
RPC調用 多個服務協同完成一次業務時,由於業務約束(如紅包不符合使用條件、賬戶餘額不足等)、系統故障(如網路或系統超時或中斷、資料庫約束不滿足等),都可能造成服務處理過程在任何一步無法繼續,使數據處於不一致的狀態。傳統的基於資料庫本地事務的解決方案只能保障單個服務的一次處理具備原子性、隔離性、一致 ...
RPC調用
- 多個服務協同完成一次業務時,由於業務約束(如紅包不符合使用條件、賬戶餘額不足等)、系統故障(如網路或系統超時或中斷、資料庫約束不滿足等),都可能造成服務處理過程在任何一步無法繼續,使數據處於不一致的狀態。傳統的基於資料庫本地事務的解決方案只能保障單個服務的一次處理具備原子性、隔離性、一致性與持久性,但無法保障多個分佈服務間處理的一致性
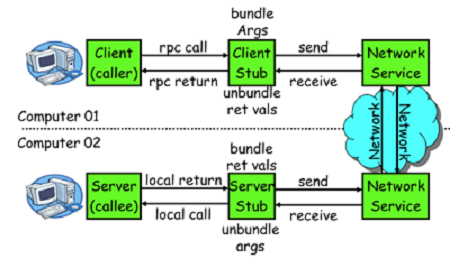
- 分析源代碼,基本原理如下:
- client 一個線程調用遠程介面,生成一個唯一的 ID (比如一段隨機字元串,UUID 等) , Dubbo 是使用 AtomicLong 從 0 開始累計數字的
- 將打包的方法調用信息(如調用的介面名稱,方法名稱,參數值列表等),和處理結果的回調對象 call back ,全都封裝在一起,組成一個對象 0bject
- 向專門存放調用信息的全局 ConcurrentHashMap 裡面 put ( ID , object )
- 將 ID 和打包的方法調用信息封裝成一對象 connRequest ,使用 Iosession.write ( connRequest )非同步發送出去
- 當前線程再使用call back 的get()方法試圖獲取遠程返回的結果,在 get()內部,則使用 Synchronized 獲取回調對象 caIlback 的鎖,再先檢測是否已經獲取到結果,如果沒有,然後調用 callbaCk 的 wait()方法,釋放 callback 上的鎖,讓當前線程處於等待狀態
- 服務端接收到請求並處理後,將結果(此結果中包含了前面的 ID ,即回傳)發送給客戶端,客戶端 socket連接上專門監聽消息的線程收到消息,分析結果,取到 ID ,再從前面的ConcurrentHashMap裡面 get(ID) ,從而找到 callback ,將方法調用結果設置到 callback 對象里
- 監聽線程接著使用 synchronized 獲取回調對象 callback 的鎖(因為前面調用過 wait ( ) ,那個線程已釋放 callback 的鎖了),再 notlfyAll ( ) ,喚醒前面處於等待狀態的線程繼續執行( call back 的 get ( )方法繼續執行就能拿到調用結果了),至此,整個過程結束
- 當前線程怎麼讓它暫停,等結果回來後,再向後執行?
- 先生成一個對象obj ,在一個全局 map 里 put ( 1D obj )存放起來,再用synchronized獲取obj鎖,再調用obj.wait()讓當前線程處於等待狀態,然後另一消息監聽線程等到服務端結果來了後,再 map.get (ID )找到 obj ,再用 synchronized獲取obj 鎖,再調用obj.notifyAll喚配前面處於等待狀態的線程
- Socket 通信是一個全雙工的方式,如果有多個線程同時進行遠程方法調用,這時建立在client server之間的socket連接上會有很多雙方發送的消息有傳遞,前後順序也可能是亂七八嘈的,server處理完結果後,將結果消息發送給 client, client收到很多消息,怎麼知道消息結果是原先哪個線程調用的? 使用一個ID ,讓其唯一,然後傳遞給服務端,再服務端又回傳回來,這樣就知道結果是原先哪個線程的了
GC垃圾回收
大多數剛創建的對象會被分配在Eden區,當Eden區滿的時候,執行Minor GC,將消亡的對象清理掉,並將剩餘的對象複製到一個存活區Survivor0,當Survivor0也滿的時候,將其中仍然活著的對象直接複製到Survivor1,以後Eden區執行Minor GC後,就將剩餘的對象添加Survivor1,當兩個存活區切換了幾次(HotSpot虛擬機預設15次,用-XX:MaxTenuringThreshold控制,大於該值進入老年代)之後,仍然存活的對象將被覆制到老年代年輕代收集器
- Serial收集器:“停止-複製”演算法,單線程,進行垃圾收集時必須暫停其他線程的所有工作
- ParNew收集器:Serial收集器的多線程版本,“停止-複製”演算法,多線程
- Parallel Scavenge收集器:”停止-複製“演算法,並行的多線程收集器,可控制的吞吐量
老年代收集器
- Serial Old:Serial收集器的老年代版本,同樣是一個單線程收集器,使用“標記-整理”演算法
- Parallel Old收集器:Parallel Scavenge收集器的老年代版本,使用多線程和“標記-整理”演算法
- CMS收集器:CMS(Conrrurent Mark Sweep)收集器是以獲取最短回收停頓時間為目標的收集器,使用"標記-清除"演算法
CMS收集器
- 初始標記:標記GCRoots能直接關聯到的對象,時間很短
- 併發標記:進行GCRoots Tracing(可達性分析)過程,時間很長
- 重新標記:修正併發標記期間因用戶程式繼續運作而導致標記產生變動的那一部分對象的標記記錄,時間較長
- 併發清除:清除未標記(無關聯引用)的對象,伴隨著用戶線程的執行,清除後會產生浮動垃圾
- 優缺點:對CPU資源非常敏感,可能會導致應用程式變慢,吞吐率下降,無法處理浮動垃圾,採用的“標記-清除”演算法,會產生大量的記憶體碎片
垃圾回收演算法實現
- 停止-複製演算法:將記憶體分為兩塊,當其中一塊記憶體用完了,將還存活著的對象複製到另一塊中,再將使用過的記憶體一次性清理掉
- 標記-清除演算法:首先標記出所有需要回收的對象,標記完成後統一回收所有被標記的對象
- 標記-整理演算法:讓所有存活對象都向一端移動,然後直接清理掉邊界以外的記憶體


