;PFN是物理記憶體以Page為單位的偏移量
| 變數 | 描述 |
|---|---|
| max_low_pfn | x86中,max_low_pfn變數是由find_max_low_pfn函數計算並且初始化的,它被初始化成ZONE_NORMAL的最後一個page的位置。這個位置是kernel直接訪問的物理記憶體, 也是關係到kernel/userspace通過“PAGE_OFFSET巨集”把線性地址記憶體空間分開的記憶體地址位置 |
| min_low_pfn | 系統可用的第一個pfn是min_low_pfn變數, 開始與_end標號的後面, 也就是kernel結束的地方.在文件mm/bootmem.c中對這個變數作初始化 |
| max_pfn | 系統可用的最後一個PFN是max_pfn變數, 這個變數的初始化完全依賴與硬體的體繫結構. |
| max_possible_pfn |
x86的系統中, find_max_pfn函數通過讀取e820表獲得最高的page frame的數值, 同樣在文件mm/bootmem.c中對這個變數作初始化。e820表是由BIOS創建的
This is the physical memory directly accessible by the kernel and is related to the kernel/userspace split in the linear address space marked by PAGE OFFSET.
我理解為這段地址kernel可以直接訪問,可以通過PAGE_OFFSET巨集直接將kernel所用的虛擬地址轉換成物理地址的區段。在文件mm/bootmem.c中對這個變數作初始化。在記憶體比較小的系統中max_pfn和max_low_pfn的值相同
min_low_pfn, max_pfn和max_low_pfn這3個值,也要用於對高端記憶體(high memory)的起止位置的計算。在arch/i386/mm/init.c文件中會對類似的highstart_pfn和highend_pfn變數作初始化。這些變數用於對高端記憶體頁面的分配。後面將描述。
5 管理區表zone_table與管理區節點的映射
內核在初始化記憶體管理區時, 首先建立管理區表zone_table. 參見mm/page_alloc.c?v=2.4.37, line 38
/*
*
* The zone_table array is used to look up the address of the
* struct zone corresponding to a given zone number (ZONE_DMA,
* ZONE_NORMAL, or ZONE_HIGHMEM).
*/
zone_t *zone_table[MAX_NR_ZONES*MAX_NR_NODES];
EXPORT_SYMBOL(zone_table);MAX_NR_ZONES是一個節點中所能包容納的管理區的最大數, 如3個, 定義在include/linux/mmzone.h?v=2.4.37, line 25, 與zone區域的類型(ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM)定義在一起. 當然這時候我們這些標識都是通過巨集的方式來實現的, 而不是如今的枚舉類型
MAX_NR_NODES是可以存在的節點的最大數.
函數EXPORT_SYMBOL使得內核的變數或者函數可以被載入的模塊(比如我們的驅動模塊)所訪問.
該表處理起來就像一個多維數組, 在函數free_area_init_core中, 一個節點的所有頁面都會被初始化.
6 zonelist記憶體域存儲層次
6.1 記憶體域之間的層級結構
當前結點與系統中其他結點的記憶體域之前存在一種等級次序
我們考慮一個例子, 其中內核想要分配高端記憶體.
- 它首先企圖在當前結點的高端記憶體域找到一個大小適當的空閑段. 如果失敗, 則查看該結點的普通記憶體域. 如果還失敗, 則試圖在該結點的DMA記憶體域執行分配.
- 如果在3個本地記憶體域都無法找到空閑記憶體, 則查看其他結點. 在這種情況下, 備選結點應該儘可能靠近主結點, 以最小化由於訪問非本地記憶體引起的性能損失.
內核定義了記憶體的一個層次結構, 首先試圖分配”廉價的”記憶體. 如果失敗, 則根據訪問速度和容量, 逐漸嘗試分配”更昂貴的”記憶體.
高端記憶體是最廉價的, 因為內核沒有任何部份依賴於從該記憶體域分配的記憶體. 如果高端記憶體域用盡, 對內核沒有任何副作用, 這也是優先分配高端記憶體的原因.
其次是普通記憶體域, 這種情況有所不同. 許多內核數據結構必須保存在該記憶體域, 而不能放置到高端記憶體域.
因此如果普通記憶體完全用盡, 那麼內核會面臨緊急情況. 所以只要高端記憶體域的記憶體沒有用盡, 都不會從普通記憶體域分配記憶體.
最昂貴的是DMA記憶體域, 因為它用於外設和系統之間的數據傳輸. 因此從該記憶體域分配記憶體是最後一招.
6.2 zonelist結構
內核還針對當前記憶體結點的備選結點, 定義了一個等級次序. 這有助於在當前結點所有記憶體域的記憶體都用盡時, 確定一個備選結點
內核使用pg_data_t中的zonelist數組, 來表示所描述的層次結構.
typedef struct pglist_data {
struct zonelist node_zonelists[MAX_ZONELISTS];
/* ...... */
}pg_data_t;關於該結構zonelist的所有相關信息定義include/linux/mmzone.h?v=4.7, line 568, 我們下麵慢慢來講.
node_zonelists數組對每種可能的記憶體域類型, 都配置了一個獨立的數組項.
該數組項的大小MAX_ZONELISTS用一個匿名的枚舉常量定義, 定義在include/linux/mmzone.h?v=4.7, line 571
enum
{
ZONELIST_FALLBACK, /* zonelist with fallback */
#ifdef CONFIG_NUMA
/*
* The NUMA zonelists are doubled because we need zonelists that
* restrict the allocations to a single node for __GFP_THISNODE.
*/
ZONELIST_NOFALLBACK, /* zonelist without fallback (__GFP_THISNODE) */
#endif
MAX_ZONELISTS
};我們會發現在UMA結構下, 數組大小MAX_ZONELISTS = 1, 因為只有一個記憶體結點, zonelist中只會存儲一個ZONELIST_FALLBACK類型的結構, 但是NUMA下需要多餘的ZONELIST_NOFALLBACK用以表示當前結點的信息
pg_data_t->node_zonelists數組項用struct zonelis結構體定義, 該結構包含了類型為struct zoneref的一個備用列表由於該備用列表必須包括所有結點的所有記憶體域,因此由MAX_NUMNODES * MAX_NZ_ZONES項組成,外加一個用於標記列表結束的空指針
struct zonelist結構的定義在include/linux/mmzone.h?v=4.7, line 606
/*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* To speed the reading of the zonelist, the zonerefs contain the zone index
* of the entry being read. Helper functions to access information given
* a struct zoneref are
*
* zonelist_zone() - Return the struct zone * for an entry in _zonerefs
* zonelist_zone_idx() - Return the index of the zone for an entry
* zonelist_node_idx() - Return the index of the node for an entry
*/
struct zonelist {
struct zoneref _zo而struct zoneref結構的定義如下include/linux/mmzone.h?v=4.7, line 583
/*
* This struct contains information about a zone in a zonelist. It is stored
* here to avoid dereferences into large structures and lookups of tables
*/
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};6.3 記憶體域的排列方式
那麼我們內核是如何組織在zonelist中組織記憶體域的呢?
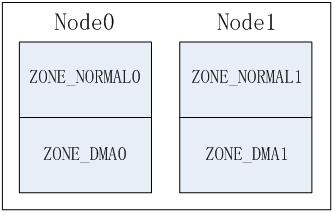
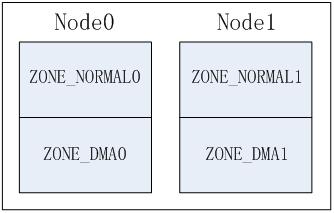
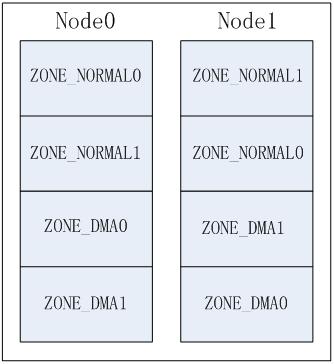
NUMA系統中存在多個節點, 每個節點對應一個struct pglist_data結構, 每個結點中可以包含多個zone, 如: ZONE_DMA, ZONE_NORMAL, 這樣就產生幾種排列順序, 以2個節點2個zone為例(zone從高到低排列, ZONE_DMA0表示節點0的ZONE_DMA,其它類似).
- Legacy方式, 每個節點只排列自己的zone;
Node方式, 按節點順序依次排列,先排列本地節點的所有zone,再排列其它節點的所有zone。
Zone方式, 按zone類型從高到低依次排列各節點的同相類型zone
可通過啟動參數”numa_zonelist_order”來配置zonelist order,內核定義了3種配置, 這些順序定義在mm/page_alloc.c?v=4.7, line 4551
// http://lxr.free-electrons.com/source/mm/page_alloc.c?v=4.7#L4551
#define ZONELIST_ORDER_DEFAULT 0 /* 智能選擇Node或Zone方式 */
#define ZONELIST_ORDER_NODE 1 /* 對應Node方式 */
#define ZONELIST_ORDER_ZONE 2 /* 對應Zone方式 */註意
在非NUMA系統中(比如UMA), 由於只有一個記憶體結點, 因此ZONELIST_ORDER_ZONE和ZONELIST_ORDER_NODE選項會配置相同的記憶體域排列方式, 因此, 只有NUMA可以配置這幾個參數
全局的current_zonelist_order變數標識了系統中的當前使用的記憶體域排列方式, 預設配置為ZONELIST_ORDER_DEFAULT, 參見mm/page_alloc.c?v=4.7, line 4564
| 巨集 | zonelist_order_name巨集 | 排列方式 | 描述 |
|---|---|---|---|
| ZONELIST_ORDER_DEFAULT | Default | 由系統智能選擇Node或Zone方式 | |
| ZONELIST_ORDER_NODE | Node | Node方式 | 按節點順序依次排列,先排列本地節點的所有zone,再排列其它節點的所有zone |
| ZONELIST_ORDER_ZONE | Zone | Zone方式 | 按zone類型從高到低依次排列各節點的同相類型zone |
6.4 build_all_zonelists初始化記憶體節點
內核通過build_all_zonelists初始化了記憶體結點的zonelists域
首先內核通過set_zonelist_order函數設置了zonelist_order,如下所示, 參見mm/page_alloc.c?v=4.7, line 5031
建立備用層次結構的任務委托給build_zonelists, 該函數為每個NUMA結點都創建了相應的數據結構. 它需要指向相關的pg_data_t實例的指針作為參數
7 總結
在linux中,內核也不是對所有物理記憶體都一視同仁,內核而是把頁分為不同的區, 使用區來對具有相似特性的頁進行分組.
Linux必須處理如下兩種硬體存在缺陷而引起的記憶體定址問題:
- 一些硬體只能用某些特定的記憶體地址來執行DMA
- 一些體繫結構其記憶體的物理定址範圍比虛擬定址範圍大的多。這樣,就有一些記憶體不能永久地映射在內核空間上。
為瞭解決這些制約條件,Linux使用了三種區:
- ZONE_DMA : 這個區包含的頁用來執行DMA操作。
- ZONE_NOMAL : 這個區包含的都是能正常映射的頁。
- ZONE_HIGHEM : 這個區包”高端記憶體”,其中的頁能不永久地映射到內核地址空間
而為了相容一些設備的熱插拔支持以及記憶體碎片化的處理, 內核也引入一些邏輯上的記憶體區.
- ZONE_MOVABLE : 內核定義了一個偽記憶體域ZONE_MOVABLE, 在防止物理記憶體碎片的機制memory migration中需要使用該記憶體域. 供防止物理記憶體碎片的極致使用
- ZONE_DEVICE : 為支持熱插拔設備而分配的Non Volatile Memory非易失性記憶體區的實際使用與體繫結構是相關的。linux把系統的記憶體結點劃分區, 一個區包含了若幹個記憶體頁面, 形成不同的記憶體池,這樣就可以根據用途進行分配了
需要說明的是,區的劃分沒有任何物理意義, 只不過是內核為了管理頁而採取的一種邏輯上的分組. 儘管某些分配可能需要從特定的區中獲得頁, 但這並不是說, 某種用途的記憶體一定要從對應的區來獲取,如果這種可供分配的資源不夠用了,內核就會占用其他可用去的記憶體.
下表給出每個區及其在X86上所占的列表


