
最近在練習寫爬蟲的時候,正巧同學的女朋友有需求,大概是爬取知網內的幾千個主題的數據,每一個主題的條數記錄有幾條的到幾千條的不等,總來的來說也算是個上萬數量級的爬蟲了,分析了下知網,發現使用專業檢索,可以完成我的目標,然後通過chrome的developer tools大概分析了下了請求數據包,發現知 ...
最近在練習寫爬蟲的時候,正巧同學的女朋友有需求,大概是爬取知網內的幾千個主題的數據,每一個主題的條數記錄有幾條的到幾千條的不等,總來的來說也算是個上萬數量級的爬蟲了,分析了下知網,發現使用專業檢索,可以完成我的目標,然後通過chrome的developer tools大概分析了下了請求數據包,發現知網的查詢是分成兩步的,第一步是一個總的請求(查詢的條件基本上都在第一步裡面了),會返回一個串

然後才能做第二步的數據請求(下方的截圖對應網頁上的不同區域的請求報文頭和返回數據)
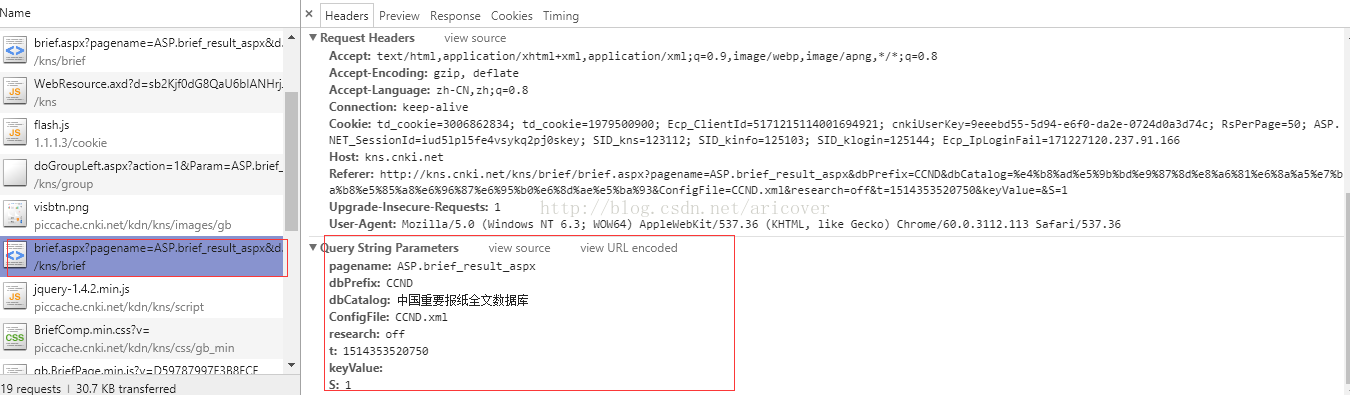
圖一.查詢記錄請求報文頭

圖二. 對應不同年份的記錄條數返回結果
至於為什麼要分成兩步,每一個區域對應一個不同的請求,這些都是網站本身的設計,我也沒做過web開發,這麼做有哪些優點我確實不清楚/擦汗,我的重點就是模擬它在網頁上的請求,實現批量化的數據獲取。
然後,大概就摸清楚了這一個數據獲取的過程,我的思路是先完成一個數量級的數據獲取,也就是爬取一條,然後再去擴展,加線程,加ip代理,加user_agent等等。
在這個階段,重要的思路就是基本上要和在網頁上的訪問保持一致,保證自己拼的url和在網頁上訪問的時候是一致的,當然是在保證能訪問的前提下,能略去的就略去。
分析它原本的請求url的時候,使用url轉碼工具可以將轉碼以後的url還原,更直白地分析。
然後提幾個細節吧,知網的請求url上,有一些數據段一開始是不明白它的意義的,但是自己去拼接訪問的時候發現,缺了網站就會報錯,這時候就可以多嘗試幾個不同的訪問,去拿它的請求heads,然後互相對比,就會發現有的欄位是固定不變的,這種就可以直接照搬,有的呢,是變化的,這種就需要仔細去分析到底是什麼數據,有什麼意義,知網的就包括一個毫秒數,這個我一開始就沒懂具體意義,後來分析了下感覺像時間,然後去取了下當前的毫秒時間,一對比發現大概是差不多,就當前的毫秒時間拼在了url串上面。
def getMilliTim(): t = time.time() nowTime = t*1000 return int(nowTime)
如果你需要一個良好的學習交流環境,那麼你可以考慮Python學習交流群:548377875; 如果你需要一份系統的學習資料,那麼你可以考慮Python學習交流群:548377875。
總而言之,就是對於不怎麼懂web的爬蟲小白,最好就是還原網站原本的請求,這樣基本上請求數據就不會有太大問題了。
在完成了數量級為一的級別後,就開始準備大範圍地獲取數據了,這時候就要思考效率以及防止網站踢人了。
在遭遇了各種socket 10054 10061等錯誤,通過百度各種技巧,加上了ip代理等一些措施,最終我還是完成本次任務,當然最後還是加上了文件讀取,任務隊列等模塊,大概就是一個線程專門負責輸出文件,其它四個線程去任務池裡面取任務爬數據,詳細略過,見代碼。有紕漏之處,還請斧正。


