
一、目錄結構樹 總體概述 代碼檢測工具sonar HDBS代碼優化 總結開發註意點 二、總體概述 進入現在這家公司我的第一個任務就是對HDBS進行代碼質量優化。HDBS可能大家不是很瞭解,現在給大家簡單介紹下:HDBS是HadoopBaseService的簡稱,Hadoop有瞭解過大數據的朋友相信並 ...
一、目錄結構樹
- 總體概述
- 代碼檢測工具sonar
- HDBS代碼優化
- 總結開發註意點
二、總體概述
進入現在這家公司我的第一個任務就是對HDBS進行代碼質量優化。HDBS可能大家不是很瞭解,現在給大家簡單介紹下:HDBS是HadoopBaseService的簡稱,Hadoop有瞭解過大數據的朋友相信並不陌生,BaseService自然也就是基礎服務的意思;所以HDBS這個服務主要是基礎服務的配置,同時Hadoop則表示數據量的大。以下是我暫時瞭解的應用架構圖方便各位理解,畢竟才來這個公司一個星期可能畫的不是很完整不過總體就是這麼回事:

二、代碼檢測工具
-
前提描述
這篇文章側重講HDBS代碼存在的質量問題,至於怎麼用、怎麼搭建sonar代碼異常檢測平臺後續再講。
-
SonarQube簡介
SonarQube系統是一個代碼質量檢測工具,主要用於檢測代碼的編寫質量,比如:覆蓋率、是否包含空指針異常、異常是否正確處理、map的遍歷優化、是否包含無用代碼塊占據cpu資源等。 由以下四個組件組成(https://docs.sonarqube.org/display/SONAR/Architecture+and+Integration)
- 一個sonarqube伺服器 包含三個子進程(web服務(界面管理),搜索服務 計算引擎服務(寫入資料庫))
- 一個sonarqube資料庫 配置sonarqube服務
- 多個sonarqube插件 位於解壓目錄 extensions\plugins目錄
- 一個或者多個sonarqube scanners 用於分析特定的項目
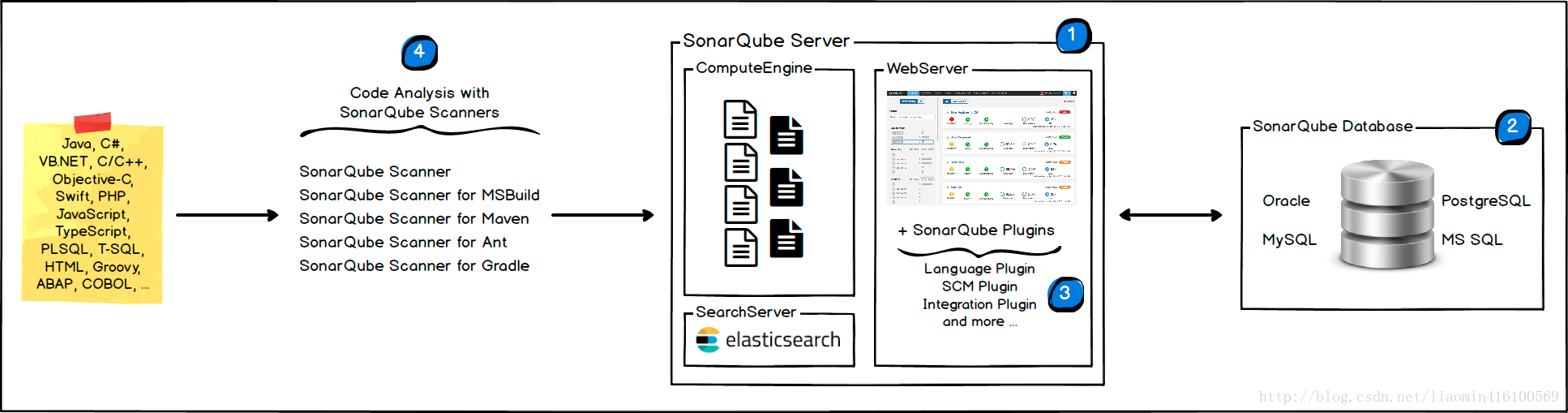
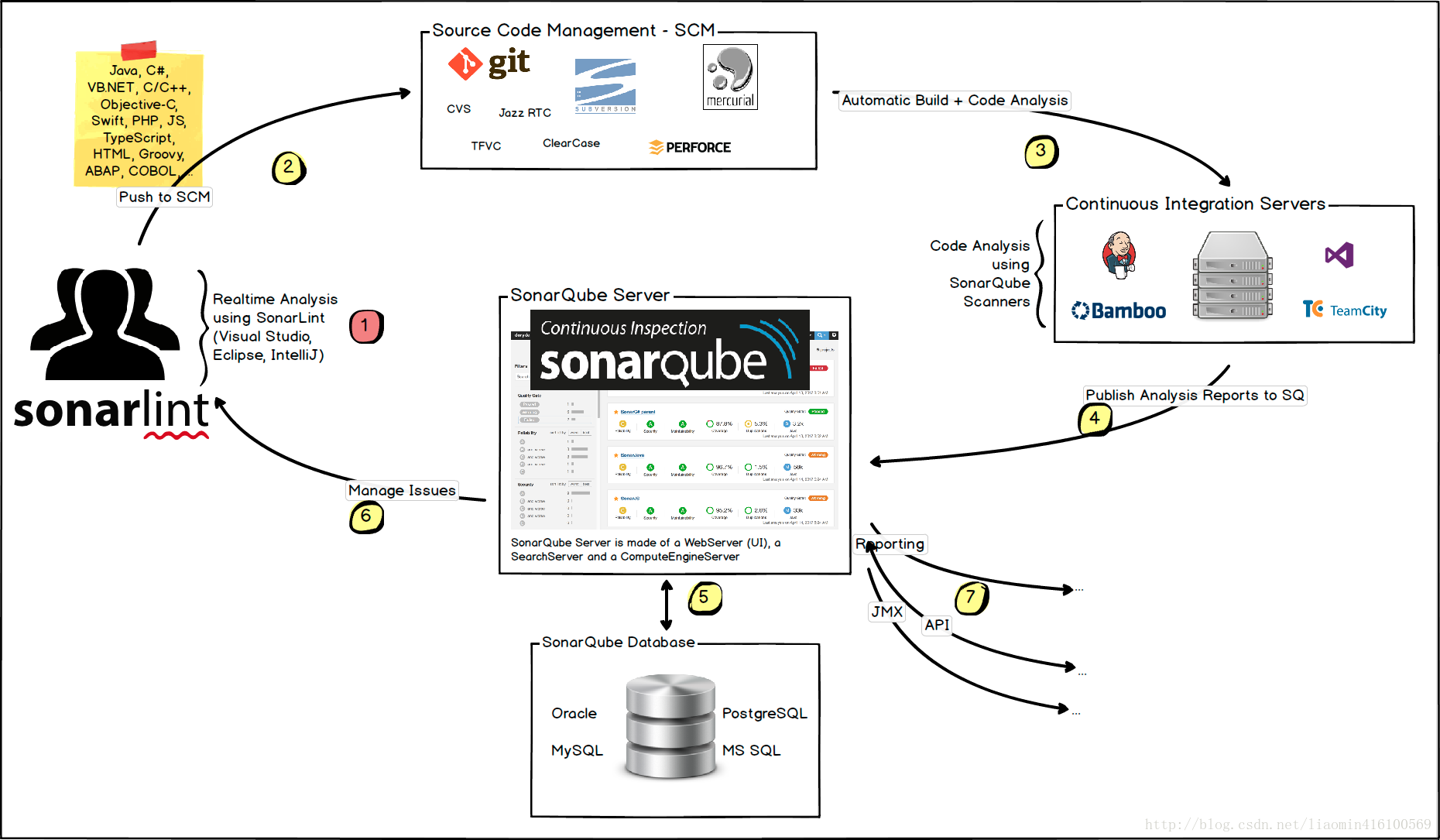
- 使用SonarQube(簡稱SQ)工作流程
開發者使用開發工具(eclipse,ide)上傳代碼到SCM(源代碼管理器) 系統自動同步代碼到某個位置 sonarqube scanners 掃描該代碼檢查質量 將分析結果 將分析結果推送到SQServer 存儲在SQ資料庫 用戶可以使用eclipse插件sonarlint來同步sonarqube伺服器配置(java和js版本等)可以實時線上分析。
三、HDBS代碼優化
- 代碼優化的重要性
通過sonar代碼檢測平臺針對性地解決代碼中相關問題。在大項目中代碼質量尤為重要,雖然這些代碼問題並不是錯誤,在正常的數據情況下是不會發生問題的,但是也有很多情況是數據不正常的時候;一個小小的bug可能導致成千上萬的訂單作廢,性能的優化也很重要因為性能的優化可以使得QPS顯著上升,代碼問題最為嚴重的就可能導致整個實例掛掉(JVM異常退出)。所以代碼質量的提升是重中之重。
- 如何優化
由於HDBS是經由不同的開發人員之手總體代碼質量參差不其,雖然公司有一套開發手冊但是執行起來似乎比較難;但是事實告訴我們:開發中要儘可能第按照公司開發手冊,如果沒有就要按照通用的開發規範進行開發,比如遵循阿裡的開發規範,畢竟大公司走過的路躺過的坑還是比較多的我們要學會站在巨人的肩膀上往上爬。作為程式員開發效率其實是第一位,在實際開發中我們要學會使用工具來取得開發的最大效率,比如:這裡我們採用sonar來管理代碼質量問題、可以用SourceTree來管理git代碼等;合理使用對應的工具可以達到開發效率的最大化,畢竟公司要的是一個能夠有產出的人,如果你一天能夠解決的問題而別人需要兩天那麼你就能得到上司的賞識。
四、總結開發註意點
- HDBS代碼中發現的問題(部分)
- 異常沒有正確處理。比如:直接在代碼中使用e.printStackTrace代碼列印異常;這是有一個問題就是:這些代碼在本地啟動遇到異常後是可以正常列印異常信息,但是當應用部署到Linux伺服器的時候卻可能不會列印,這如果線上上生產環境發生問題需要盤查的時候就尷尬了,因為你可能根本找不到異常的信息也就是說系統壓根就沒有記錄任何異常信息。
解決方法:LOGGER.error("xx異常:{}",e) - 可能發生NullPointerException。比如:前面的代碼定義了 Map<Object,Object> map=null; 但後面在沒有判斷obj是否為null的情況下進行map.size()的操作;這也是我們需要註意的地方,這種代碼邏輯一般我們是不會進行異常處理的,異常處理要遵循:能夠不需要異常處理就不要用異常處理不能把異常處理當做工具來使用。這種情況下如果沒判斷為null就進行操作就會發生運行時異常當前線程就會意外終止。
解決方法:先判斷是否為null - Map的遍歷方式優化。在開發中我見過很多人是這樣遍歷Map的:先得到keySet()視圖,然後遍歷keys,通過get(key)的方式來獲取對應的value。這種遍歷性能其實是很差的,因為我們在遍歷keys的時候需要花費一定的時間,在get(key)的時候又會花費一定的時間;我們都知道Map的get()是要計算hashCode然後通過hashCode計算數組的下標,如果有hash衝突又會遍歷鏈表,這種遍歷方式顯然是低效的,cpu資源是寶貴的這種方式會嚴重占用cpu並且時間花費的要長得多。
解決方法:通過entrySet()獲取key、value視圖,一次遍歷就可以獲取對應的value,而不需要通過get();不過你也可以用迭代遍歷,這都是可以的。 - 日誌列印不規範。比如:LOGGER.info(“請求參數:”+params.toString); 日誌是盤查問題的關鍵信息,所以在一個系統中無處不在,一個線程可能產生的log數量就是成百上千行,如果每條日誌都這麼列印的話會嚴重影響整個應用的性能。因為字元串拼接的性能是很差的,相信我們都對String不陌生,像這種String c=a+b的方式性能有多好自己也清楚。
解決方法:LOGGER.info(“請求參數:{}”,params.toString) - 沒有考慮線程安全問題。如:在多線程系統應用HashMap;線程安全的概念簡單來講就是:同一個代碼塊在單線程和多線程的執行情況下的結果是一樣的,否則線程非安全。如果在多線程系統應用了HashMap可能導致多個線程之間數據混淆或者是嚴重占用系統資源,占用系統資源即為發生了迴圈鏈表的問題,具體為什麼產生迴圈鏈表這裡就不多加闡述了;同時String、StringBuffer、StringBuilder也類似。
解決方法:用HashTable或者ConCurrentHashMap替換HashMap - 無效代碼。比如:Date date=new Date(),在判斷date是否是空的時候用if( date!=null && !"".equal(date));我們都知道date是Date類型永遠也不可能是String類型,但是在寫代碼的時候我們卻又一個習慣喜歡加上"".equal(date)來判斷,當然這麼寫是不會有錯的,雖然Date不是Strng但是由於 is-a的原則他們的父類都是Object,而equal是Object的方法所以那樣判斷自然也沒有錯。這裡講的不單單是Date這個類型,如果是非String類型都這樣;還有就是當我們使用List<String> list=new ArrayList<>的方式的時候,後續用list這個對象的時候不需要判斷是否為null,因為new出來的對象在沒有被JVM回收之前引用的對象永遠是非null。
解決方法:去除無效代碼 - 合理使用同步鎖。比如:全局定義了一個private static final DateFormat df=new SimpleDateFormat(“yyyy-MM-dd HH:MM:ss”)變數; 在該類中使用到df對象的時候都應用了同步鎖;如果線上程並大量大的時候同步鎖會嚴重占用系統資源的開銷,因為獲得鎖與釋放鎖的過程都是需要占用資源的同時也會帶來併發量的下降,所以在能不用同步鎖解決問題的時候儘可能不使用鎖,萬不得已的時候就可以使用。
解決方法:去除同步鎖,在方法中定義局部變數:DateFormat df=new SimpleDateFormat(“yyyy-MM-dd HH:MM:ss”)

