
1、B+樹基本概念 B+樹的語言定義比較複雜,簡單的說是為磁碟存取設計的平衡二叉樹 網上經典圖,黃色p1 p2 p3代表指針,藍色的代表磁碟,裡面包含數據項,第一層17,35,p1就代表小於17的,p2就代表17-35之間的,p3就代表大於35的,可是需要註意的是,第三層才是真實的數據,17、35都 ...
1、B+樹基本概念
B+樹的語言定義比較複雜,簡單的說是為磁碟存取設計的平衡二叉樹
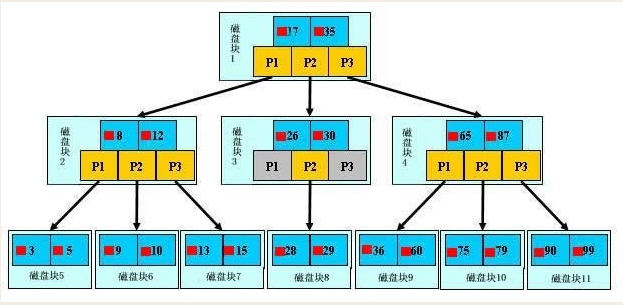
網上經典圖,黃色p1 p2 p3代表指針,藍色的代表磁碟,裡面包含數據項,第一層17,35,p1就代表小於17的,p2就代表17-35之間的,p3就代表大於35的,可是需要註意的是,第三層才是真實的數據,17、35都不是真實數據,只是用來劃分數據的!
2、為什麼使用B+樹
B+樹有什麼好處我們非要使用它呢?那就先要來看看mysql的索引
2.1mysql索引
試想一下在mysql中有200萬條數據,在沒有建立索引的情況下,會全部進行掃描讀取,這個時間消耗是非常恐怖的,而對於大型一點的網站來說,達到這個數據量很容易,不可能這樣去設計
在我們創建資料庫表的時候,大家都知道一個東西叫做主鍵,一般來講資料庫會自動在主鍵上創建索引,這叫做主鍵索引,來看看索引的分類吧
a.主鍵索引:int優於varchar
b.普通索引(INDEX):最基本的索引,沒有限制,加速查找
c.唯一索引(UNUQUE):聽名字就知道,要求所有類的值是唯一的,但是允許有空值
d.組合索引:
1 CREATE INDEX name_age_address_Index ON `student`(`name`, `age`, `address`);
在這裡實際上包含三個索引,說到組合索引,一定要講最左首碼原則
最左首碼原則:
我們現在創建了索引x,y,z,Index:(x,y,z),只會走x,xy,xyz的查詢,例如:
1 select * from table where x='1' 2 select * from table where x='1' and b='1' 3 select * from table where x='1' and b='1' and c='1'
如果是x,z,就只會走x,註意一種特殊情況,select * from table where x='1' and y>'1' and z='1',這裡只會走xy,因為在經歷xy的篩選後,z不能保證是有序的,可索引是有序的,因此不會走z
e.全文索引(FULLTEXT):用於搜索內容很長的文章之類的很好用,如果創建普通的索引,在遇到 like='%xxx%'這種情況索引會失效
1 ALTER TABLE tablename ADD FULLTEXT(col1, col2) 2 SLECT * FROM tablename WHERE MATCH(col1, col2) AGAINST(‘x′, ‘y′, ‘z′)
這樣就可以將col1和col2裡面包含x,y,z的記錄全部取出來了
索引的刪除:DORP INDEX IndexName ON `TableName`
索引的優缺點:
1、在數據量特別龐大的時候,建立索引有助於我們提高查詢效率
2、在操作表的時候,維護索引會增加額外開銷
3、不泛濫使用索引,創建多了索引文件會膨脹很快
2.2B+樹的優點
瞭解上面的模型後,試想一下,200W條數據,假如沒有建立索引,會全部進行掃描,B+樹僅僅用三層結構可以表示上百萬的數據,只需要三次I/O!這提升是真的巨大啊!
因為B+樹是平衡二叉樹,在不斷的增加數據的時候,為了保持平衡可能需要做大量的拆分操作,因此提供了旋轉的功能,不知道旋轉建議去補一下樹的基礎知識
B+樹插入動畫(來自https://www.cnblogs.com/vincently/p/4526560.html)

3、索引優化
1、最佳左首碼原則
2、不要在索引的列上做操作
3、like會使索引失效變成全表掃描
4、字元串不加單引號會導致索引失敗
5、減少使用select *

參照這裡,寫的很好 https://www.cnblogs.com/zhaobingqing/p/7071331.html
總結:
sql語句怎麼用,沒有規定必須怎麼查,對於數據量小,有時候不需要新建立索引,根據一定的實際情況來考慮

