
以下內容基於jdk1.7.0_79源碼; 繼承自HashMap,一個有序的Map介面實現,這裡的有序指的是元素可以按插入順序或訪問順序排列; 與HashMap的異同:同樣是基於散列表實現,區別是,LinkedHashMap內部多了一個雙向迴圈鏈表的維護,該鏈表是有序的,可以按元素插入順序或元素最近訪
以下內容基於jdk1.7.0_79源碼;
什麼是LinkedHashMap
繼承自HashMap,一個有序的Map介面實現,這裡的有序指的是元素可以按插入順序或訪問順序排列;
LinkedHashMap補充說明
與HashMap的異同:同樣是基於散列表實現,區別是,LinkedHashMap內部多了一個雙向迴圈鏈表的維護,該鏈表是有序的,可以按元素插入順序或元素最近訪問順序(LRU)排列,
簡單地說:LinkedHashMap=散列表+迴圈雙向鏈表
LinkedHashMap的數組結構
用畫圖工具簡單畫了下散列表和迴圈雙向鏈表,如下圖,簡單說明下:
第一張圖是LinkedHashMap的全部數據結構,包含散列表和迴圈雙向鏈表,由於迴圈雙向鏈表線條太多了,不好畫,簡單的畫了一個節點(黃色圈出來的)示意一下,註意左邊的紅色箭頭引用為Entry節點對象的next引用(散列表中的單鏈表),綠色線條為Entry節點對象的before, after引用(迴圈雙向鏈表的前後引用);
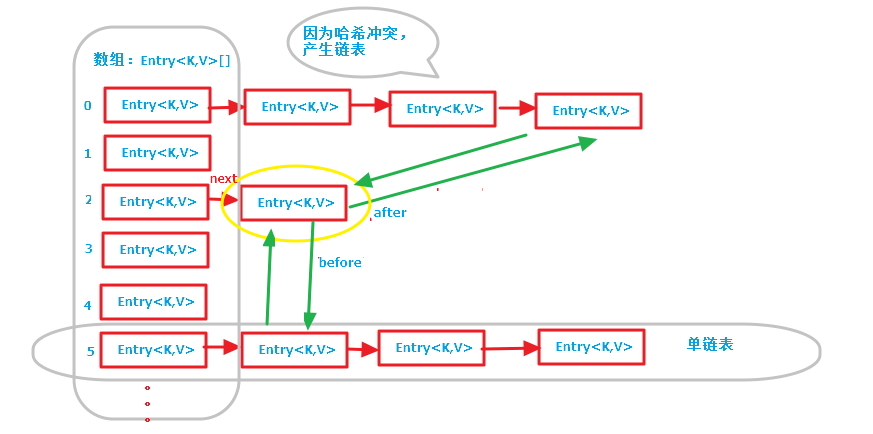
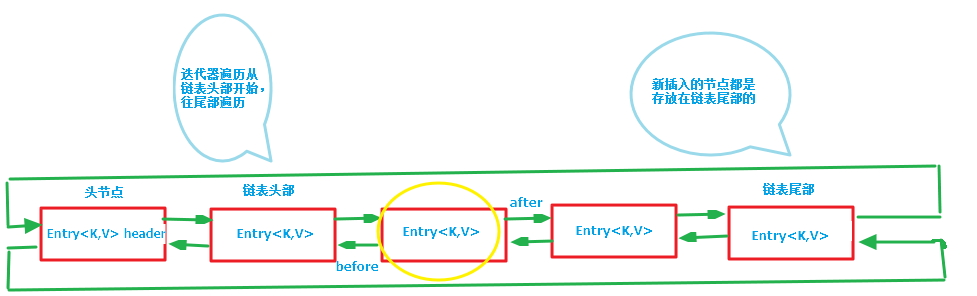
第二張圖專門把迴圈雙向鏈表抽取出來,直觀一點,註意該迴圈雙向鏈表的頭部存放的是最久訪問的節點或最先插入的節點,尾部為最近訪問的或最近插入的節點,迭代器遍歷方向是從鏈表的頭部開始到鏈表尾部結束,在鏈表尾部有一個空的header節點,該節點不存放key-value內容,為LinkedHashMap類的成員屬性,迴圈雙向鏈表的入口;
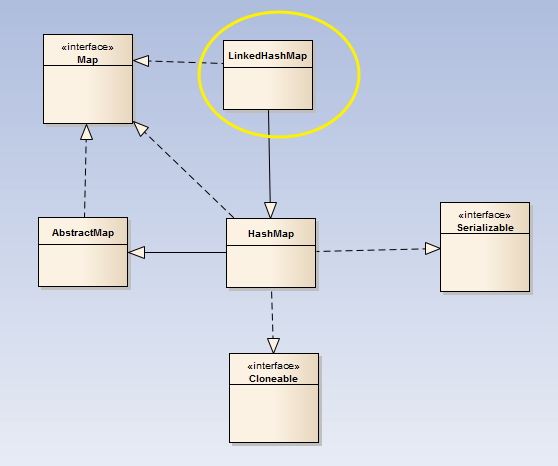
LinkedHashMap繼承的類與實現的介面
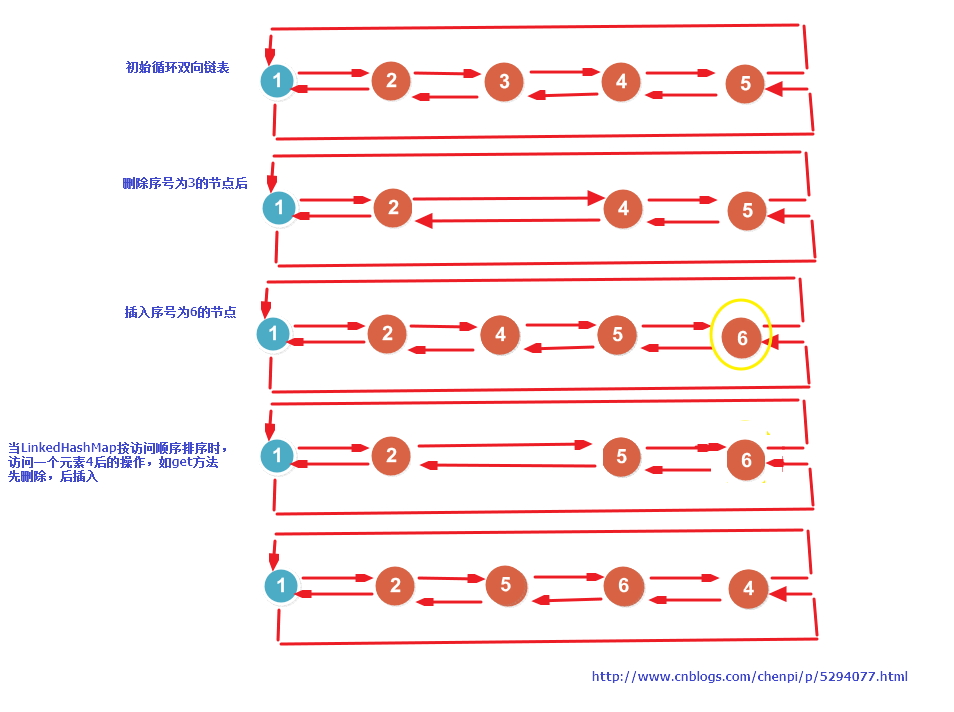
LinkedHashMap源碼中雙向鏈表的操作
同樣畫了一張圖,主要是插入刪除、操作,如下圖,應該挺好理解的,鏈表的操作
LinkedHashMap源碼解析,基本全部加了註釋,建議看之前,先看HashMap的源碼
package java.util; import java.io.*; public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> { private static final long serialVersionUID = 3801124242820219131L; /** * 雙向迴圈鏈表, 頭結點(空節點) */ private transient Entry<K,V> header; /** * accessOrder為true時,按訪問順序排序,false時,按插入順序排序 */ private final boolean accessOrder; /** * 生成一個空的LinkedHashMap,並指定其容量大小和負載因數, * 預設將accessOrder設為false,按插入順序排序 */ public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } /** * 生成一個空的LinkedHashMap,並指定其容量大小,負載因數使用預設的0.75, * 預設將accessOrder設為false,按插入順序排序 */ public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } /** * 生成一個空的HashMap,容量大小使用預設值16,負載因數使用預設值0.75 * 預設將accessOrder設為false,按插入順序排序. */ public LinkedHashMap() { super(); accessOrder = false; } /** * 根據指定的map生成一個新的HashMap,負載因數使用預設值,初始容量大小為Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY) * 預設將accessOrder設為false,按插入順序排序. */ public LinkedHashMap(Map<? extends K, ? extends V> m) { super(m); accessOrder = false; } /** * 生成一個空的LinkedHashMap,並指定其容量大小和負載因數, * 預設將accessOrder設為true,按訪問順序排序 */ public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; } /** * 覆蓋HashMap的init方法,在構造方法、Clone、readObject方法里會調用該方法 * 作用是生成一個雙向鏈表頭節點,初始化其前後節點引用 */ @Override void init() { header = new Entry<>(-1, null, null, null); header.before = header.after = header; } /** * 覆蓋HashMap的transfer方法,性能優化,這裡遍歷方式不採用HashMap的雙重迴圈方式 * 而是直接通過雙向鏈表遍歷Map中的所有key-value映射 */ @Override void transfer(HashMap.Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //遍歷舊Map中的所有key-value for (Entry<K,V> e = header.after; e != header; e = e.after) { if (rehash) e.hash = (e.key == null) ? 0 : hash(e.key); //根據新的數組長度,重新計算索引, int index = indexFor(e.hash, newCapacity); //插入到鏈表表頭 e.next = newTable[index]; //將e放到索引為i的數組處 newTable[index] = e; } } /** * 覆蓋HashMap的transfer方法,性能優化,這裡遍歷方式不採用HashMap的雙重迴圈方式 * 而是直接通過雙向鏈表遍歷Map中的所有key-value映射, */ public boolean containsValue(Object value) { // Overridden to take advantage of faster iterator if (value==null) { for (Entry e = header.after; e != header; e = e.after) if (e.value==null) return true; } else { for (Entry e = header.after; e != header; e = e.after) if (value.equals(e.value)) return true; } return false; } /** * 通過key獲取value,與HashMap的區別是:當LinkedHashMap按訪問順序排序的時候,會將訪問的當前節點移到鏈表尾部(頭結點的前一個節點) */ public V get(Object key) { Entry<K,V> e = (Entry<K,V>)getEntry(key); if (e == null) return null; e.recordAccess(this); return e.value; } /** * 調用HashMap的clear方法,並將LinkedHashMap的頭結點前後引用指向自己 */ public void clear() { super.clear(); header.before = header.after = header; } /** * LinkedHashMap節點對象 */ private static class Entry<K,V> extends HashMap.Entry<K,V> { // 節點前後引用 Entry<K,V> before, after; //構造函數與HashMap一致 Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } /** * 移除節點,並修改前後引用 */ private void remove() { before.after = after; after.before = before; } /** * 將當前節點插入到existingEntry的前面 */ private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; } /** * 在HashMap的put和get方法中,會調用該方法,在HashMap中該方法為空 * 在LinkedHashMap中,當按訪問順序排序時,該方法會將當前節點插入到鏈表尾部(頭結點的前一個節點),否則不做任何事 */ void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; //當LinkedHashMap按訪問排序時 if (lm.accessOrder) { lm.modCount++; //移除當前節點 remove(); //將當前節點插入到頭結點前面 addBefore(lm.header); } } void recordRemoval(HashMap<K,V> m) { remove(); } } //迭代器 private abstract class LinkedHashIterator<T> implements Iterator<T> { //初始化下個節點引用 Entry<K,V> nextEntry = header.after; Entry<K,V> lastReturned = null; /** * 用於迭代期間快速失敗行為 */ int expectedModCount = modCount; //鏈表遍歷結束標誌,當下個節點為頭節點的時候 public boolean hasNext() { return nextEntry != header; } //移除當前訪問的節點 public void remove() { //lastReturned會在nextEntry方法中賦值 if (lastReturned == null) throw new IllegalStateException(); //快速失敗機制 if (modCount != expectedModCount) throw new ConcurrentModificationException(); LinkedHashMap.this.remove(lastReturned.key); lastReturned = null; //迭代器自身刪除節點,並不是其他線程修改Map結構,所以這裡要修改expectedModCount expectedModCount = modCount; } //返回鏈表下個節點的引用 Entry<K,V> nextEntry() { //快速失敗機制 if (modCount != expectedModCount) throw new ConcurrentModificationException(); //鏈表為空情況 if (nextEntry == header) throw new NoSuchElementException(); //給lastReturned賦值,最近一個從迭代器返回的節點對象 Entry<K,V> e = lastReturned = nextEntry; nextEntry = e.after; return e; } } //key迭代器 private class KeyIterator extends LinkedHashIterator<K> { public K next() { return nextEntry().getKey(); } } //value迭代器 private class ValueIterator extends LinkedHashIterator<V> { public V next() { return nextEntry().value; } } //key-value迭代器 private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> { public Map.Entry<K,V> next() { return nextEntry(); } } // 返回不同的迭代器對象 Iterator<K> newKeyIterator() { return new KeyIterator(); } Iterator<V> newValueIterator() { return new ValueIterator(); } Iterator<Map.Entry<K,V>> newEntryIterator() { return new EntryIterator(); } /** * 創建節點,插入到LinkedHashMap中,該方法覆蓋HashMap的addEntry方法 */ void addEntry(int hash, K key, V value, int bucketIndex) { super.addEntry(hash, key, value, bucketIndex); // 註意頭結點的下個節點即header.after,存放於鏈表頭部,是最不經常訪問或第一個插入的節點, //有必要的情況下(如容量不夠,具體看removeEldestEntry方法的實現,這裡預設為false,不刪除),可以先刪除 Entry<K,V> eldest = header.after; if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } } /** * 創建節點,並將該節點插入到鏈表尾部 */ void createEntry(int hash, K key, V value, int bucketIndex) { HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<>(hash, key, value, old); table[bucketIndex] = e; //將該節點插入到鏈表尾部 e.addBefore(header); size++; } /** * 該方法在創建新節點的時候調用, * 判斷是否有必要刪除鏈表頭部的第一個節點(最不經常訪問或最先插入的節點,由accessOrder決定) */ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; } }


