
絕對和你在網上看到的CAP定理介紹不一樣。 CAP 定理(CAP theorem)又被稱作布魯爾定理(Brewer's theorem),是加州大學伯克利分校的電腦科學家埃里克·布魯爾(Eric Brewer)在 2000 年的 ACM PODC 上提出的一個猜想。2002 年,麻省理工學院的賽斯 ...
絕對和你在網上看到的CAP定理介紹不一樣。
CAP 定理(CAP theorem)又被稱作布魯爾定理(Brewer's theorem),是加州大學伯克利分校的電腦科學家埃里克·布魯爾(Eric Brewer)在 2000 年的 ACM PODC 上提出的一個猜想。2002 年,麻省理工學院的賽斯·吉爾伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)發表了布魯爾猜想的證明,使之成為分散式計算領域公認的一個定理。
對於設計分散式系統的架構師來說,CAP 是必須掌握的理論。
為了更好地解釋 CAP 理論,我特意去大佬的博客看了下,作為參考基礎。
(http://robertgreiner.com/about)
Robert Greiner 對 CAP 的理解也經歷了一個過程,他寫了兩篇文章來闡述 CAP 理論,第一篇被標記為“outdated”(網上絕大部分解鎖都止於第一篇)
我們先看下第一版和第二版的差異
第一版
Any distributed system cannot guaranty C, A, and P simultaneously.
對於一個分散式計算系統,不可能同時滿足一致性(Consistence)、可用性(Availability)、分區容錯性(Partition Tolerance)三個設計約束。
1. 一致性(Consistency)
All nodes see the same data at the same time.
所有節點在同一時刻都能看到相同的數據。
2. 可用性(Availability)
Every request gets a response on success/failure.
每個請求都能得到成功或者失敗的響應。
3. 分區容忍性(Partition Tolerance)
System continues to work despite message loss or partial failure.
出現消息丟失或者分區錯誤時系統能夠繼續運行。
第二版
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed.
在一個分散式系統(指互相連接並共用數據的節點的集合)中,當涉及讀寫操作時,只能保證一致性(Consistence)、可用性(Availability)、分區容錯性(Partition Tolerance)三者中的兩個,另外一個必須被犧牲。
1. 一致性(Consistency)
A read is guaranteed to return the most recent write for a given client.
對某個指定的客戶端來說,讀操作保證能夠返回最新的寫操作結果。
2. 可用性(Availability)
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
非故障的節點在合理的時間內返回合理的響應(不是錯誤和超時的響應)。
3. 分區容忍性(Partition Tolerance)
System continues to work despite message loss or partial failure.
當出現網路分區後,系統能夠繼續“履行職責”。
我們來詳細看下具體的差異
首先概念上第二版定義了什麼才是 CAP 理論探討的分散式系統,強調了兩點:interconnected 和 share data,為何要強調這兩點呢? 因為分散式系統並不一定會互聯和共用數據。最簡單的例如 Memcache 的集群,相互之間就沒有連接和共用數據,因此 Memcache 集群這類分散式系統就不符合 CAP 理論探討的對象;而 MySQL 集群就是互聯和進行數據複製的,因此是 CAP 理論探討的對象。
第二版強調了 write/read pair,這點其實是和上一個差異點一脈相承的。也就是說,CAP 關註的是對數據的讀寫操作,而不是分散式系統的所有功能。例如,ZooKeeper 的選舉機制就不是 CAP 探討的對象。
1. 一致性(Consistency)
第一版強調同一時刻擁有相同數據(same time + same data),第二版並沒有強調這點。
因此第一版的解釋“All nodes see the same data at the same time”是不嚴謹的。而第二版強調 client 讀操作能夠獲取最新的寫結果就沒有問題,因為事務在執行過程中,client 是無法讀取到未提交的數據的,只有等到事務提交後,client 才能讀取到事務寫入的數據,而如果事務失敗則會進行回滾,client 也不會讀取到事務中間寫入的數據。
2. 可用性(Availability)
第一版的 success/failure 的定義太泛了,幾乎任何情況,無論是否符合 CAP 理論,我們都可以說請求成功和失敗,因為超時也算失敗、錯誤也算失敗、異常也算失敗、結果不正確也算失敗;即使是成功的響應,也不一定是正確的。例如,本來應該返回 100,但實際上返回了 90,這就是成功的響應,但並沒有得到正確的結果。相比之下,第二版的解釋明確了不能超時、不能出錯,結果是合理的,
3. 分區容忍性(Partition Tolerance)
第一版用的是 work,第二版用的是 function。
work 強調“運行”,只要系統不宕機,我們都可以說系統在 work,返回錯誤也是 work,拒絕服務也是 work;而 function 強調“發揮作用”“履行職責”,這點和可用性是一脈相承的。也就是說,只有返回 reasonable response 才是 function。相比之下,第二版解釋更加明確。
雖然 CAP 理論定義是三個要素中只能取兩個,但放到分散式環境下來思考,我們會發現必須選擇 P(分區容忍)要素,因為網路本身無法做到 100% 可靠,有可能出故障,所以分區是一個必然的現象。如果我們選擇了 CA 而放棄了 P,那麼當發生分區現象時,為了保證 C,系統需要禁止寫入,當有寫入請求時,系統返回 error(例如,當前系統不允許寫入),這又和 A 衝突了,因為 A 要求返回 no error 和 no timeout。因此,分散式系統理論上不可能選擇 CA 架構,只能選擇 CP 或者 AP 架構。
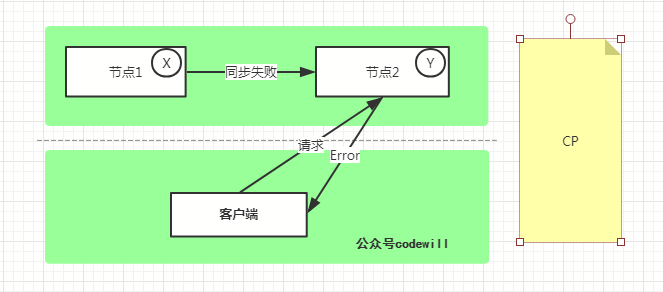
1.CP - Consistency/Partition Tolerance
如下圖所示,為了保證一致性,當發生分區現象後, 節點1上的數據無法同步到 節點2, 節點2上的數據還是 Y。這時客戶端 C 訪問 節點2時,節點2 需要返回 Error,提示客戶端 “系統現在發生了錯誤”,這種處理方式違背了可用性(Availability)的要求,因此 CAP 三者只能滿足 CP。
2.AP - Availability/Partition Tolerance
如下圖所示,為了保證可用性,當發生分區現象後, 節點1上的數據無法同步到 節點2, 節點2上的數據還是 Y。這時客戶端 訪問 節點2 時,節點2 將當前自己擁有的數據 Y 返回給客戶端,而實際上當前最新的數據已經是 X了,這就不滿足一致性(Consistency)的要求了,因此 CAP 三者只能滿足 AP。

如果你看到了這裡,那拿出手機掃一掃,關註我,一起成長! (不定期送書哦)


