
一、HBase的特點是什麼 1.HBase一個分散式的基於列式存儲或者行式存儲的資料庫,基於hadoop的hdfs存儲,zookeeper進行管理。 2.HBase適合存儲半結構化或非結構化數據,對於數據結構欄位不夠確定或者雜亂無章很難按一個概念去抽取的數據。 3.HBase為null的記錄不會被存 ...
一、HBase的特點是什麼 1.HBase一個分散式的基於列式存儲或者行式存儲的資料庫,基於hadoop的hdfs存儲,zookeeper進行管理。 2.HBase適合存儲半結構化或非結構化數據,對於數據結構欄位不夠確定或者雜亂無章很難按一個概念去抽取的數據。 3.HBase為null的記錄不會被存儲. 4.數據存儲模式為key,value模式:(Table,Rowkey,Column,Timestamp)-> value 5.HBase是主從架構。Hmaster作為主節點,Hregionserver作為從節點。 二、HBase存數據流程
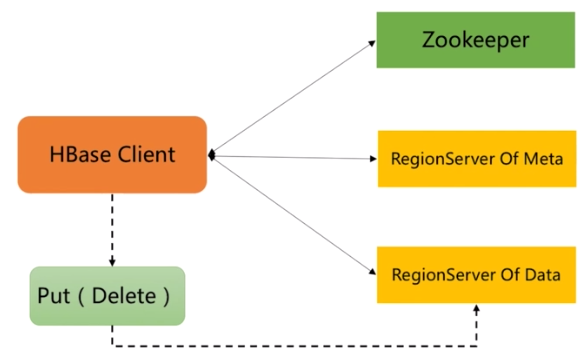
流程:Client請求Zookeeper確定meta表所在的RegionServer所在的地址,接著根據Rowkey找到數據所歸屬的RegionServer;用戶提交put或delete請求時HbaseClient會將put或delete請求添加到本地buffer中,符合一定條件 會通過非同步批量提交伺服器處理。 接著數據到達Region後,服務端處理流程如下:

流程:RegionServer去獲取RowLock,region更新共用鎖;接著Hbase會先寫寫日誌WAL(數據可靠性)再寫緩存MemStore(閾值預設64M,每個列族對應一個Store下的MemStore);然後釋放鎖後將日誌落到HDFS;若MemStore達到閾值則將緩存數據落磁碟StoreFile,最後多個StoreFile發生合併;若StoreFile很大會觸發split操作,將當前region分割成2個Region,並同步到Hmaster。 三、HBase取數據流程 HbaseClient的操作和存數據類似
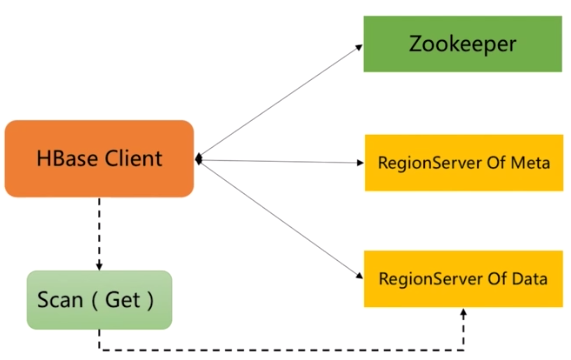
伺服器操作流程:
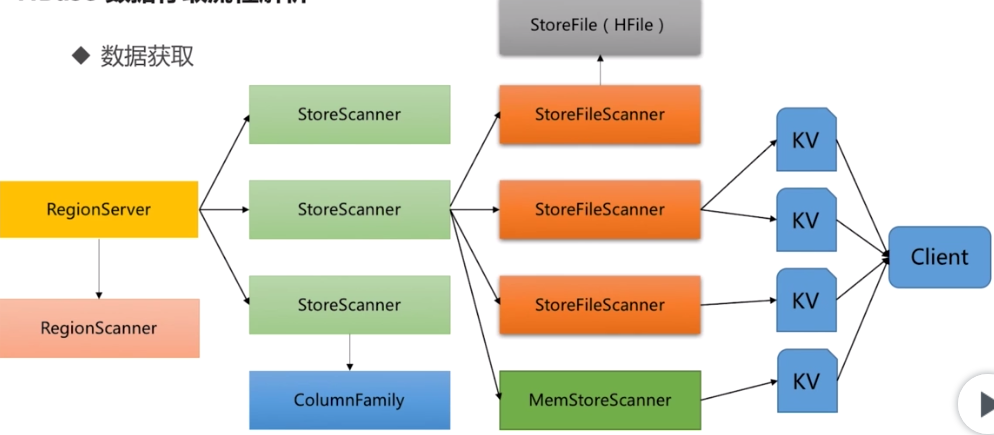
RegionServer收到get請求後,對當前Region進行Scan,接著會根據列族對Store進行Scan,同時會對對應的MemStore進行Scan;最後找到我們要的數據返回給Client。註意:一個StoreScanner會對應多個StoreFileScanner,整個過程是一個層級關係。
四、HBase存取優化 檢索優化(BloomFilter):應用BloomFilter來提高隨機讀的性能,BloomFilter是列族級別的配置 五、HBase API使用





