
資料庫的配置 1 django預設支持sqlite,mysql, oracle,postgresql資料庫。 <1> sqlite django預設使用sqlite的資料庫,預設自帶sqlite的資料庫驅動 , 引擎名稱:django.db.backends.sqlite3 <2> mysql 引擎 ...
資料庫的配置
1 django預設支持sqlite,mysql, oracle,postgresql資料庫。
<1> sqlite
django預設使用sqlite的資料庫,預設自帶sqlite的資料庫驅動 , 引擎名稱:django.db.backends.sqlite3
<2> mysql
引擎名稱:django.db.backends.mysql
2 mysql驅動程式
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(純python的mysql驅動程式)
3 在django的項目中會預設使用sqlite資料庫,在settings里有如下設置:

如果我們想要更改資料庫,需要修改如下:
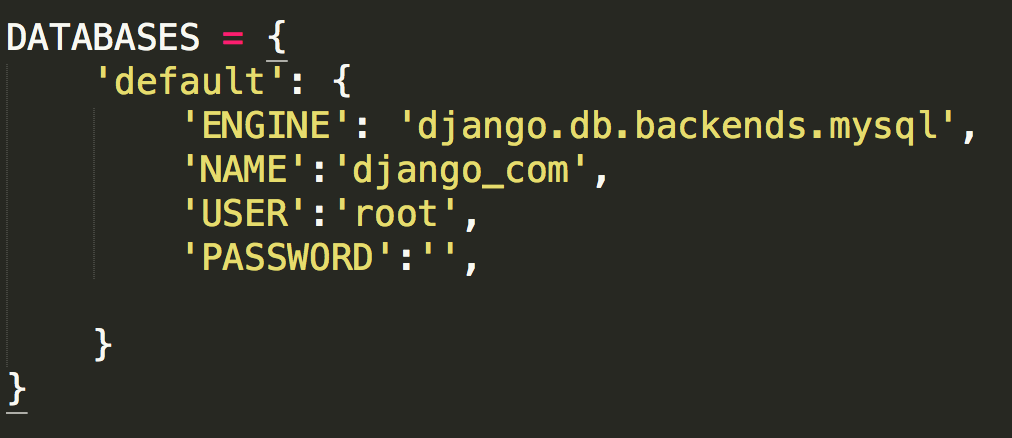
1 DATABASES = {
2
3 'default': {
4
5 'ENGINE': 'django.db.backends.mysql',
6
7 'NAME': 'books', #你的資料庫名稱
8
9 'USER': 'root', #你的資料庫用戶名
10
11 'PASSWORD': '', #你的資料庫密碼
12
13 'HOST': '', #你的資料庫主機,留空預設為localhost
14
15 'PORT': '3306', #你的資料庫埠
16
17 }
18
19 }
註意:


1 NAME即資料庫的名字,在mysql連接前該資料庫必須已經創建,而上面的sqlite資料庫下的db.sqlite3則是項目自動創建
2
3 USER和PASSWORD分別是資料庫的用戶名和密碼。
4
5 設置完後,再啟動我們的Django項目前,我們需要激活我們的mysql。
6
7 然後,啟動項目,會報錯:no module named MySQLdb
8
9 這是因為django預設你導入的驅動是MySQLdb,可是MySQLdb對於py3有很大問題,所以我們需要的驅動是PyMySQL
10
11 所以,我們只需要找到項目名文件下的__init__,在裡面寫入:
12
13 import pymysql
14 pymysql.install_as_MySQLdb()
15
16 問題解決!
View Code
ORM(對象關係映射)
用於實現面向對象編程語言里不同類型系統的數據之間的轉換,換言之,就是用面向對象的方式去操作資料庫的創建表以及增刪改查等操作。
優點: 1 ORM使得我們的通用資料庫交互變得簡單易行,而且完全不用考慮該死的SQL語句。快速開發,由此而來。
2 可以避免一些新手程式猿寫sql語句帶來的性能問題。
比如 我們查詢User表中的所有欄位:
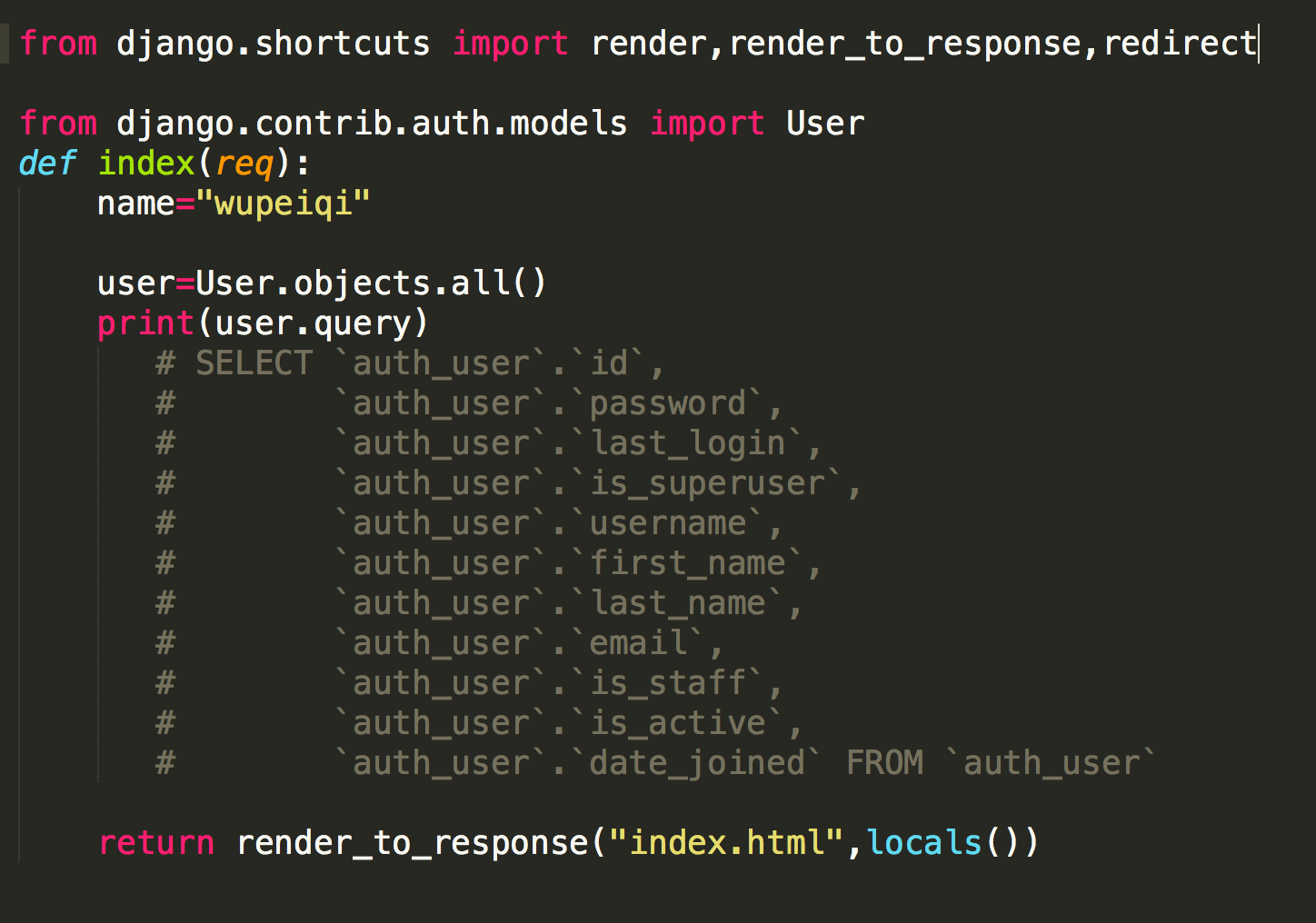
新手可能會用select * from auth_user,這樣會因為多了一個匹配動作而影響效率的。
缺點:1 性能有所犧牲,不過現在的各種ORM框架都在嘗試各種方法,比如緩存,延遲載入登來減輕這個問題。效果很顯著。
2 對於個別複雜查詢,ORM仍然力不從心,為瞭解決這個問題,ORM一般也支持寫raw sql。
3 通過QuerySet的query屬性查詢對應操作的sql語句
1 author_obj=models.Author.objects.filter(id=2)
2 print(author_obj.query)
下麵要開始學習Django ORM語法了,為了更好的理解,我們來做一個基本的 書籍/作者/出版商 資料庫結構。 我們這樣做是因為 這是一個眾所周知的例子,很多SQL有關的書籍也常用這個舉例。
表(模型)的創建:
實例:我們來假定下麵這些概念,欄位和關係
作者模型:一個作者有姓名。
作者詳細模型:把作者的詳情放到詳情表,包含性別,email地址和出生日期,作者詳情模型和作者模型之間是一對一的關係(one-to-one)(類似於每個人和他的身份證之間的關係),在大多數情況下我們沒有必要將他們拆分成兩張表,這裡只是引出一對一的概念。
出版商模型:出版商有名稱,地址,所在城市,省,國家和網站。
書籍模型:書籍有書名和出版日期,一本書可能會有多個作者,一個作者也可以寫多本書,所以作者和書籍的關係就是多對多的關聯關係(many-to-many),一本書只應該由一個出版商出版,所以出版商和書籍是一對多關聯關係(one-to-many),也被稱作外鍵。
1 from django.db import models<br>
2 class Publisher(models.Model):
3 name = models.CharField(max_length=30, verbose_name="名稱")
4 address = models.CharField("地址", max_length=50)
5 city = models.CharField('城市',max_length=60)
6 state_province = models.CharField(max_length=30)
7 country = models.CharField(max_length=50)
8 website = models.URLField()
9
10 class Meta:
11 verbose_name = '出版商'
12 verbose_name_plural = verbose_name
13
14 def __str__(self):
15 return self.name
16
17 class Author(models.Model):
18 name = models.CharField(max_length=30)
19 def __str__(self):
20 return self.name
21
22 class AuthorDetail(models.Model):
23 sex = models.BooleanField(max_length=1, choices=((0, '男'),(1, '女'),))
24 email = models.EmailField()
25 address = models.CharField(max_length=50)
26 birthday = models.DateField()
27 author = models.OneToOneField(Author)
28
29 class Book(models.Model):
30 title = models.CharField(max_length=100)
31 authors = models.ManyToManyField(Author)
32 publisher = models.ForeignKey(Publisher)
33 publication_date = models.DateField()
34 price=models.DecimalField(max_digits=5,decimal_places=2,default=10)
35 def __str__(self):
36 return self.title
View Code
註意1:記得在settings里的INSTALLED_APPS中加入'app01',然後再同步資料庫。
註意2: models.ForeignKey("Publish") & models.ForeignKey(Publish)
分析代碼:
<1> 每個數據模型都是django.db.models.Model的子類,它的父類Model包含了所有必要的和資料庫交互的方法。並提供了一個簡介漂亮的定義資料庫欄位的語法。
<2> 每個模型相當於單個資料庫表(多對多關係例外,會多生成一張關係表),每個屬性也是這個表中的欄位。屬性名就是欄位名,它的類型(例如CharField)相當於資料庫的欄位類型(例如varchar)。大家可以留意下其它的類型都和資料庫里的什麼欄位對應。
<3> 模型之間的三種關係:一對一,一對多,多對多。
一對一:實質就是在主外鍵(author_id就是foreign key)的關係基礎上,給外鍵加了一個UNIQUE=True的屬性;
一對多:就是主外鍵關係;(foreign key)
多對多:(ManyToManyField) 自動創建第三張表(當然我們也可以自己創建第三張表:兩個foreign key)
<4> 模型常用的欄位類型參數
<1> CharField
#字元串欄位, 用於較短的字元串.
#CharField 要求必須有一個參數 maxlength, 用於從資料庫層和Django校驗層限制該欄位所允許的最大字元數.
<2> IntegerField
#用於保存一個整數.
<3> FloatField
# 一個浮點數. 必須 提供兩個參數:
#
# 參數 描述
# max_digits 總位數(不包括小數點和符號)
# decimal_places 小數位數
# 舉例來說, 要保存最大值為 999 (小數點後保存2位),你要這樣定義欄位:
#
# models.FloatField(..., max_digits=5, decimal_places=2)
# 要保存最大值一百萬(小數點後保存10位)的話,你要這樣定義:
#
# models.FloatField(..., max_digits=19, decimal_places=10)
# admin 用一個文本框(<input type="text">)表示該欄位保存的數據.
<4> AutoField
# 一個 IntegerField, 添加記錄時它會自動增長. 你通常不需要直接使用這個欄位;
# 自定義一個主鍵:my_id=models.AutoField(primary_key=True)
# 如果你不指定主鍵的話,系統會自動添加一個主鍵欄位到你的 model.
<5> BooleanField
# A true/false field. admin 用 checkbox 來表示此類欄位.
<6> TextField
# 一個容量很大的文本欄位.
# admin 用一個 <textarea> (文本區域)表示該欄位數據.(一個多行編輯框).
<7> EmailField
# 一個帶有檢查Email合法性的 CharField,不接受 maxlength 參數.
<8> DateField
# 一個日期欄位. 共有下列額外的可選參數:
# Argument 描述
# auto_now 當對象被保存時,自動將該欄位的值設置為當前時間.通常用於表示 "last-modified" 時間戳.
# auto_now_add 當對象首次被創建時,自動將該欄位的值設置為當前時間.通常用於表示對象創建時間.
#(僅僅在admin中有意義...)
<9> DateTimeField
# 一個日期時間欄位. 類似 DateField 支持同樣的附加選項.
<10> ImageField
# 類似 FileField, 不過要校驗上傳對象是否是一個合法圖片.#它有兩個可選參數:height_field和width_field,
# 如果提供這兩個參數,則圖片將按提供的高度和寬度規格保存.
<11> FileField
# 一個文件上傳欄位.
#要求一個必須有的參數: upload_to, 一個用於保存上傳文件的本地文件系統路徑. 這個路徑必須包含 strftime #formatting,
#該格式將被上傳文件的 date/time
#替換(so that uploaded files don't fill up the given directory).
# admin 用一個<input type="file">部件表示該欄位保存的數據(一個文件上傳部件) .
#註意:在一個 model 中使用 FileField 或 ImageField 需要以下步驟:
#(1)在你的 settings 文件中, 定義一個完整路徑給 MEDIA_ROOT 以便讓 Django在此處保存上傳文件.
# (出於性能考慮,這些文件並不保存到資料庫.) 定義MEDIA_URL 作為該目錄的公共 URL. 要確保該目錄對
# WEB伺服器用戶帳號是可寫的.
#(2) 在你的 model 中添加 FileField 或 ImageField, 並確保定義了 upload_to 選項,以告訴 Django
# 使用 MEDIA_ROOT 的哪個子目錄保存上傳文件.你的資料庫中要保存的只是文件的路徑(相對於 MEDIA_ROOT).
# 出於習慣你一定很想使用 Django 提供的 get_<#fieldname>_url 函數.舉例來說,如果你的 ImageField
# 叫作 mug_shot, 你就可以在模板中以 {{ object.#get_mug_shot_url }} 這樣的方式得到圖像的絕對路徑.
<12> URLField
# 用於保存 URL. 若 verify_exists 參數為 True (預設), 給定的 URL 會預先檢查是否存在( 即URL是否被有效裝入且
# 沒有返回404響應).
# admin 用一個 <input type="text"> 文本框表示該欄位保存的數據(一個單行編輯框)
<13> NullBooleanField
# 類似 BooleanField, 不過允許 NULL 作為其中一個選項. 推薦使用這個欄位而不要用 BooleanField 加 null=True 選項
# admin 用一個選擇框 <select> (三個可選擇的值: "Unknown", "Yes" 和 "No" ) 來表示這種欄位數據.
<14> SlugField
# "Slug" 是一個報紙術語. slug 是某個東西的小小標記(短簽), 只包含字母,數字,下劃線和連字元.#它們通常用於URLs
# 若你使用 Django 開發版本,你可以指定 maxlength. 若 maxlength 未指定, Django 會使用預設長度: 50. #在
# 以前的 Django 版本,沒有任何辦法改變50 這個長度.
# 這暗示了 db_index=True.
# 它接受一個額外的參數: prepopulate_from, which is a list of fields from which to auto-#populate
# the slug, via JavaScript,in the object's admin form: models.SlugField
# (prepopulate_from=("pre_name", "name"))prepopulate_from 不接受 DateTimeFields.
<13> XMLField
#一個校驗值是否為合法XML的 TextField,必須提供參數: schema_path, 它是一個用來校驗文本的 RelaxNG schema #的文件系統路徑.
<14> FilePathField
# 可選項目為某個特定目錄下的文件名. 支持三個特殊的參數, 其中第一個是必須提供的.
# 參數 描述
# path 必需參數. 一個目錄的絕對文件系統路徑. FilePathField 據此得到可選項目.
# Example: "/home/images".
# match 可選參數. 一個正則表達式, 作為一個字元串, FilePathField 將使用它過濾文件名.
# 註意這個正則表達式只會應用到 base filename 而不是
# 路徑全名. Example: "foo.*\.txt^", 將匹配文件 foo23.txt 卻不匹配 bar.txt 或 foo23.gif.
# recursive可選參數.要麼 True 要麼 False. 預設值是 False. 是否包括 path 下麵的全部子目錄.
# 這三個參數可以同時使用.
# match 僅應用於 base filename, 而不是路徑全名. 那麼,這個例子:
# FilePathField(path="/home/images", match="foo.*", recursive=True)
# ...會匹配 /home/images/foo.gif 而不匹配 /home/images/foo/bar.gif
<15> IPAddressField
# 一個字元串形式的 IP 地址, (i.e. "24.124.1.30").
<16># CommaSeparatedIntegerField
# 用於存放逗號分隔的整數值. 類似 CharField, 必須要有maxlength參數.
View Code
<5> Field重要參數
<1> null : 資料庫中欄位是否可以為空
<2> blank: django的 Admin 中添加數據時是否可允許空值
<3> default:設定預設值
<4> editable:如果為假,admin模式下將不能改寫。預設為真
<5> primary_key:設置主鍵,如果沒有設置django創建表時會自動加上:
id = meta.AutoField('ID', primary_key=True)
primary_key=True implies blank=False, null=False and unique=True. Only one
primary key is allowed on an object.
<6> unique:數據唯一
<7> verbose_name Admin中欄位的顯示名稱
<8> validator_list:有效性檢查。非有效產生 django.core.validators.ValidationError 錯誤
<9> db_column,db_index 如果為真將為此欄位創建索引
<10>choices:一個用來選擇值的2維元組。第一個值是實際存儲的值,第二個用來方便進行選擇。
如SEX_CHOICES= (( ‘F’,'Female’),(‘M’,'Male’),)
gender = models.CharField(max_length=2,choices = SEX_CHOICES)
View Code
表的操作(增刪改查):
-------------------------------------增(create , save) -------------------------------
1 from app01.models import *
2
3 #create方式一: Author.objects.create(name='Alvin')
4
5 #create方式二: Author.objects.create(**{"name":"alex"})
6
7 #save方式一: author=Author(name="alvin")
8 author.save()
9
10 #save方式二: author=Author()
11 author.name="alvin"
12 author.save()
對於一對多、多對多的操作:
1 #一對多(ForeignKey):
2
3 #方式一: 由於綁定一對多的欄位,比如publish,存到資料庫中的欄位名叫publish_id,所以我們可以直接給這個
4 # 欄位設定對應值:
5 Book.objects.create(title='php',
6 publisher_id=2, #這裡的2是指為該book對象綁定了Publisher表中id=2的行對象
7 publication_date='2017-7-7',
8 price=99)
9
10
11 #方式二:
12 # <1> 先獲取要綁定的Publisher對象:
13 pub_obj=Publisher(name='河大出版社',address='保定',city='保定',
14 state_province='河北',country='China',website='http://www.hbu.com')
15 OR pub_obj=Publisher.objects.get(id=1)
16
17 # <2>將 publisher_id=2 改為 publisher=pub_obj
18
19 #多對多(ManyToManyField()):
20
21 author1=Author.objects.get(id=1)
22 author2=Author.objects.filter(name='alvin')[0]
23 book=Book.objects.get(id=1)
24 book.authors.add(author1,author2)
25 #等同於:
26 book.authors.add(*[author1,author2])
27 book.authors.remove(*[author1,author2])
28 #-------------------
29 book=models.Book.objects.filter(id__gt=1)
30 authors=models.Author.objects.filter(id=1)[0]
31 authors.book_set.add(*book)
32 authors.book_set.remove(*book)
33 #-------------------
34 book.authors.add(1)
35 book.authors.remove(1)
36 authors.book_set.add(1)
37 authors.book_set.remove(1)
38
39 #註意: 如果第三張表是通過models.ManyToManyField()自動創建的,那麼綁定關係只有上面一種方式
40 # 如果第三張表是自己創建的:
41 class Book2Author(models.Model):
42 author=models.ForeignKey("Author")
43 Book= models.ForeignKey("Book")
44 # 那麼就還有一種方式:
45 author_obj=models.Author.objects.filter(id=2)[0]
46 book_obj =models.Book.objects.filter(id=3)[0]
47
48 s=models.Book2Author.objects.create(author_id=1,Book_id=2)
49 s.save()
50 s=models.Book2Author(author=author_obj,Book_id=1)
51 s.save()
View Code
-----------------------------------------刪(delete) ---------------------------------------------
1 >>> Book.objects.filter(id=1).delete()
2 (3, {'app01.Book_authors': 2, 'app01.Book': 1})
我們錶面上刪除了一條信息,實際卻刪除了三條,因為我們刪除的這本書在Book_authors表中有兩條相關信息,這種刪除方式就是django預設的級聯刪除。
如果是多對多的關係: remove()和clear()方法:
1 #正向
2 book = models.Book.objects.filter(id=1)
3
4 #刪除第三張表中和女孩1關聯的所有關聯信息
5 book.author.clear() #清空與book中id=1 關聯的所有數據
6 book.author.remove(2) #可以為id
7 book.author.remove(*[1,2,3,4]) #可以為列表,前面加*
8
9 #反向
10 author = models.Author.objects.filter(id=1)
11 author.book_set.clear() #清空與boy中id=1 關聯的所有數據
-----------------------------------------改(update和save) ----------------------------------------
實例:
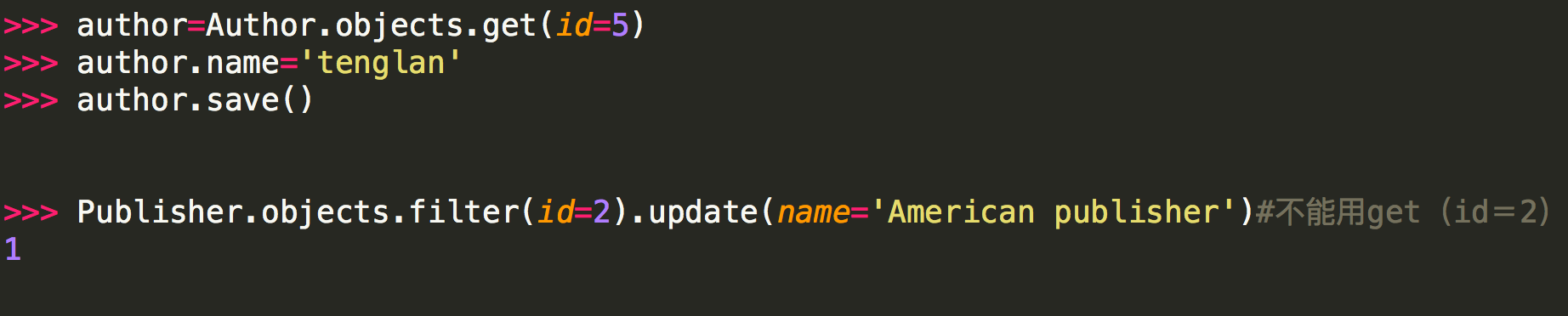
註意:
<1> 第二種方式修改不能用get的原因是:update是QuerySet對象的方法,get返回的是一個model對象,它沒有update方法,而filter返回的是一個QuerySet對象(filter裡面的條件可能有多個條件符合,比如name='alvin',可能有兩個name='alvin'的行數據)。
<2>在“插入和更新數據”小節中,我們有提到模型的save()方法,這個方法會更新一行里的所有列。 而某些情況下,我們只需要更新行里的某幾列。
1 #---------------- update方法直接設定對應屬性----------------
2 models.Book.objects.filter(id=3).update(title="PHP")
3 ##sql:
4 ##UPDATE "app01_book" SET "title" = 'PHP' WHERE "app01_book"."id" = 3; args=('PHP', 3)
5
6
7 #--------------- save方法會將所有屬性重新設定一遍,效率低-----------
8 obj=models.Book.objects.filter(id=3)[0]
9 obj.title="Python"
10 obj.save()
11 # SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price",
12 # "app01_book"."color", "app01_book"."page_num",
13 # "app01_book"."publisher_id" FROM "app01_book" WHERE "app01_book"."id" = 3 LIMIT 1;
14 #
15 # UPDATE "app01_book" SET "title" = 'Python', "price" = 3333, "color" = 'red', "page_num" = 556,
16 # "publisher_id" = 1 WHERE "app01_book"."id" = 3;
View Code
在這個例子里我們可以看到Django的save()方法更新了不僅僅是title列的值,還有更新了所有的列。 若title以外的列有可能會被其他的進程所改動的情況下,只更改title列顯然是更加明智的。更改某一指定的列,我們可以調用結果集(QuerySet)對象的update()方法,與之等同的SQL語句變得更高效,並且不會引起競態條件。
此外,update()方法對於任何結果集(QuerySet)均有效,這意味著你可以同時更新多條記錄update()方法會返回一個整型數值,表示受影響的記錄條數。
註意,這裡因為update返回的是一個整形,所以沒法用query屬性;對於每次創建一個對象,想顯示對應的raw sql,需要在settings加上日誌記錄部分:
1 LOGGING = {
2 'version': 1,
3 'disable_existing_loggers': False,
4 'handlers': {
5 'console':{
6 'level':'DEBUG',
7 'class':'logging.StreamHandler',
8 },
9 },
10 'loggers': {
11 'django.db.backends': {
12 'handlers': ['console'],
13 'propagate': True,
14 'level':'DEBUG',
15 },
16 }
17 }
18
19 LOGGING
View Code
註意:如果是多對多的改:
1 obj=Book.objects.filter(id=1)[0]
2 author=Author.objects.filter(id__gt=2)
3
4 obj.author.clear()
5 obj.author.add(*author)
---------------------------------------查(filter,value等) -------------------------------------
---------->查詢API:
# 查詢相關API:
# <1>filter(**kwargs): 它包含了與所給篩選條件相匹配的對象
# <2>all(): 查詢所有結果
# <3>get(**kwargs): 返回與所給篩選條件相匹配的對象,返回結果有且只有一個,如果符合篩選條件的對象超過一個或者沒有都會拋出錯誤。
#-----------下麵的方法都是對查詢的結果再進行處理:比如 objects.filter.values()--------
# <4>values(*field): 返回一個ValueQuerySet——一個特殊的QuerySet,運行後得到的並不是一系列 model的實例化對象,而是一個可迭代的字典序列
# <5>exclude(**kwargs): 它包含了與所給篩選條件不匹配的對象
# <6>order_by(*field): 對查詢結果排序
# <7>reverse(): 對查詢結果反向排序
# <8>distinct(): 從返回結果中剔除重覆紀錄
# <9>values_list(*field): 它與values()非常相似,它返回的是一個元組序列,values返回的是一個字典序列
# <10>count(): 返回資料庫中匹配查詢(QuerySet)的對象數量。
# <11>first(): 返回第一條記錄
# <12>last(): 返回最後一條記錄
# <13>exists(): 如果QuerySet包含數據,就返回True,否則返回False。
View Code
補充:
#擴展查詢,有時候DJANGO的查詢API不能方便的設置查詢條件,提供了另外的擴展查詢方法extra:
#extra(select=None, where=None, params=None, tables=None,order_by=None, select_params=None
(1) Entry.objects.extra(select={'is_recent': "pub_date > '2006-01-01'"})
(2) Blog.objects.extra(
select=SortedDict([('a', '%s'), ('b', '%s')]),
select_params=('one', 'two'))
(3) q = Entry.objects.extra(select={'is_recent': "pub_date > '2006-01-01'"})
q = q.extra(order_by = ['-is_recent'])
(4) Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
extra
View Code
---------->惰性機制:
所謂惰性機制:Publisher.objects.all()或者.filter()等都只是返回了一個QuerySet(查詢結果集對象),它並不會馬上執行sql,而是當調用QuerySet的時候才執行。
QuerySet特點:
<1> 可迭代的
<2> 可切片
1 #objs=models.Book.objects.all()#[obj1,obj2,ob3...]
2
3 #QuerySet: 可迭代
4
5 # for obj in objs:#每一obj就是一個行對象
6 # print("obj:",obj)
7 # QuerySet: 可切片
8
9 # print(objs[1])
10 # print(objs[1:4])
11 # print(objs[::-1])
View Code
QuerySet的高效使用:
<1>Djang


