
返回 "ProxySQL系列文章:http://www.cnblogs.com/f ck need u/p/7586194.html" 1.理解鏈式規則 在mysql_query_rules表中,有兩個特殊欄位" flagIN "和" flagOUT ",它們分別用來定義規則的入口和出 ...
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html
1.理解鏈式規則
在mysql_query_rules表中,有兩個特殊欄位"flagIN"和"flagOUT",它們分別用來定義規則的入口和出口,從而實現鏈式規則(chains of rules)。
鏈式規則的實現方式如下:
- 當入口值flagIN設置為0時,表示開始進入鏈式規則。如未顯式指定規則的flagIN值,則預設都為0。
- 當語句匹配完當前規則後,將記下當前規則的flagOUT值,如果flagOUT值非空(NOT NULL),則為該語句打上flagOUT標記。如果該規則的apply欄位值不是1,則繼續向下匹配。
- 如果語句的flagOUT標記和下一條規則的flagIN值不同,則跳過該規則,繼續向下匹配。直到匹配到
flagOUT=flagIN的規則,則匹配該規則。該規則是鏈式規則中的另一條規則。
- 直到某規則的apply欄位設置為1,或者已經匹配完所有規則,則最後一次被評估的規則將直接生效,不再繼續向下匹配。
通過下麵兩張圖,應該很容易理解鏈式規則的生效方式。
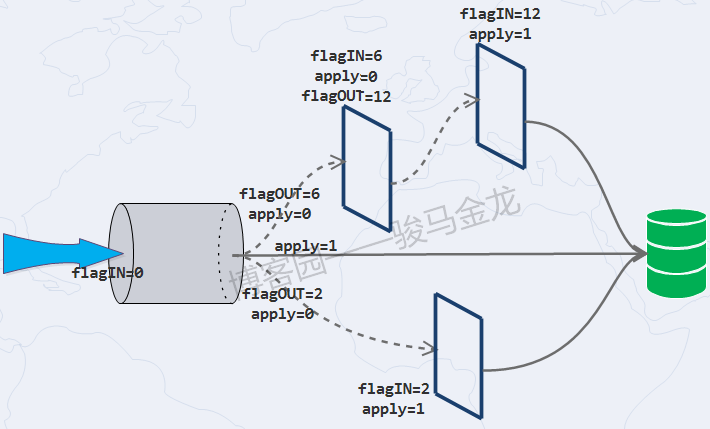
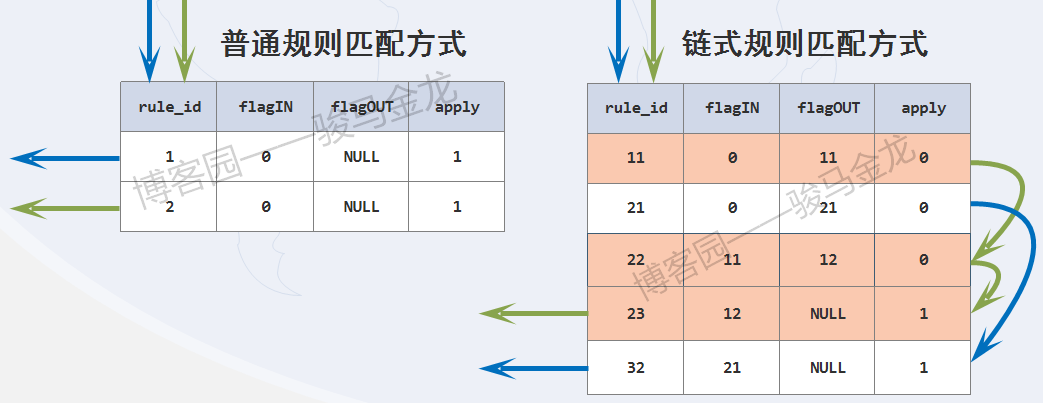
必須註意,規則是按照rule_id的大小順序進行的。且並非只有apply=1時才會應用規則,當無規則可匹配,或者某規則的flagIN和flagOUT值相同,都會應用最後一次被評估的規則。
以下幾個示例,可以解釋生效規則:
# rule_id=3 生效
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | 23 |
| 3 | 0 | 23 | NULL |
+---------+-------+--------+---------+
# rule_id=2 生效
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | 23 |
| 3 | 0 | 24 | NULL |
+---------+-------+--------+---------+
# rule_id=2 生效,因為匹配完rule_id=2後,還打著flagOUT=23標記
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | NULL |
| 3 | 1 | 24 | NULL |
+---------+-------+--------+---------+
# rule_id=3 生效,因為匹配完rule_id=2後,還打著flagOUT=23標記
+---------+-------+--------+---------+
| rule_id | apply | flagIN | flagOUT |
+---------+-------+--------+---------+
| 1 | 0 | 0 | 23 |
| 2 | 0 | 23 | NULL |
| 3 | 1 | 23 | NULL |
+---------+-------+--------+---------+2.鏈式規則示例
有了普通規則匹配方式,為什麼還要設計鏈式規則呢?雖然ProxySQL通過正則表達式實現了很靈活的規則匹配模式,但需求總是千變萬化的,有時候僅通過一條正則匹配規則和替換規則很難實現比較複雜的要求,例如sharding時。
鏈式規則除了常用的多次替換,還可巧用於多次匹配。
本文簡單演示一下鏈式規則,不具有實際意義,只為後面ProxySQL實現sharding的文章做基礎知識鋪墊。
2個測試庫,共4張表test{1,2}.t{1,2}。
mysql> select * from test1.t1;
+------------------+
| name |
+------------------+
| test1_t1_malong1 |
| test1_t1_malong2 |
| test1_t1_malong3 |
+------------------+
mysql> select * from test1.t2;
+------------------+
| name |
+------------------+
| test1_t2_malong1 |
| test1_t2_malong2 |
| test1_t2_malong3 |
+------------------+
mysql> select * from test2.t1;
+--------------------+
| name |
+--------------------+
| test2_t1_xiaofang1 |
| test2_t1_xiaofang2 |
| test2_t1_xiaofang3 |
+--------------------+
mysql> select * from test2.t2;
+--------------------+
| name |
+--------------------+
| test2_t2_xiaofang1 |
| test2_t2_xiaofang2 |
| test2_t2_xiaofang3 |
+--------------------+現在借用鏈式規則,一步一步地將對test1.t1表的查詢路由到test2.t2表的查詢。再次聲明,此處示例毫無實際意義,僅為演示鏈式規則的基本用法。
大致鏈式匹配的過程為:
test1.t1 --> test1.t2 --> test2.t1 --> test2.t2以下是具體插入的規則:
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(1,1,0,0,23,"test1\.t1","test1.t2");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern) values
(2,1,0,23,24,"test1\.t2","test2.t1");
insert into mysql_query_rules
(rule_id,active,apply,flagIN,flagOUT,match_pattern,replace_pattern,destination_hostgroup) values
(3,1,1,24,NULL,"test2\.t1","test2.t2",30);
load mysql query rules to runtime;
save mysql query rules to disk;
admin> select rule_id,
apply,
flagIN,
flagOUT,
match_pattern,
replace_pattern,
destination_hostgroup DH
from mysql_query_rules;
+---------+-------+--------+---------+---------------+-----------------+------+
| rule_id | apply | flagIN | flagOUT | match_pattern | replace_pattern | DH |
+---------+-------+--------+---------+---------------+-----------------+------+
| 1 | 0 | 0 | 23 | test1\.t1 | test1.t2 | NULL |
| 2 | 0 | 23 | 24 | test1\.t2 | test2.t1 | NULL |
| 3 | 1 | 24 | NULL | test2\.t1 | test2.t2 | 30 |
+---------+-------+--------+---------+---------------+-----------------+------+查詢test1.t1表,測試結果。
[root@xuexi ~]# mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"
+--------------------+
| name |
+--------------------+
| test2_t2_xiaofang1 | <-- 查詢返回結果為test2.t2內容
| test2_t2_xiaofang2 |
| test2_t2_xiaofang3 |
+--------------------+
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 | <-- 3條規則全都命中
| 2 | 1 |
| 3 | 1 |
+---------+------+
admin> select hostgroup,digest_text from stats_mysql_query_digest;
+-----------+----------------------------------+
| hostgroup | digest_text |
+-----------+----------------------------------+
| 30 | select * from test2.t2 | <-- 路由目標hg=30
+-----------+----------------------------------+顯然,已經按照預想中的方式進行匹配、替換、路由。
一個問題:如果查詢的是test1.t2表或test2.t1表,會進行鏈式匹配嗎?
答案是不會,因為rule_id=2和rule_id=3這兩個規則的flagIN都是非0值,而每個SQL語句初始時只進入flagIN=0的規則。
此外還需註意,當某語句未按照我們的期望途經所有的鏈式規則,則可能會根據destination_hostgroup欄位的值直接路由出去,即使沒有指定該欄位值,還有用戶的預設路由目標組,或者基於埠的路由目標。所以,在寫鏈式規則時,應當儘可能地針對某一類型的語句進行完完整整的定製,保證這類語句能途經我們所期望的所有規則。


