
數據集猶如世界歷史狀態的快照,能幫助我們捕捉不斷變化的事物,而數據可視化則是將複雜數據以簡單的形式展示給用戶的良好手段(或媒介)。結合個人書中所學與實際工作所學,對數據可視化過程做了一些總結形成本文供各位看客"消遣"。 個人以為數據可視化服務商業分析的經典過程可濃縮為:從業務與數據出發,經過數據分析 ...
數據集猶如世界歷史狀態的快照,能幫助我們捕捉不斷變化的事物,而數據可視化則是將複雜數據以簡單的形式展示給用戶的良好手段(或媒介)。結合個人書中所學與實際工作所學,對數據可視化過程做了一些總結形成本文供各位看客"消遣"。

個人以為數據可視化服務商業分析的經典過程可濃縮為:從業務與數據出發,經過數據分析與可視化形成報告,再跟蹤業務調整回到業務,是個經典閉環。
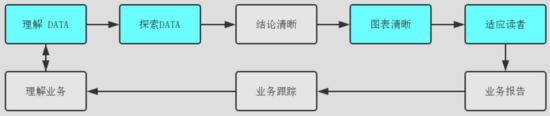
本文主題為數據可視化,將重點講解與數據可視化相關的環節,也即上圖中藍色的環節。
一、理解 DATA
進行 DATA 探索前,我們需先結合業務去理解 DATA,這裡推薦運用 5W1H 法,也即在拿到數據後問自身以下幾個問題:
- Who: 是誰搜集了此數據? 在企業內可能更關註是來自哪個業務系統。
- How: 是如何採集的此數據? 儘可能去瞭解詳細的採集規則,採集規則是影響後續分析的重要因素之一。如:數據來自埋點,來自後端還是前端差異很大,來自後端則多是實時的,來自前端則需更近一步瞭解數據在什麼網路狀態會上傳、無網路狀態下又是如何處理的。
- What: 是關於什麼業務什麼事? 數據所描述的業務主題。
- Why: 為什麼搜集此數據? 我們想從數據中瞭解什麼,其實也就是我們此次分析的目標。
- When: 是何時段內的業務數據?
- Where: 是何地域範圍內的業務數據?
通過回答以上幾個問題,我們能快速瞭解:數據來源是什麼?它的可信度有多少?它在描述何時發生的怎樣的業務(問題)?我們為什麼要搜集此數據?等等。從而快速瞭解數據與業務開展近一步的探索與分析。
二、探索 DATA
之前的文章中,我們曾經分享過如何快速地探索 DATA ( 「如何成為一名數據分析師:數據的初步認知」 ),其中有談到如何通過諸如平均數/中位數/眾數等描述統計、通過相關係數統計快速探索 DATA 的方法。本文主要講解可視化,所以將從可視化的角度去介紹如何通過可視化方法進行數據探索。
在探索、研究階段,更重要的是要從不同的角度去觀察數據,並逐步深入到對業務更重要的事情上。在這個階段,我們不必去過多地追求圖表美化,而應該儘可能快速地嘗試更多個角度。下麵我們根據數據/主題類型的差異分開闡述:
1. 分類數據的探索
在業務分析中,我們常常將人群、地點和其他事物進行分類,分類能為我們帶來結構化,能讓我們快速掌握信息。
在分類數據可視化中,我們最多使用的是條形圖;但當試圖觀察分類中的比例時,我們可能也會選擇餅圖、瀑布圖;當不僅關心一級分類還關心子分類時候,我們可能會選擇樹形圖。通過對分類數據的可視化,我們能快速地獲取最大、最小值,同時也能方便地瞭解到數據集的範圍,因為它在一定程度上還反映了數據分佈特征。下圖展示了可視化分類數據的一些選擇:
a. 條形圖,用長度作為視覺暗示,利於直接比較。
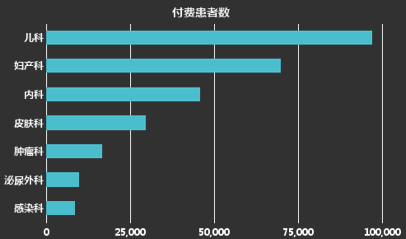
b. 使用餅圖、柱形堆疊圖、瀑布圖等,能在分類數據中對比占比情況。
c. 使用樹形圖,能在展示一級分類的子類統計,可實現維度的又一層下鑽。

2. 時序數據的探索
業務分析中,我們常常關心事物隨著時間的變化趨勢,以及數據隨時間變化的規律(時間周期下的規律)。所以,對時序數據的探索,主要有兩種模式:其一為隨著時間線索向右延伸的時序圖,諸如:折線圖、堆積面積圖等;其二為根據時間周期,統計彙總的柱形圖、日曆圖、徑向圖等。
a. 用於觀察事物隨時間線索變化的探索。
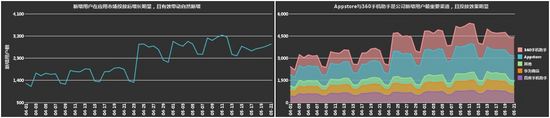
b. 用於發現事物隨時間周期變化規律的探索。
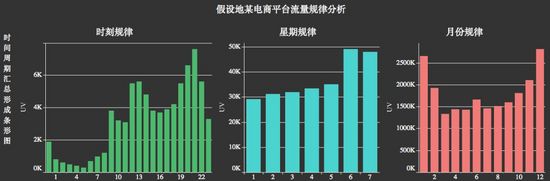
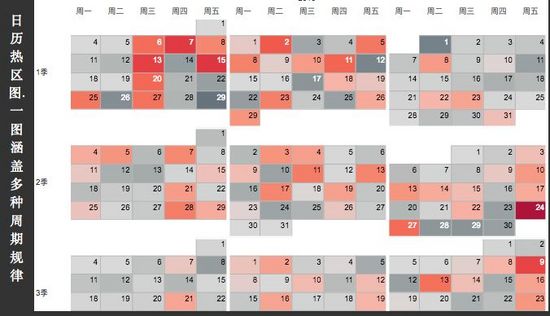
3. 空間數據的探索
空間數據探索主要是期望展現或者發現業務事件在地域分佈上的規律,即區域模式。全球數據通常按照國家分類,而國內數據則按照省份去分類,對於省份數據則按照市、區分類,以此類推,逐步向細分層次下鑽。空間數據探索最常用為等值熱力圖,如下:
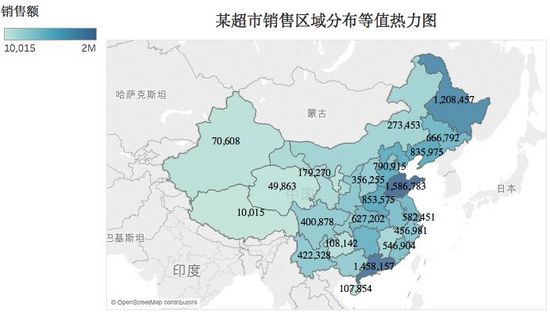
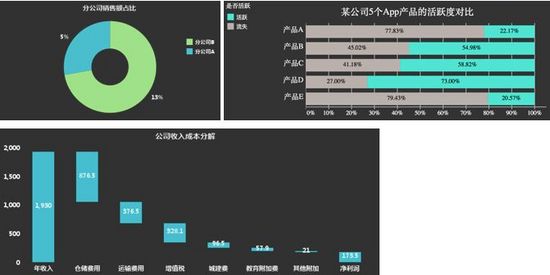
4. 多元變數的探索
數據探索過程中,有時候我們需要對比多個個體多個變數,從而尋找數據個體間的差異或者數據變數間的關係。在這種情況下,我們推薦使用散點圖、氣泡圖,或者將多個簡單圖表組合生成“圖矩陣”,通過對比“圖矩陣”來進行多元變數的探索。其中,散點圖和氣泡圖適合變數相對較少的場景,對於變數5個及以上的場景我們更多地是推薦“圖矩陣”。
a. 變數相對較少(5個以下)的場景我們採用散點圖與氣泡圖。

b. 變數多(5個及以上)的場景我們採用多個簡單圖表組成的“圖矩陣”,下圖為最簡單的“圖矩陣”多元熱力圖:
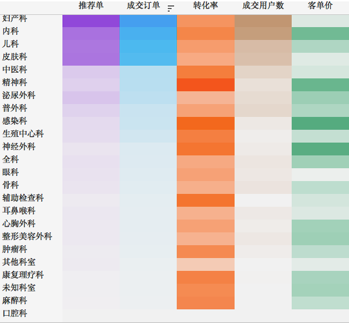
5. 數據分佈的探索
探索數據的分佈,能幫助我們瞭解數據的整體的區間分佈、峰值以及谷值以及數據是否穩定等等。
之前在分類數據探索階段曾提到分類清晰的條形圖在一定程度上向我們反映了數據的分佈信息。但,之前我們是對類別做的條形圖,更多時候我們是需查看數據“坐落區間”,這裡我們推薦直方圖以及直方圖的變型密度曲線圖(密度曲線圖,上學時代學的正態分佈就常用密度曲線圖繪製)。此外,對數據分佈探索有一個更為科學的圖表類型,那就是:箱線圖。
三、圖表清晰
1. 合理"搭配"可視化的組件
所謂可視化,其實就是根據數據,用標尺、坐標系、各種視覺暗示以及背景信息描述進行組合來表現數據。下圖為可視化組件的“框架圖”:
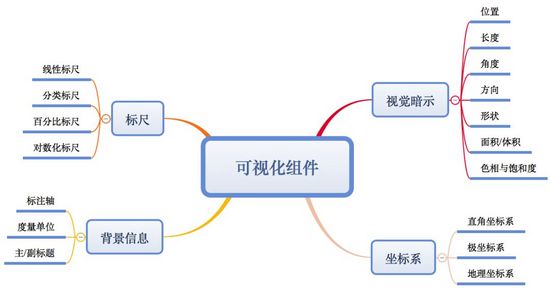
a. 視覺暗示
可視化最基本的形式就是簡單地將數據映射成圖形,大腦可以在數字與圖形間來回切換從而尋找模式。所以我們必須選擇合適的視覺暗示來保證數據的本質沒有在大腦地來回切換中丟失,並且儘可能讓大腦能輕鬆獲得信息。

從上到下,對人腦而言視覺暗示清晰程度逐漸降低。
位置
使用位置作視覺暗示時,大腦是在比較給定空間或者坐標系中數值的位置。它的優勢在於占用空間會少於其他視覺暗示,但劣勢也很明顯,我們很難去辨別每一個點代表什麼。所以,應用位置作為視覺暗示主要用於發現趨勢規律或者群集分佈規律,散點圖是位置作為視覺暗示的典型運用。
長度
使用長度作為視覺暗示,大腦的理解模式是條形越長,絕對值越大。優點非常明顯人眼對於長度的“感受”往往是最準確的。條形圖是長度作為視覺暗示的最常見圖表。
角度
使用角度作為視覺暗示,大腦的理解模式為兩向量如何相交,相交角度是否大於90度或180度。角度作為視覺暗示的最常見圖表式餅圖。
方向
使用方向作為視覺暗示,大腦的理解模式為坐標系中一個向量的方向。在折線圖中顯示為斜率,在遷徙圖中顯示為箭頭所指方向。
形狀
使用形狀作為視覺暗示,對大腦而言往往代表著不同的對象或者類別。可用於在散點圖中區分不同群集。
面積/體積
使用面積/體積作為視覺暗示,面積大則絕對值大。需要註意的一點是,用面積顯示2倍關係時,應該是面積乘倍而不是邊長乘倍。
色相與飽和度
不同的顏色通常用來表示分類數據,每個顏色代表一個分組;不同的色相通暢用來表示連續數據,常見模式是顏色越深代表數值越大。
b. 坐標系
- 直角坐標系:絕大多數的圖表都在直角坐標系中完成,它是最常用的坐標系。在直角坐標系中,關註的兩個點之間的距離,距離是歐式距離。
- 極坐標系:極坐標系是顯示角度的坐標系,如果用過餅圖那麼就已經接觸過極坐標系了。
- 地理坐標系:簡單點理解,它由經緯度組成,將世界各地的位置顯示在圖表中,因與現實世界直接相關而倍受喜愛。
c. 標尺
標尺的重要性在於與坐標系一起決定了圖形的投影方式。
- 線性標尺:間距處處相等,無論處於什麼位置,是大眾最熟悉、最容易接受的標尺,不容易產生誤解;
- 分類標尺:分類數據往往採用分類標尺,如:年齡段、性別、學歷等等,值得註意的一點是,對於有序的分類,我們應儘量對分類標尺做排序以適應讀者的閱讀模式;
- 百分比標尺:其實仍舊是線性標尺,只是刻度值為百分比;
- 對數標尺:指按照對數化將坐標軸壓縮,適合數值跨度非常大的場景。但需考慮讀者是否能夠適應對數標尺,畢竟它並不常見。
d. 背景信息
背景信息,所指即我們在理解 DATA 通過 “5W1H” 法回答的問題。包括數據背景與業務背景。
基本的原則是,如果信息在圖形元素中沒有得到巧妙地暗示,我們久需要通過標註坐標軸、註明度量單位,添加額外說明等方法來告訴讀者圖表中每一個數據及其視覺暗示代表什麼。
2. 美化,讓可視化更為清晰
在研究階段,我們重點嘗試從各種不同的角度切入去觀察數據,沒有過多地考慮表達是否準確,圖形是否美觀。
但,當我們進展到準備將分析報告呈現給業務方或領導時,必須對可視化圖表進行優化使其是清晰易讀的。否則,我們很可能要挨批了。
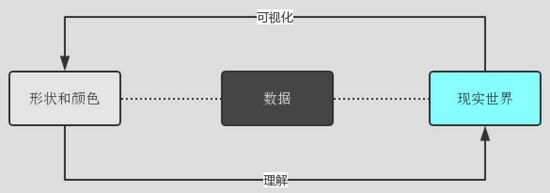
上圖為,數據可視化與現實世界的連接關係。清晰易讀的可視化一定是在儘可能地減少讀者從可視化圖表理解轉換為現實世界的難度。而增強數據比較、合理註解引導、減少讀者理解步驟是達成這一目的的良好手段,下麵為大家詳細展開介紹:
a. 增強數據比較,降低大腦進行信息比較的難度
當我們在閱讀可視化圖表時,我們的大腦會自然地進行比較從而獲取信息。增強數據比較,可有效降低信息比較難度,使大腦更容易抓住關鍵信息,減少模凌兩可,使大腦獲取信息更具確定性。
建立視覺層次,用醒目的顏色突出數據,淡化其他元素
有層次感的圖表更易讀,用戶能更快地抓住圖表中的重點信息。相反,扁平圖則缺少流動感,讀者相對較難理解。建立視覺層次,我們可以用醒目的顏色突出顯示數據,並淡化其他元素使其作為背景,淡化元素可採用淡色系或虛線。
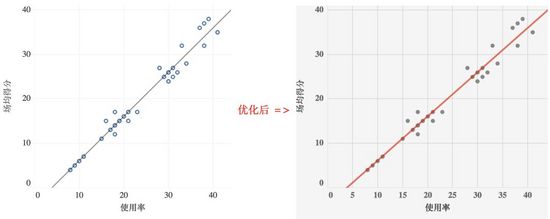
散點圖的目標是為尋找規律與模式,擬合數據線是下圖的關鍵。弱化數據點、強化擬合趨勢線使其形成鮮明的2個層次。
高亮顯示重點內容
高亮顯示可以幫助讀者在茫茫數據中一下找到重點。它既可以加深人們對已看到數據的印象,也可以讓人們關註到那些應該註意的東西。需要註意的是,使用“高亮”突出顯示時,我們應儘可能使用當前圖表中尚未使用的視覺暗示。
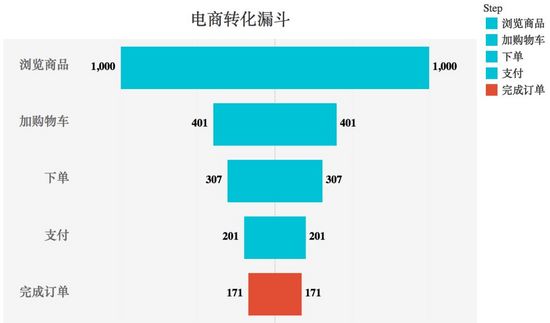
下麵為常見的電商轉化漏斗,其中下單步驟是最應當關註的環節,使用紅色高亮能會使讀者的目光快速落在這一關鍵步驟中。
其他技巧
除了以上介紹兩大增強比較技巧,我們可以通過以下一些小技巧來增強數據比較:
- 提升色階跨度,倘若圖表中所用顏色色階跨度太小,我們將難以區分差異,合理提升色階跨度能有效增強比較;
- 合理增大標尺跨度,有時候我們只需要對標尺做合理地放大,數據差異將清晰好幾倍;
- 添加參考線(建議採用虛線),參考線作為對比基準,可有效增強數值與基準的比較。
b. 合理註解與引導,使讀者快速理解圖表信息並抓住信息重點
僅通過圖形元素,我們很難向讀者展示充分的信息,合理增加註解能有效幫助讀者理解圖表;增加適當的箭頭等符號引導能幫助讀者快速抓住關鍵信息。
合理註解:背景信息、分析結論以及統計學概念
- 如果報表的讀者對數據、業務背景並不十分熟悉,我們應考慮在標題或其他報告文字中直接說明背景。
- 如果是結論性圖表,我們可在主標題中直接說明結論。如果結論得出的過程較複雜,我們還可以在副標題中輔助說明是如何推導得到的結論。
- 如果圖表中,有大部分讀者都不熟悉的統計學概念,我們應適當地進行註解,以幫助讀者瞭解相關概念。
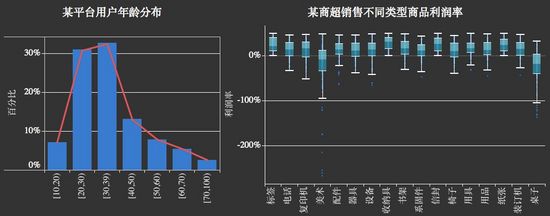
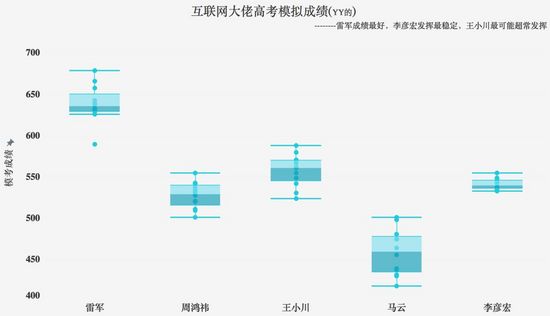
下圖,主標題數據背景註解讓讀者快速瞭解業務背景,副標題說明結論能有效引導讀者朝著什麼方向去閱讀圖表
合理增加引導:增加適當的箭頭指向
分析階段,我們是報表的製作者;彙報階段,我們是報告的講解者。我們可以將自身作為報告的導游,引導讀者按照我們的期望去閱讀圖表。而增加箭頭等符號的引導是最直接有效的方式。
c. 通過引入計算、視覺暗示直接符合讀者“背景暗示”等方法可有效降低讀者理解步驟
創造性地從不同角度進行計算
有時,我們只需在圖表上先做一個圖表計算就可以讓圖表離結論更近一個層次,從而減少讀者從可視化圖表到現實世界的理解步驟。常見的可用計算包括:平均值計算、環比增長率、基準點上下、累加統計等。
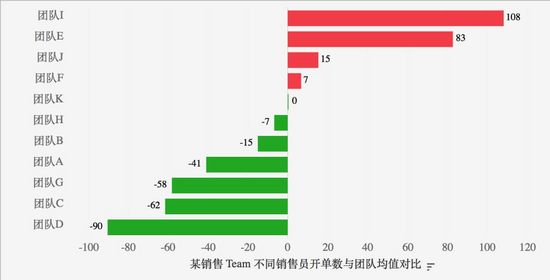
示例1:將員工銷售業績與團隊均值做差值,快速辨別員工的銷售表現
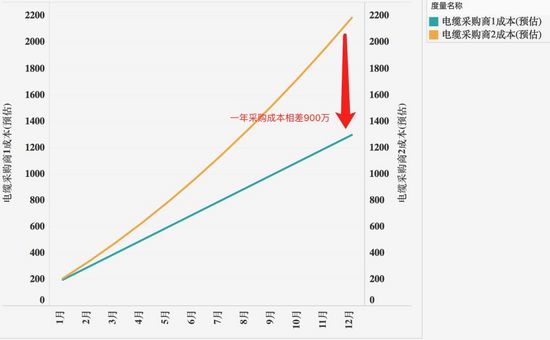
示例2:將2個採購商的採購成本按照一年累計彙總後可使採購成本差異更顯著
選擇符合讀者“背景期望”的視覺暗示
人在世界上生存久了都會形成一定的潛意識,有一些潛意識是“人群通用的”,在可視化過程中,我們應該合理運用。比如:在失業、就業統計中,失業用負數表示,就業用正數表示,就是一種符合大多數人“背景期望”的一種場景。
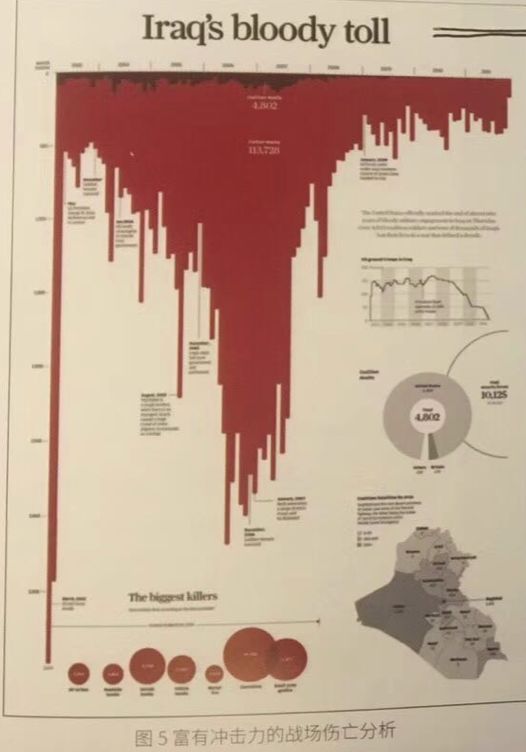
示例1: 之前在一本書中看到的一個關於伊拉克戰爭可視化。此圖的主題在於批判戰爭的殘酷造成了巨大的傷亡,所以作者採用了與血液相同的紅色作為主色調,倒掛的柱形也能給人以壓抑感,同樣符合“背景期望”。
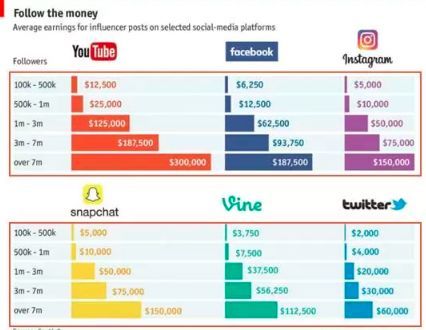
示例2: 之前一位同事分享的一個關於美國一些互聯網平臺網紅收入的可視化。在色彩上它直接採用對應互聯網平臺自身logo的色系。符合人的“背景期望”閱讀過程將非常輕鬆。
四、適應讀者
別忘了,我們的可視化是為讀者進行的,我們應考慮目標讀者的特點製作他們易於、樂於理解的可視化。尤其要避免的一個陷阱是:過分追求新穎圖表,反而使得圖表難以理解,結果違背了可視化的初衷。
為讀者而可視化,要求我們試圖去瞭解讀者,瞭解他們對可視化的偏好,尤其是能夠接受新穎的圖表類型,以及他們對業務的理解程度等等。
此外,還有一個非常關鍵且通用的建議:讓我們的報告以講故事的方式展開,我們自身則作為這個報告的導游,合理有效地引導讀者看完你創造的“分析故事”。
好,以上即為個人對數據可視化服務商業分析的過程所有總結。


