
上一篇,我們介紹了Hive的表操作做了簡單的描述和實踐。在實際使用中,可能會存在數據的導入導出,雖然可以使用sqoop等工具進行關係型數據導入導出操作,但有的時候只需要很簡便的方式進行導入導出即可 下麵我們開始介紹hive的數據導入,導出,以及集群的數據遷移進行描述。
閱讀目錄
本文版權歸mephisto和博客園共有,歡迎轉載,但須保留此段聲明,並給出原文鏈接,謝謝合作。
文章是哥(mephisto)寫的,SourceLink
序
上一篇,我們介紹了Hive的表操作做了簡單的描述和實踐。在實際使用中,可能會存在數據的導入導出,雖然可以使用sqoop等工具進行關係型數據導入導出操作,但有的時候只需要很簡便的方式進行導入導出即可
下麵我們開始介紹hive的數據導入,導出,以及集群的數據遷移進行描述。
導入文件到Hive
一:語法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]二:從本地導入
使用"LOCAL"就可以從本地導入
三:從集群導入
將語法中"LOCAL"去掉即可。
四:OVERWRITE
使用該參數,如果被導入的地方存在了相同的分區或者文件,則刪除並替換,否者直接跳過。
五:實戰
根據上篇我們建立的帶分區的score的例子,我們先構造兩個個文本文件score_7和score_8分別代表7月和8月的成績,文件會在後面附件提供下載。
由於建表的時候沒有指定分隔符,所以這兩個文本文件的分隔符。
先將文件放入到linux主機中,/data/tmp路徑下。
導入本地數據
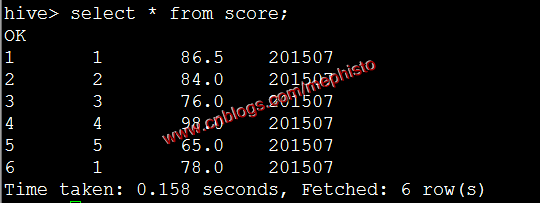
load data local inpath '/data/tmp/score_7.txt' overwrite into table score PARTITION (openingtime=201507);
我們發現001變成了1這是以為表的那一類為int形,所以轉成int了。
將score_8.txt 放到集群中
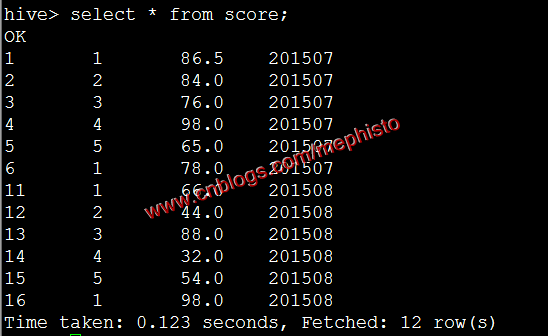
su hdfs hadoop fs -put score_8.txt /tmp/input導入集群數據
load data inpath '/tmp/input/score_8.txt' overwrite into table score partition(openingtime=201508);

將其他表的查詢結果導入表
一:語法
Standard syntax: INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement; Hive extension (multiple inserts): FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...; FROM from_statement INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] ...; Hive extension (dynamic partition inserts): INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement; INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement;
二:OVERWRITE
使用該參數,如果被導入的表或者分區中有相同的內容,則該內容被替換,否者直接跳過。
三:INSERT INTO
該語法從0.80才開始支持,它會保持目標表,分區的原有的數據的完整性。
四:實戰
我們構造一個和score表結構一樣的表score1
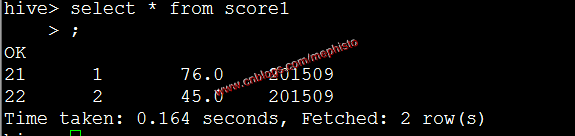
create table score1 ( id int, studentid int, score double ) partitioned by (openingtime string);插入數據
insert into table score1 partition (openingtime=201509) values (21,1,'76'),(22,2,'45');
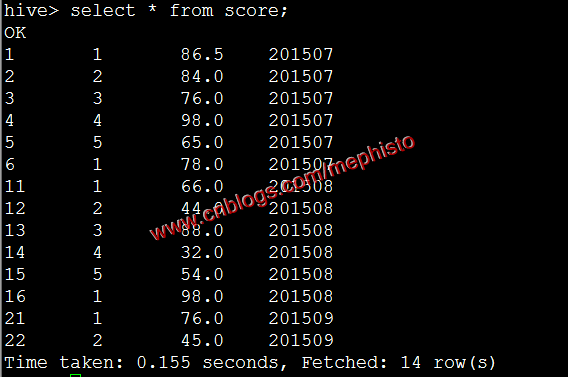
我們將表score1的查詢結果導入到score中,這裡指定了201509分區。
insert overwrite table score partition (openingtime=201509) select id,studentid,score from score1;
動態分區插入
一:說明
本來動態分區插入屬於將其他表結果插入的內容,但是這個功能實用性很強,特將其單獨列出來闡述。該功能從Hive 0.6開始支持。
二:參數
動態分區參數會在該命令生命周期內有效,所以一般講修改的參數命令放在導入之前執行。
Property Default Note hive.error.on.empty.partition false Whether to throw an exception if dynamic partition insert generates empty results hive.exec.dynamic.partition false Needs to be set to trueto enable dynamic partition insertshive.exec.dynamic.partition.mode strict In strictmode, the user must specify at least one static partition in case the user accidentally overwrites all partitions, innonstrictmode all partitions are allowed to be dynamichive.exec.max.created.files 100000 Maximum number of HDFS files created by all mappers/reducers in a MapReduce job hive.exec.max.dynamic.partitions 1000 Maximum number of dynamic partitions allowed to be created in total hive.exec.max.dynamic.partitions.pernode 100 Maximum number of dynamic partitions allowed to be created in each mapper/reducer node 三:官網例子
我們可以下看hive官網的例子
FROM page_view_stg pvs INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country) SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip, pvs.cnt在這裡country分區將會根據pva.cut的值,被動態的創建。註意,這個分區的名字是沒有被使用過的,在
nonstrict模式,dt這個分區也可以被動態創建。四:實戰
我們先清空score表的數據(3個分區)
insert overwrite table score partition(openingtime=201507,openingtime=201508,openingtime=201509) select id,studentid,score from score where 1==0;
將7月8月數據插入到score1
load data local inpath '/data/tmp/score_7.txt' overwrite into table score1 partition(openingtime=201507); load data local inpath '/data/tmp/score_8.txt' overwrite into table score1 partition(openingtime=201508);
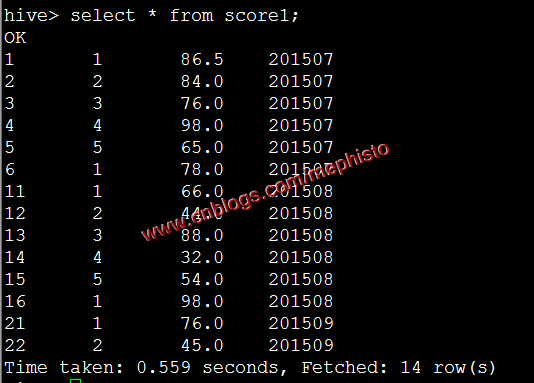
設置自動分區等參數
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions.pernode=10000;將score1的數據自動分區的導入到score
insert overwrite table score partition(openingtime) select id,studentid,score,openingtime from score1;圖片

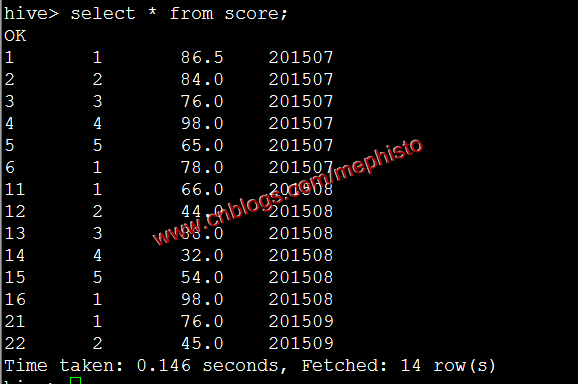
將SQL語句的值插入到表中
一:說明
該語句可以直接將值插入到表中。
二:語法
Standard Syntax: INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...] Where values_row is: ( value [, value ...] ) where a value is either null or any valid SQL literal三:官網例子
CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2)) CLUSTERED BY (age) INTO 2 BUCKETS STORED AS ORC; INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney rubble', 32, 2.32); CREATE TABLE pageviews (userid VARCHAR(64), link STRING, came_from STRING) PARTITIONED BY (datestamp STRING) CLUSTERED BY (userid) INTO 256 BUCKETS STORED AS ORC; INSERT INTO TABLE pageviews PARTITION (datestamp = '2014-09-23') VALUES ('jsmith', 'mail.com', 'sports.com'), ('jdoe', 'mail.com', null); INSERT INTO TABLE pageviews PARTITION (datestamp) VALUES ('tjohnson', 'sports.com', 'finance.com', '2014-09-23'), ('tlee', 'finance.com', null, '2014-09-21');四:實戰
在將其他表數據導入到表中的例子中,我們新建了表score1,並且通過SQL語句將數據插入到score1中。這裡就只是將上面的步驟重新列舉下。
插入數據
insert into table score1 partition (openingtime=201509) values (21,1,'76'),(22,2,'45');
--------------------------------------------------------------------
到此,本章節的內容講述完畢。
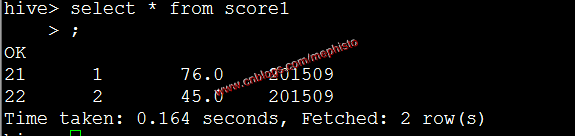
模擬數據文件下載
Github https://github.com/sinodzh/HadoopExample/tree/master/2016/hive%20test%20file
系列索引
本文版權歸mephisto和博客園共有,歡迎轉載,但須保留此段聲明,並給出原文鏈接,謝謝合作。
文章是哥(mephisto)寫的,SourceLink


