
上一篇文章寫過centos 7下clickhouse rpm包安裝和基本的目錄結構,這裡主要介紹clickhouse高可用集群的部署方案,因為對於預設的分散式表的配置,每個分片只有一份,這樣如果掛掉一個節點,則查詢分散式表的時候直接會報錯,這個是基於clickhouse自己實現的多分片單副本集群,配 ...
上一篇文章寫過centos 7下clickhouse rpm包安裝和基本的目錄結構,這裡主要介紹clickhouse高可用集群的部署方案,因為對於預設的分散式表的配置,每個分片只有一份,這樣如果掛掉一個節點,則查詢分散式表的時候直接會報錯,這個是基於clickhouse自己實現的多分片單副本集群,配置也比較簡單,這裡說的高可用是指,每個分片具有2個或以上副本,當某個節點掛掉時,該節點分片仍可以由其他機器上的副本替代工作,所以這樣實現的分散式集群可以在掛掉至少1個節點時機器正常運行,隨著集群節點數量的增加,則集群掛掉2個節點或以上可提供服務的概率也越大,至少能避免單點故障問題,集群的穩定性也更高.
clickhouse集群的理想方案是如下所示:
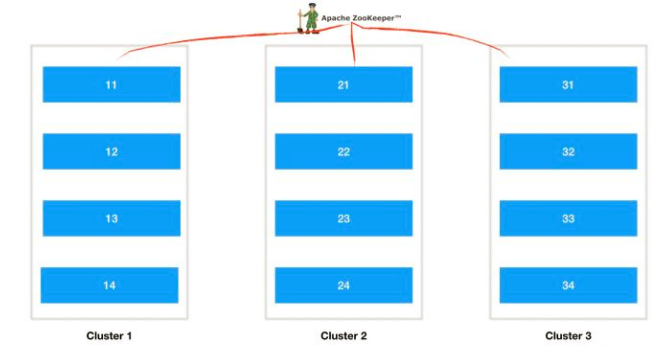
這裡有3個集群,每個集群n個節點,每個節點的數據依靠zookeeper協調同步,比如cluster1提供服務,如果cluster1裡面掛掉多台機器那麼cluster2的副本可以切換過來提供服務,如果cluster2的分片再掛了,那麼cluster3中的副本也可以提供服務,cluster1~3同時掛掉的概率就非常小了,所以集群的穩定性可以非常高,其中單個集群的節點個數n決定了clickhouse的性能,性能是可以線性擴展的,具體副本集群的個數根據機器資源配置.
如果機器資源確實特別少,想每個節點都用上提供服務的話,那麼可以每個節點存儲兩個以上的副本,即提供服務的分片和其他機器的副本,實現相互備份,但是clickhouse不支持單個節點多個分片的配置,我們可以人為設置在每個節點上啟動兩個實例來實現,設計圖如下:

圖畫的非常簡陋,但是可以看出來3個節點每個節點的tcp 9000對外提供服務,9001提供副本,其中2提供1的備份,3提供2的備份,1提供3的備份,這樣假設掛掉1個節點,集群也可以正常使用,但是掛掉2個幾點,就不正常了,這樣的話是機器越多越穩定一些.
上面兩種方案,官網上還是推薦的第一種方案可用性最高,這裡為了演示採用第二種方式配置,其實兩種方式的配置是完全一樣的,第二種配置反而更繁瑣一些,下麵詳細說一下配置的流程,軟體包結構就採用上一篇文章打包好的.
0. 高可用原理:zookeeper + ReplicatedMergeTree(複製表) + Distributed(分散式表)
1. 前提準備:所有節點防火牆關閉或者開放埠;hosts表和主機名一定要集群保持一致正確配置,因為zookeeper返回的是主機名,配置錯誤或不配置複製表時會失敗.
clickhouse測試節點2個:192.168.0.107 clickhouse1, 192.168.0.108 clickhouse2
zookeeper測試節點1個:192.168.0.103 bigdata
配置方案:兩個節點各配置兩個clickhouse實例,相互備份.
clickhouse1: 實例1, 埠: tcp 9000, http 8123, 同步埠9009, 類型: 分片1, 副本1
clickhouse1: 實例2, 埠: tcp 9001, http 8124, 同步埠9010, 類型: 分片2, 副本2 (clickhouse2的副本)
clickhouse2: 實例1, 埠: tcp 9000, http 8123, 同步埠9009, 類型: 分片2, 副本1
clickhouse2: 實例2, 埠: tcp 9001, http 8124, 同步埠9010, 類型: 分片1, 副本2 (clickhouse1的副本)
2. 修改啟動腳本和配置文件
首先將啟動腳本複製一個出來,除了上一篇文章說的外,主要修改配置文件位置和pid文件位置,如下:
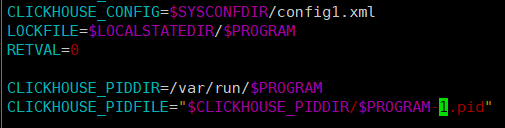
這裡配置文件比如使用config1.xml,pid使用clickhouse-server-1.pid
然後進入到配置文件目錄,將原有配置文件拷貝一份,這裡是config1.xml,然後修改配置:
主要修改內容是:日誌文件(和之前不要衝突)、http埠、tcp埠、副本同步埠(這個改完之後clickhouse按照當前實例的埠自動和其他實例同步)、數據文件和tmp目錄、users.xml(這個如果都一樣可以用同一個)、最後就是集群配置了,下麵重點敘述:
集群配置預設為:<remote_servers incl="clickhouse_remote_servers" />
zookeeper預設為:<zookeeper incl="zookeeper-servers" optional="true" />
macros預設為:<macros incl="macros" optional="true" />
首先是集群分片的配置,這個配置所有節點的所有實例完全保持一致:
<remote_servers>
<distable>
<shard>
<!-- Optional. Shard weight when writing data. Default: 1. -->
<weight>1</weight>
<!-- Optional. Whether to write data to just one of the replicas. Default: false (write data to all replicas). -->
<internal_replication>true</internal_replication>
<replica>
<host>192.168.0.107</host>
<port>9000</port>
</replica>
<replica>
<host>192.168.0.108</host>
<port>9001</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.0.108</host>
<port>9000</port>
</replica>
<replica>
<host>192.168.0.107</host>
<port>9001</port>
</replica>
</shard>
</distable>
</remote_servers>
配置裡面的<distable>是分散式標識標簽,可以自定義,到最後創建分散式表的時候會用到;然後weight是分片權重,即寫數據時有多大的概率落到此分片,因為這裡所有分片權重相同所有都設置為1,然後是internal_replication,表示是否只將數據寫入其中一個副本,預設為false,表示寫入所有副本,在複製表的情況下可能會導致重覆和不一致,所以這裡一定要改為true,clickhouse分散式表只管寫入一個副本,其餘同步表的事情交給複製表和zookeeper來進行,然後是replica配置這個好理解,就是一個分片下的所有副本,這裡副本的分佈一定要手動設計好,保證相互備份,然後再次說明是所有的節點配置一致. 此部分配置嚴格按照官網配置,參考鏈接:https://clickhouse.yandex/docs/en/operations/table_engines/distributed/
然後是zookeeper配置,這個也是所有示例配置都一樣:
<zookeeper>
<node index="1">
<host>192.168.0.103</host>
<port>2181</port>
</node>
</zookeeper>
這裡zookeeper只有一個,如果多個的話繼續往下寫,就像官網上給出的一樣,參考下圖:

然後是複製標識的配置,也稱為巨集配置,這裡唯一標識一個副本名稱,每個實例都要配置並且都是唯一的,這裡配置如下:
clickhouse1 9000 分片1, 副本1:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>
clickhouse1 9001 分片2, 副本2:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>
clickhouse2 9000 分片2, 副本1:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-1</replica>
</macros>
clickhouse2 9001 分片1, 副本2:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-2</replica>
</macros>
由上面配置可以看到replica的分佈規律,其中layer是雙級分片設置,在Yandex公司的集群中用到,因為我們這裡是單集群所以這個值對我們沒有影響全部一樣即可,這裡是01;然後是shard表示分片編號;最後是replica是副本標識,這裡使用了cluster{layer}-{shard}-{replica}的表示方式,比如cluster01-02-1表示cluster01集群的02分片下的1號副本,這樣既非常直觀的表示又唯一確定副本. 副本的文檔鏈接下麵會給出.
3. 創建本地複製表和分散式表
所有實例配置完上面這些之後,分別執行啟動命令啟動,然後所有實例都執行下麵語句創建資料庫:
CREATE DATABASE monchickey;
然後對於所有實例分別創建對應的複製表,這裡測試創建一個簡單的表
clickhouse1 9000 實例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-01/image_label','cluster01-01-1',insert_time, (label_id, insert_time), 8192)
clickhouse1 9001 實例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-02/image_label','cluster01-02-2',insert_time, (label_id, insert_time), 8192)
clickhouse2 9000 實例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-02/image_label','cluster01-02-1',insert_time, (label_id, insert_time), 8192)
clickhouse2 9001 實例:
CREATE TABLE monchickey.image_label ( label_id UInt32, label_name String, insert_time Date) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-01/image_label','cluster01-01-2',insert_time, (label_id, insert_time), 8192)
到這裡複製表就創建完畢了,註意引號部分只能用單引號,其中核心的地方是同一個分片在zookeeper上面的znode相同,下麵包含數據表的多個副本,當一個副本寫入數據時會自動觸發同步操作. 上面建表語句和配置文件對應著看應該容易理解,更詳細的說明參考文檔:https://clickhouse.yandex/docs/en/operations/table_engines/replication/ 文檔關於ReplicatedMergeTree敘述如下:
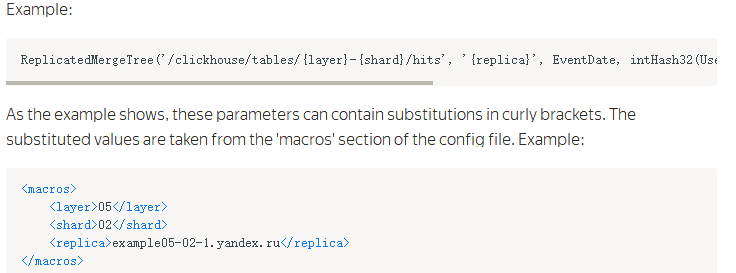
然後創建完上面複製表之後,可以創建分散式表,分散式表只是作為一個查詢引擎,本身不存儲任何數據,查詢時將sql發送到所有集群分片,然後進行進行處理和聚合後將結果返回給客戶端,因此clickhouse限制聚合結果大小不能大於分散式表節點的記憶體,當然這個一般條件下都不會超過;分散式表可以所有實例都創建,也可以只在一部分實例創建,這個和業務代碼中查詢的示例一致,建議設置多個,當某個節點掛掉時可以查詢其他節點上的表,分散式表的建表語句如下:
CREATE TABLE image_label_all AS image_label ENGINE = Distributed(distable, monchickey, image_label, rand())
分散式表一般用本地表加all來表示,這裡distable就是上面xml配置中的標簽名稱,最後的rand()表示向分散式表插入數據時,將隨機插入到副本,在生產環境建議插入的時候客戶端可以隨機分桶插入到本地表,查詢的時候走分散式表,即分散式表只讀,本地複製表只寫.
配置好上面這些可以嘗試通過不同clickhouse實例寫入數據測試,然後查詢可以發現分片都會單獨同步,不同分片間數據互不影響,通過分散式表查詢可以查詢到所有的數據;如果停掉clickhouse2這個節點,此時clickhouse會自動切換為可用的副本使用,無需人工干預,現在查詢分散式表仍然可用,當clickhouse2上面的實例啟動恢復的時候,clickhouse會自動切換回來並且做數據的同步,這樣就實現了高可用性.
上面就是clickhouse高可用集群的基本配置,確實如一些文章所說像一輛手動擋的車,用的越熟練越好用,另外關於性能和深入的配置隨著以後使用會繼續分享,最後本人表達能力不是太好,如果文中有錯誤或敘述的不當,希望路過的大牛們指出,非常感謝^_^


