
字元集&&排序規則 字元集是針對不同語言的字元編碼的集合,比如UTF-8字元集,GBK字元集,GB2312字元集等等,不同的字元集使用不同的規則給字元進行編碼排序規則則是在特定字元集的基礎上特定的字元排序方式,排序規則是基於字元集的,是對字元集在排序方式維度上的一個劃分。排序規則是依賴於字元集的,一 ...
字元集&&排序規則
字元集是針對不同語言的字元編碼的集合,比如UTF-8字元集,GBK字元集,GB2312字元集等等,不同的字元集使用不同的規則給字元進行編碼
排序規則則是在特定字元集的基礎上特定的字元排序方式,排序規則是基於字元集的,是對字元集在排序方式維度上的一個劃分。
排序規則是依賴於字元集的,一種字元集可以有多種排序規則,但是一種排序規則只能基於某一種字元集的
比如中文字元集,也即漢字,可以按照“拼音排序”、“按姓氏筆劃排序”等等。
而對於英語,就沒有“拼音”和“姓氏筆畫”,但是可以分為區分大小寫、不區分大小寫等等
而其他語言下麵也有自己特定的排序規則。
在SQL Server中,任何一種字元集的資料庫,都能存儲任何一種語言的字元。
並不是說拉丁(Latin)字元集的數據就存儲不了中文,中文(Chinese)字元集的資料庫就存儲不了蒙古語(只要操作系統本身支持)
sqlserver中,不管哪種字元集(實際上是排序規則)的資料庫(或者欄位),都是可以使用nvarchar(或者nchar),而nvarchar(或者nchar)是可以存儲任意非Unicode字元的
至於排序規則,那是根據不同的字元集所支持的不同的排序規則人為定義的。
SQL Server中的字元集和排序規則
排序規則只不過是指定了存儲的數據的排序(比較)規則而已,換句話說就是,排序規則中已經包含了字元集的信息。
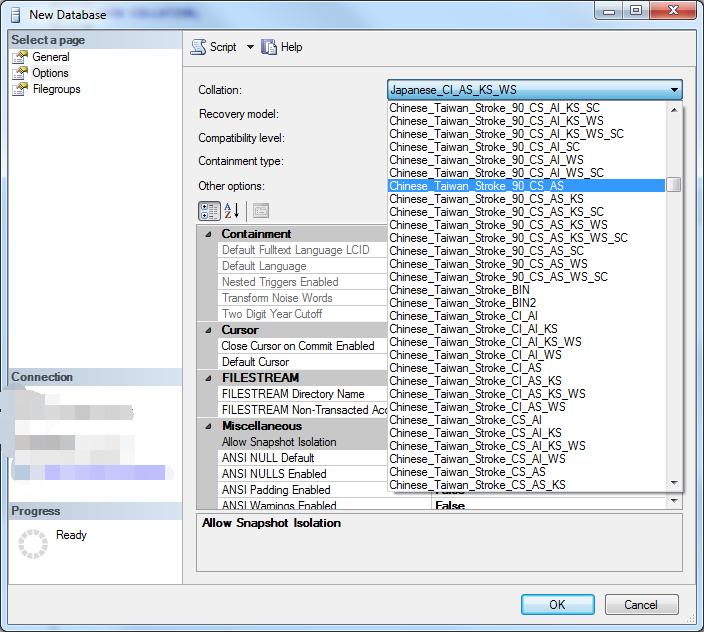
因此在sqlserver中 ,不需要關心字元集,只需要關心排序規則,sqlserver中在創建只能指定排序規則(不能直接指定字元集),
如截圖,只能指定collation,也就是字元集
在MySQL中的字元集和排序規則
上面說了,排序規則是依賴於字元集的,一種字元集可以有多種排序規則,但是一種排序規則只能基於某一種字元集的。
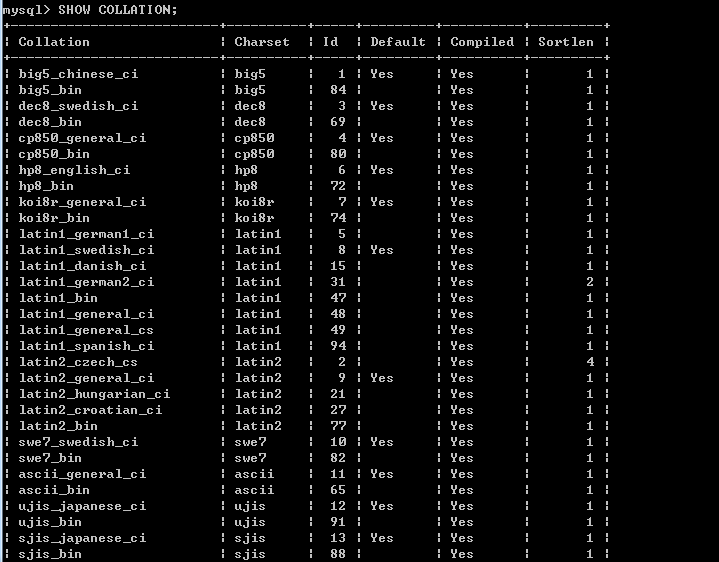
如下是MySQL中排序規則和字元集的對應關係。
MySQL的建庫語法比較扯,可以指定字元集和排序規則,
如果指定的排序規則在字元集的下麵,則是沒有問題的,如果指定的排序規則不在字元集下麵,則會報錯。
比如下麵這一句,排序規則utf8_bin是屬於字元集utf8下麵的一種排序規則,這個語句執行是沒有問題的
create database test_database2 charset utf8 collate utf8_bin;
再比如下麵這一句,排序規則latin1_bin不是屬於字元集utf8下麵的一種排序規則,這個語句執行是會報錯的
create database test_database2 charset utf8 collate latin1_bin;

以上是字元集和排序規則在sqlserver和MySQL中的一些基本應用,再說說常用的排序規則的區別
***_genera_ci & ***_genera_cs & ***_bin 常見排序規則的特點
以上是某種字元集下常用的三種排序規則,下麵以常見的utf8為例說明
utf8_genera_ci不區分大小寫,ci為case insensitive的縮寫,即大小寫不敏感,
utf8_general_cs區分大小寫,cs為case sensitive的縮寫,即大小寫敏感,但是目前MySQL版本中已經不支持類似於***_genera_cs的排序規則,直接使用utf8_bin替代。
utf8_bin將字元串中的每一個字元用二進位數據存儲,區分大小寫。
那麼,同樣是區分大小寫,utf8_general_cs和utf8_bin有什麼區別?
cs為case sensitive的縮寫,即大小寫敏感;bin的意思是二進位,也就是二進位編碼比較。
utf8_general_cs排序規則下,即便是區分了大小寫,但是某些西歐的字元和拉丁字元是不區分的,比如ä=a,但是有時並不需要ä=a,所以才有utf8_bin
utf8_bin的特點在於使用字元的二進位的編碼進行運算,任何不同的二進位編碼都是不同的,因此在utf8_bin排序規則下:ä<>a
在utf8_genera_ci的情況下A=a,ä=a
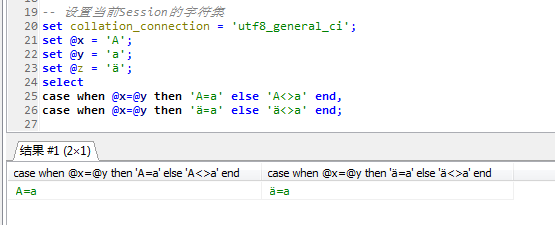
在utf8_bin排序規則下,A<>a,ä<>a

所以要想區分大小寫,有沒有特殊需求,就直接使用utf8_bin(實際上***_general_cs在MySQL中本身就不支持,在SQL Server中支持)
以上字元集的特點以及使用情況在SQL Server中表現為類似。
以上。


