
1.創建表並插入數據 在Sql Server2008中創建測試資料庫Test,接著創建資料庫表並插入數據,sql代碼如下: 執行完上述sql代碼以後我們會發現在Test資料庫中多出了一張emp_pay表,資料庫表的內容如下圖所示: 2.無索引查找 從上圖我們可以看出資料庫中存儲的數據排列順序與我們插 ...
1.創建表並插入數據
在Sql Server2008中創建測試資料庫Test,接著創建資料庫表並插入數據,sql代碼如下:
USE Test IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'emp_pay') DROP TABLE emp_pay GO USE Test IF EXISTS (SELECT name FROM sys.indexes WHERE name = 'employeeID_ind') DROP INDEX emp_pay.employeeID_ind GO USE Test GO CREATE TABLE emp_pay ( employeeID int NOT NULL, base_pay money NOT NULL, commission decimal(2, 2) NOT NULL ) INSERT emp_pay VALUES (1, 500, .10) INSERT emp_pay VALUES (2, 1000, .05) INSERT emp_pay VALUES (6, 800, .07) INSERT emp_pay VALUES (5, 1500, .03) INSERT emp_pay VALUES (9, 750, .06)
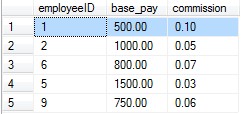
執行完上述sql代碼以後我們會發現在Test資料庫中多出了一張emp_pay表,資料庫表的內容如下圖所示:
2.無索引查找
從上圖我們可以看出資料庫中存儲的數據排列順序與我們插入的先後順序一致。接下來我們查詢employeeID=5的欄位,執行如下sql代碼:
USE Test SELECT * FROM emp_pay where employeeID=5
在SQL SERVER MANAGEMENT STUDIO中我們點擊“顯示估計的查詢計劃”,會出現如下圖所示的查詢計劃圖:

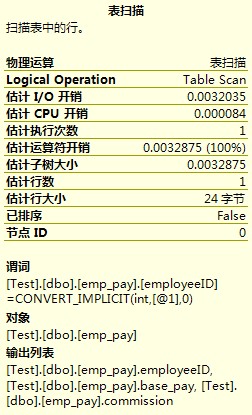
其中表掃描的內容為:
3.創建索引
接下來我們為上述表添加聚集唯一索引,代碼如下:
SET NOCOUNT OFF CREATE UNIQUE CLUSTERED INDEX employeeID_ind ON emp_pay (employeeID) GO
在執行完上述創建索引的代碼以後,我們再次查詢emp_pay的數據內容,如下圖所示:

從上圖我們可以發現數據內容已經按照employeeID進行了排序。
我們繼續執行前面關於employeeID=5的查詢,點擊“顯示估計的執行計劃”,出現如下圖所示內容:

聚集索引查找的內容為:

總結:
當我們為資料庫表中的某一個欄位創建索引,並且在查詢語句中where子句中用到這樣一個欄位,那麼查詢效率會有所提高,我們上述實驗因為數據量的關係查詢效率提高不明顯。
補充
我們上面添加的索引是唯一聚集索引,因此當插入的數據在employeeID欄位出現重覆時會報錯。假如我們在創建索引之前數據欄位出現重覆,那麼就不能創建唯一索引。
創建索引以後的排序(PS:2012-5-28)
執行如下sql語句
update emp_pay set employeeID=7 where employeeID=1;
然後再次執行全表查詢,我們發現查詢結果如下所示:
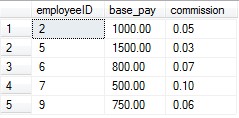
只要我們更新了employeeID,那麼最後的更新結果都會按照employeeID的值進行升序排序。這是因為我們在employeeID上創建了索引的緣故。
刪除索引(PS:2012-6-4)
我們可以通過sql server management studio這個工具刪除索引,也可以通過sql語句進行索引的刪除,假設我們要求刪除在前面創建的索引employeeID_ind,那麼sql語句如下代碼所示:
DROP INDEX employeeID_ind ON emp_pay;


