
主要包括以下三部分,本文為第一部分: 一. Scala環境準備 二. Hadoop集群(偽分佈模式)安裝 "查看" 三. Spark集群(standalone模式)安裝 "查看" 因Spark任務大多由Scala編寫,因此,首先需要準備Scala環境。 註:樓主實驗環境為mac os Scala環境 ...
主要包括以下三部分,本文為第一部分:
一. Scala環境準備
二. Hadoop集群(偽分佈模式)安裝 查看
三. Spark集群(standalone模式)安裝 查看
因Spark任務大多由Scala編寫,因此,首先需要準備Scala環境。
註:樓主實驗環境為mac os
Scala環境準備
- 下載JDK1.8並安裝、配置環境變數(JAVA_HOME),建議使用1.8,與時俱進;
下載scala-sdk並解壓到某個路徑(如:
~/tools/scala-2.12.6),為方便使用還可以設置一下SCALA_HOME,在終端輸入~/tools/scala-2.12.6/bin/scala(未設置SCALA_HOME)或scala(前提設置了SCALA_HOME)可以驗證scala的版本或進行交互實驗(scala官網推薦的圖書《Programming in Scala, 3rd ed》中的實例均為在此模式下運行,故學習scala階段到這一步就夠了)
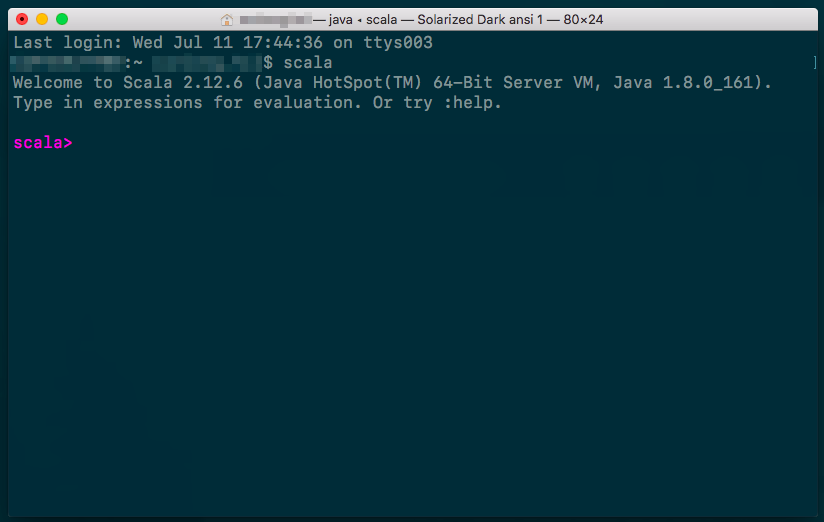
下載IntelliJ IDEA(Ultimate"版即為免費版本)並安裝,安裝後安裝Scala插件(plugin),如下圖所示;
打開plugin菜單:
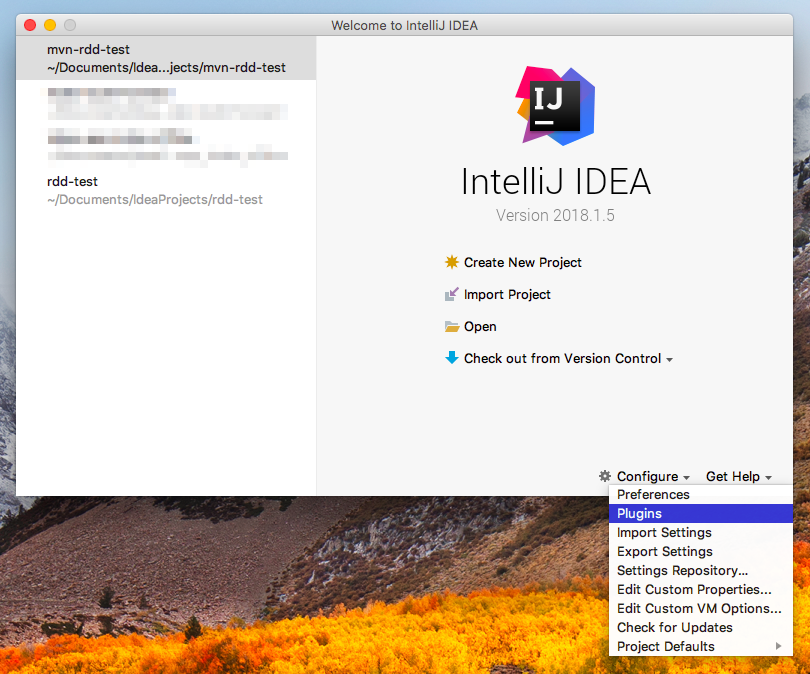
搜索並安裝scala插件

- 寫個小程式測試一下吧
選擇“Create New Project”

選擇項目類型為“Scala”
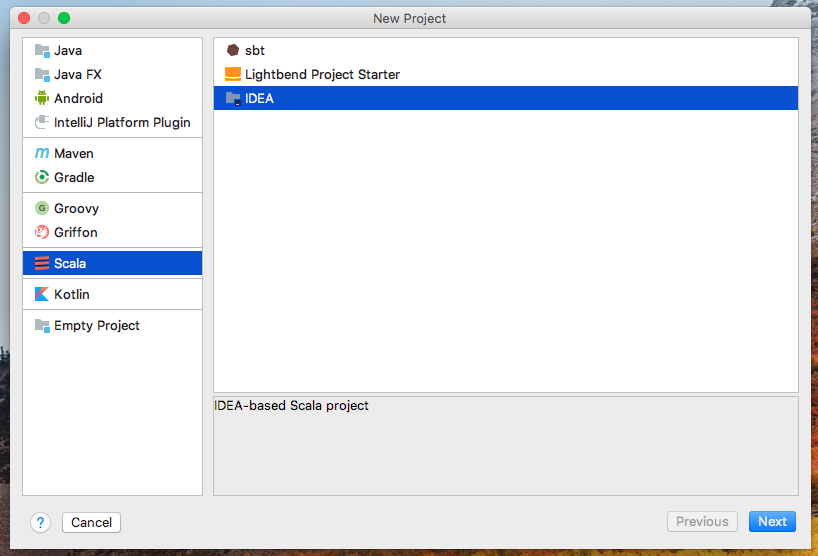
預設沒有Scala SDK,通過以下方式添加:Create->Browse...
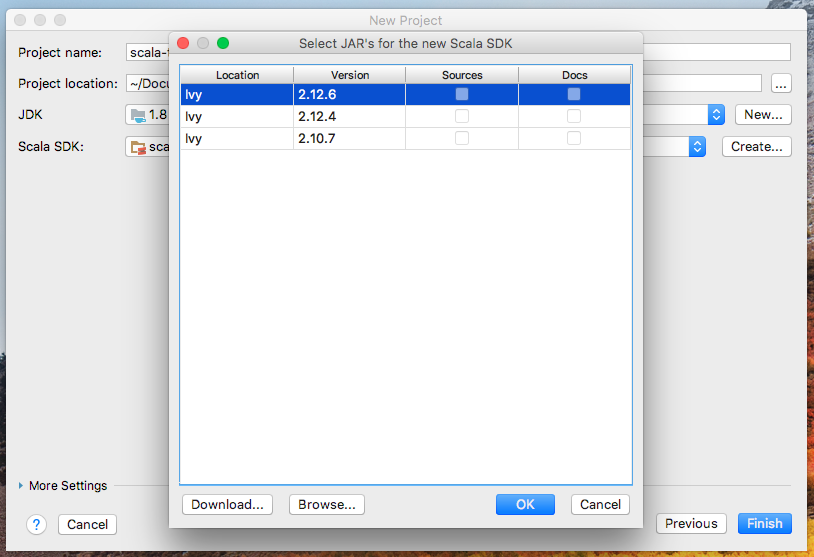
找到SCALA_HOME
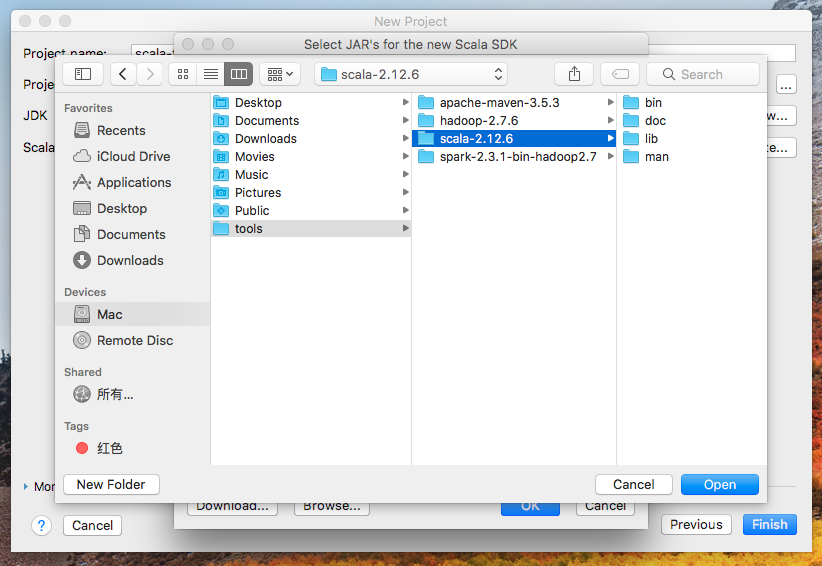
完成配置
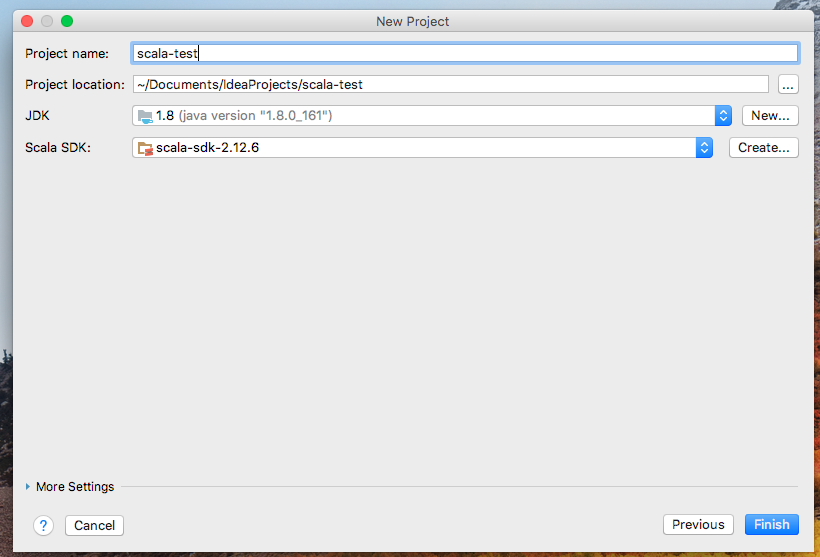
為方便開發,將項目轉換為maven項目以解決繁瑣的依賴包問題,項目名右鍵-->Add Framework Support...
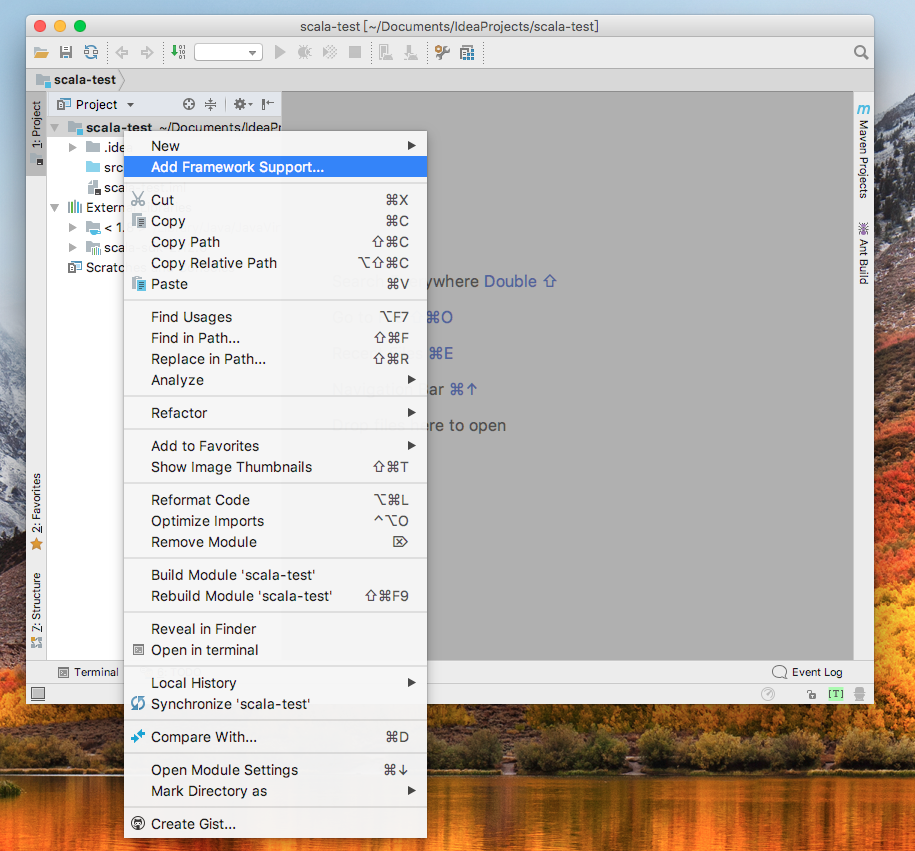
選擇maven
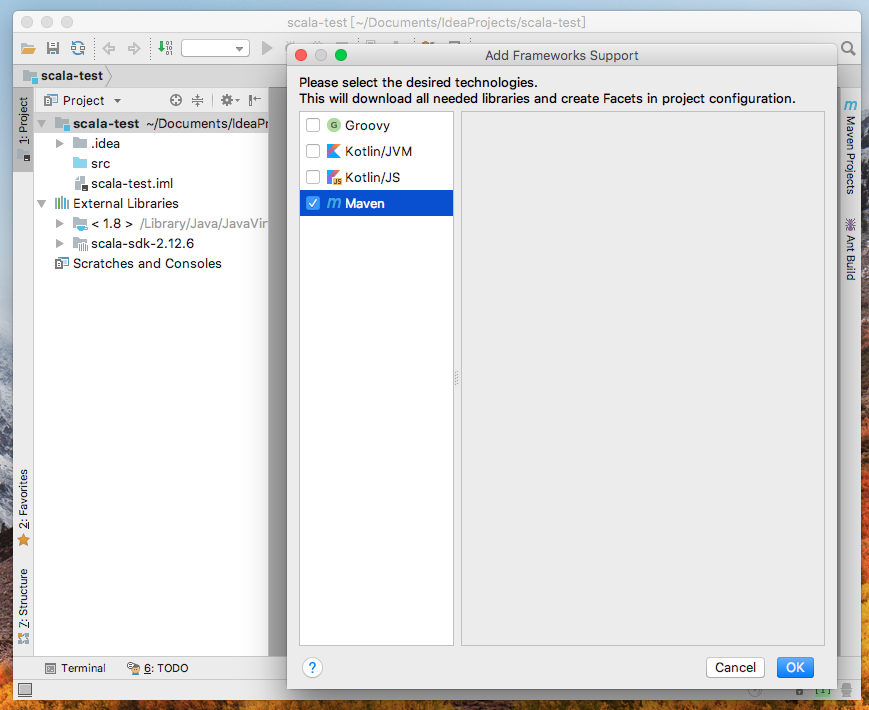
項目會自動引入pom.xml,變為scala maven project,併在src下創建source root(可以在package上右鍵更改)
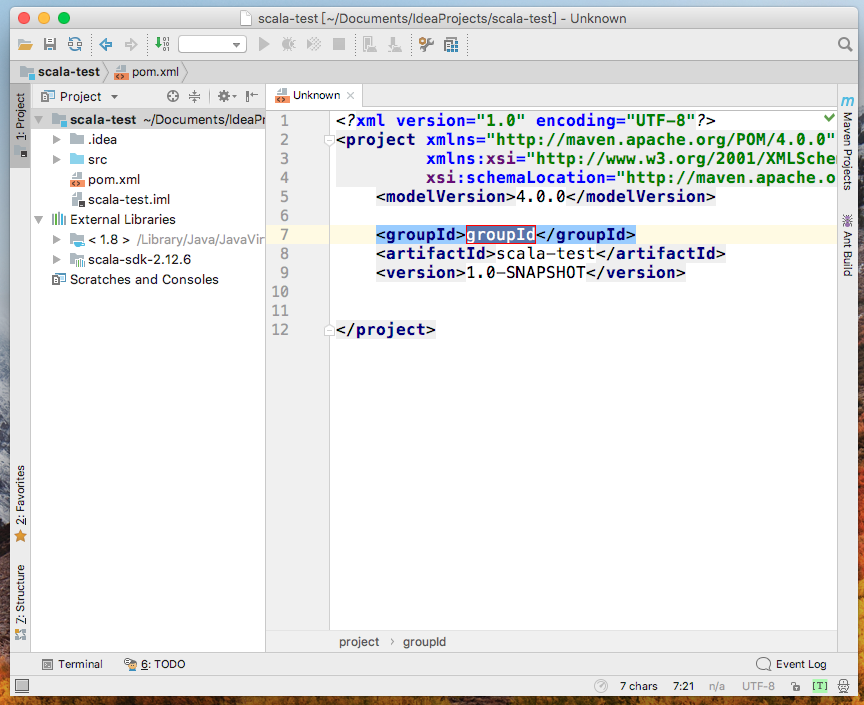
source root(該項目中為main.java)上右鍵-->New-->Scala Class
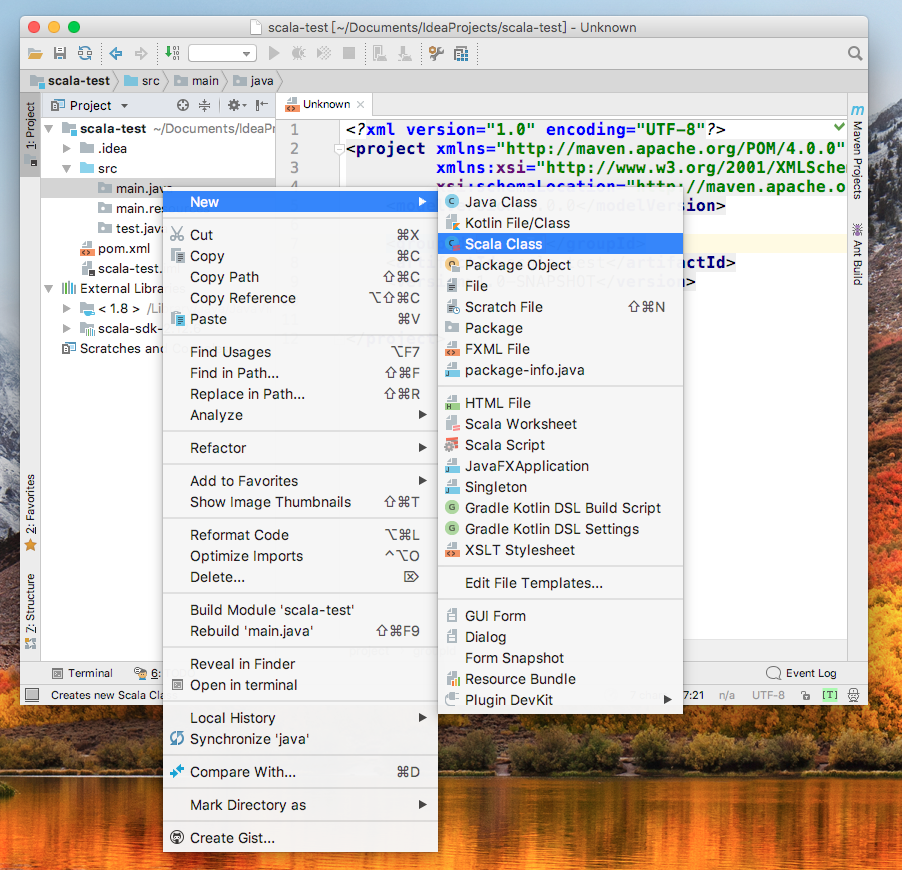
選擇類型為Object,用以創建main函數
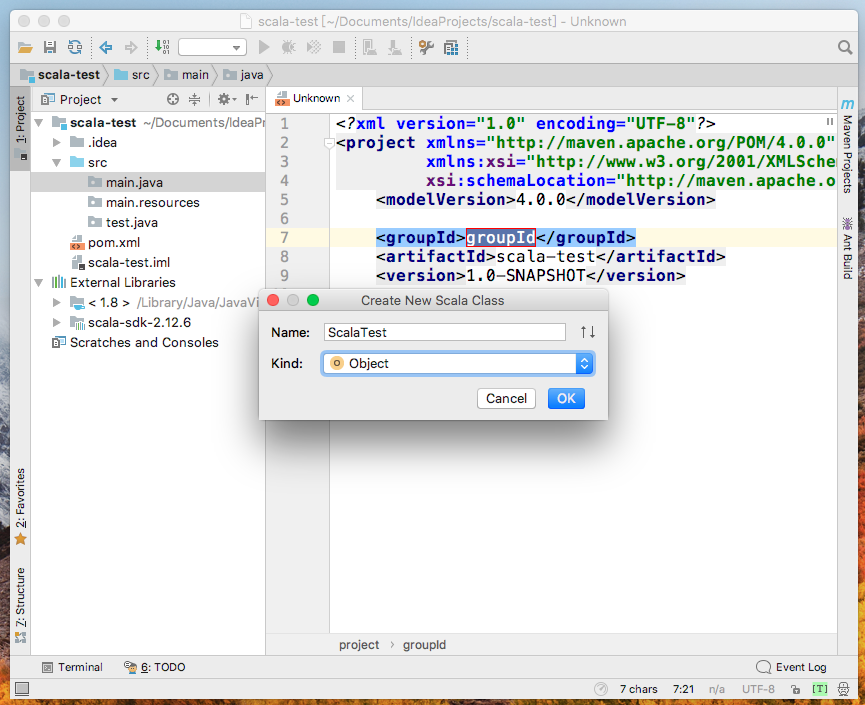
編寫測試代碼
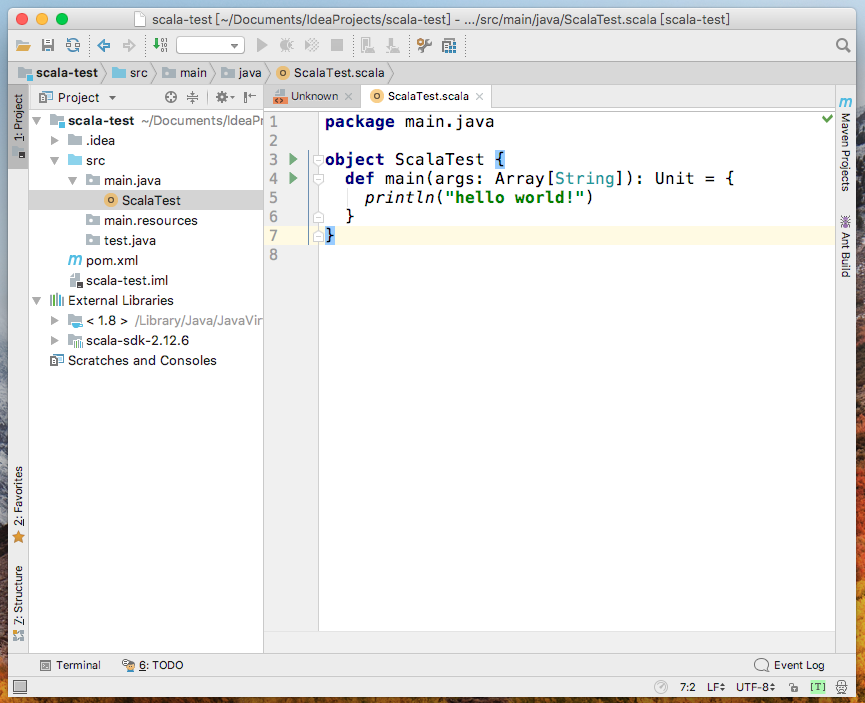
在代碼空白處或項目名處右鍵-->Run 'ScalaTest'測試代碼
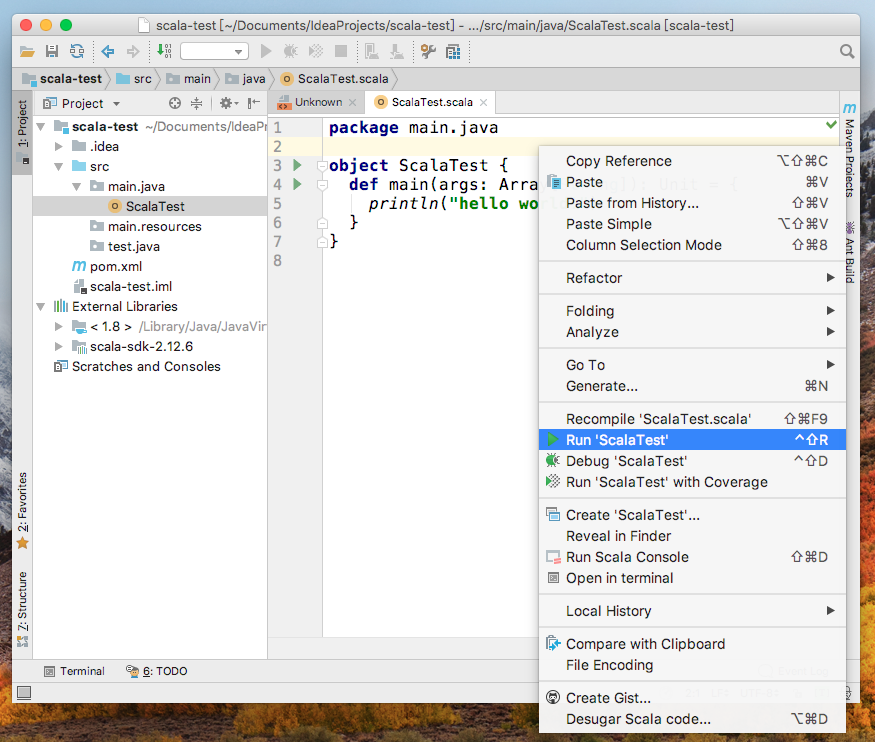
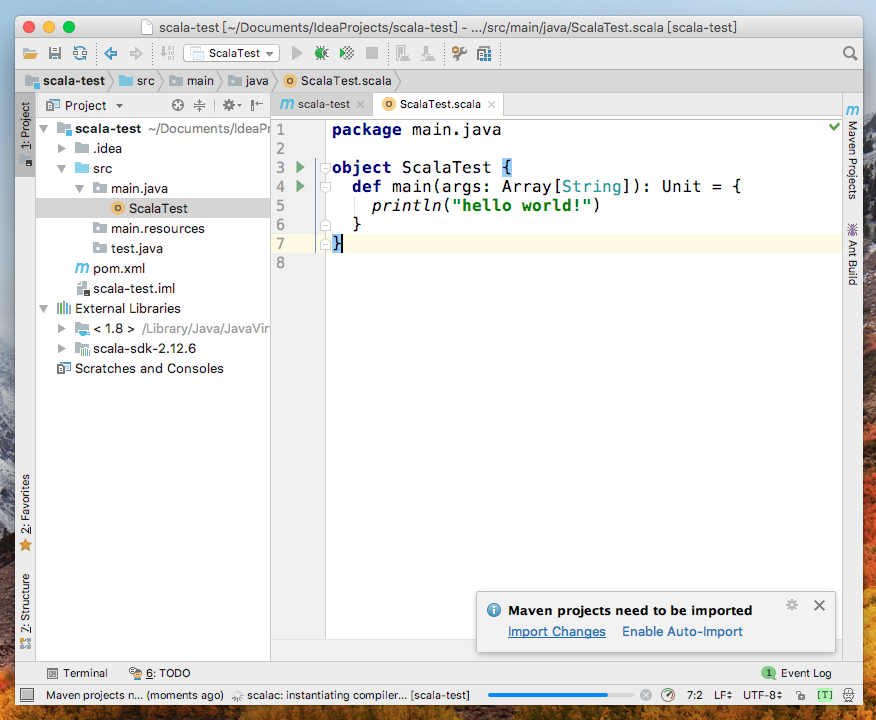
雖然引入了pom.xml,預設卻不會自動import依賴包,出現提示選擇“Auto-Import”
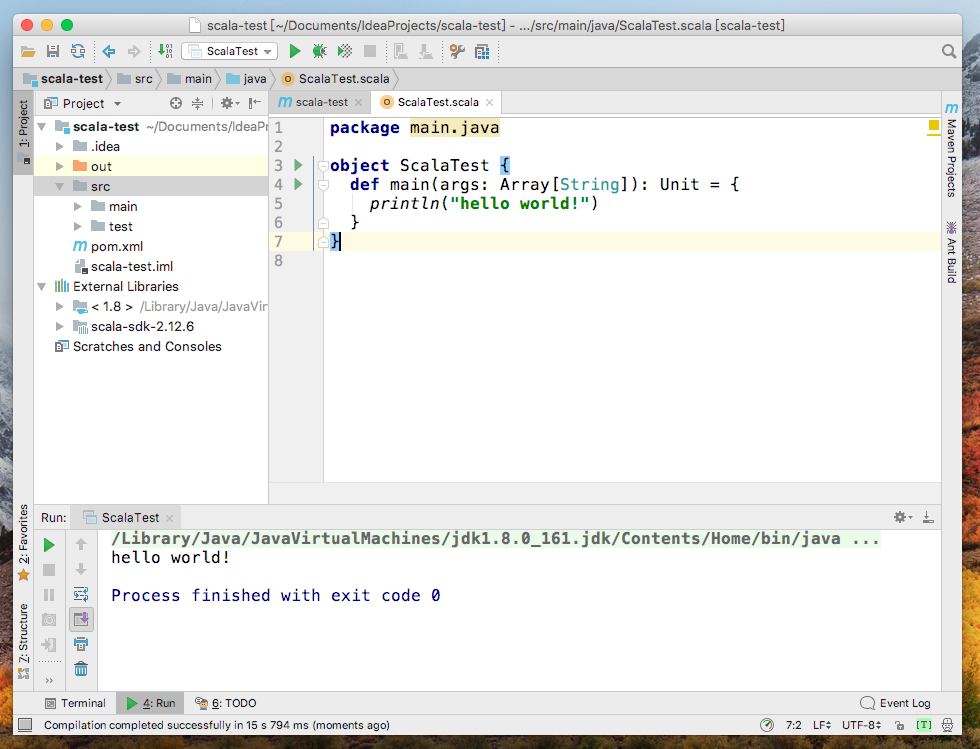
測試結果
之所以這一步這麼詳細是因為我發現創建項目的時候選擇哪種project類型會很糾結,也沒有官方標準,經過實驗,推崇先創建scala project再轉換為maven project;如果創建的時候選擇了maven project,通過“Add Framework Support...”再引入Scala SDK也是可以的,最終效果和圖中給出的差不多,但是目錄結構會有差異。
註1:SCALA_HOME、JAVA_HOME在mac下設置方式:
在~/.bash_profile中添加如下指令:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_161.jdk/Contents/Home
export SCALA_HOME=/Users/<你的名字>/tools/scala-2.12.6
export PATH=$JAVA_HOME/bin:$SCALA_HOME/bin:$PATH參考文檔:官方文檔

