
HDFS HA Namenode HA 詳解 hadoop2.x 之後,Clouera 提出了 QJM/Qurom Journal Manager,這是一個基於 Paxos 演算法(分散式一致性演算法)實現的 HDFS HA 方案,它給出了一種較好的解決思路和方案,QJM 主要優勢如下: 不需要配置額外 ...
HDFS HA
Namenode HA 詳解
hadoop2.x 之後,Clouera 提出了 QJM/Qurom Journal Manager,這是一個基於 Paxos 演算法(分散式一致性演算法)實現的 HDFS HA 方案,它給出了一種較好的解決思路和方案,QJM 主要優勢如下:
不需要配置額外的高共用存儲,降低了複雜度和維護成本。
消除 spof(單點故障)。
系統魯棒性(Robust)的程度可配置、可擴展。

基本原理就是用 2N+1 台 JournalNode 存儲 EditLog,每次寫數據操作有>=N+1 返回成功時即認為該次寫成功,數據不會丟失了。當然這個演算法所能容忍的是最多有 N台機器掛掉,如果多於 N 台掛掉,這個演算法就失效了。這個原理是基於 Paxos 演算法。
在 HA 架構裡面 SecondaryNameNode 已經不存在了,為了保持 standby NN 時時的與 Active NN 的元數據保持一致,他們之間交互通過 JournalNode 進行操作同步。
任何修改操作在 Active NN 上執行時,JournalNode 進程同時也會記錄修改 log到至少半數以上的 JN 中,這時 Standby NN 監測到 JN 裡面的同步 log 發生變化了會讀取 JN 裡面的修改 log,然後同步到自己的目錄鏡像樹裡面,如下圖:
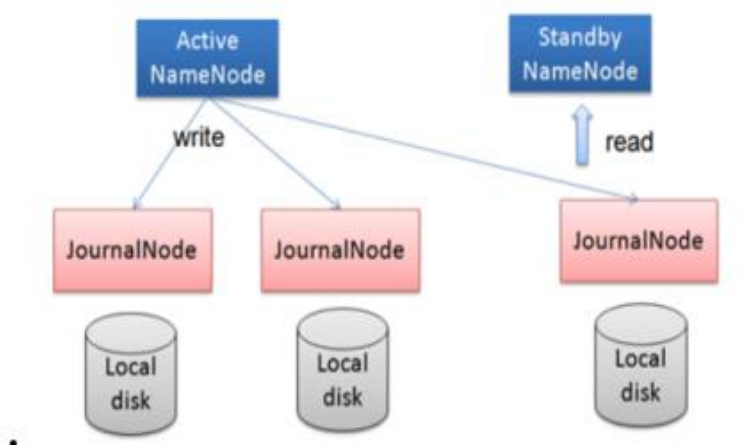
當發生故障時,Active 的 NN 掛掉後,Standby NN 會在它成為 Active NN 前,讀取所有的 JN 裡面的修改日誌,這樣就能高可靠的保證與掛掉的 NN 的目錄鏡像樹一致,然後無縫的接替它的職責,維護來自客戶端請求,從而達到一個高可用的目的。
在 HA 模式下,datanode 需要確保同一時間有且只有一個 NN 能命令 DN。為此:每個 NN 改變狀態的時候,向 DN 發送自己的狀態和一個序列號。
DN 在運行過程中維護此序列號,當 failover 時,新的 NN 在返回 DN 心跳時會返回自己的 active 狀態和一個更大的序列號。DN 接收到這個返回則認為該 NN 為新的 active。
如果這時原來的 active NN 恢復,返回給 DN 的心跳信息包含 active 狀態和原來的序列號,這時 DN 就會拒絕這個 NN 的命令。
Failover Controller
HA 模式下,會將 FailoverController 部署在每個 NameNode 的節點上,作為一個單獨的進程用來監視 NN 的健康狀態。 r FailoverController 主要包括三個組件:
HealthMonitor: 監控 NameNode 是否處於 unavailable 或 unhealthy 狀態。當前通過RPC 調用 NN 相應的方法完成。
ActiveStandbyElector: 監控 NN 在 ZK 中的狀態。
ZKFailoverController: 訂閱 HealthMonitor 和 ActiveStandbyElector 的事件,並管理 NN 的狀態,另外 zkfc 還負責解決 fencing(也就是腦裂問題)。
上述三個組件都在跑在一個 JVM 中,這個 JVM 與 NN 的 JVM 在同一個機器上。但是兩個獨立的進程。一個典型的 HA 集群,有兩個 NN 組成,每個 NN 都有自己的 ZKFC 進程。
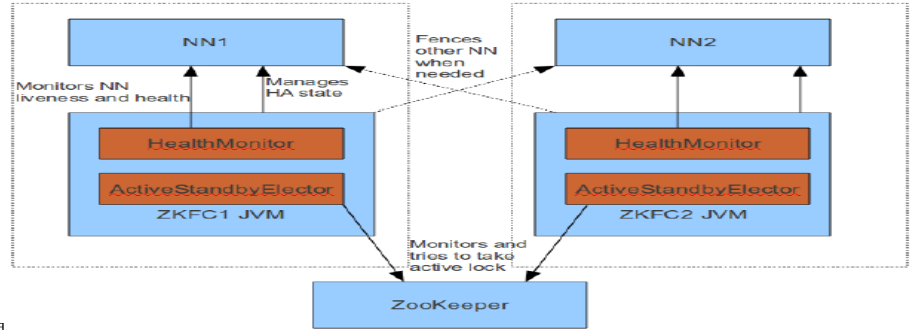
ZKFailoverController 主要職責:
- 健康監測:周期性的向它監控的 NN 發送健康探測命令,從而來確定某個 NameNode是否處於健康狀態,如果機器宕機,心跳失敗,那麼 zkfc 就會標記它處於一個不健康的狀態
- 會話管理:如果 NN 是健康的,zkfc 就會在 zookeeper 中保持一個打開的會話,如果 NameNode 同時還是 Active 狀態的,那麼 zkfc 還會在 Zookeeper 中占有一個類型為短暫類型的znode,當這個 NN 掛掉時,這個 znode 將會被刪除,然後備用的NN 將會得到這把鎖,升級為主 NN,同時標記狀態為 Active
- 當宕機的 NN 新啟動時,它會再次註冊 zookeper,發現已經有 znode 鎖了,便會自動變為 Standby 狀態,如此往複迴圈,保證高可靠,需要註意,目前僅僅支持最多配置 2 個 NN
- master 選舉:通過在 zookeeper 中維持一個短暫類型的 znode,來實現搶占式的鎖機制,從而判斷那個 NameNode 為 Active 狀態
Yarn HA
Yarn 作為資源管理系統,是上層計算框架(如 MapReduce,Spark)的基礎。在 Hadoop2.4.0 版本之前,Yarn 存在單點故障(即 ResourceManager 存在單點故障),一旦發生故障,恢復時間較長,且會導致正在運行的 Application 丟失,影響範圍較大。從 Hadoop 2.4.0版本開始,Yarn 實現了 ResourceManager HA,在發生故障時自動 failover,大大提高了服務的可靠性。
ResourceManager(簡寫為 RM)作為 Yarn 系統中的主控節點,負責整個系統的資源管理和調度,內部維護了各個應用程式的 ApplictionMaster 信息、NodeManager(簡寫為 NM)信息、資源使用等。由於資源使用情況和 NodeManager 信息都可以通過 NodeManager 的心跳機制重新構建出來,因此只需要對 ApplicationMaster 相關的信息進行持久化存儲即可。
在一個典型的 HA 集群中,兩台獨立的機器被配置成 ResourceManger。在任意時間,有且只允許一個活動的 ResourceManger,另外一個備用。切換分為兩種方式:
手動切換:在自動恢復不可用時,管理員可用手動切換狀態,或是從 Active 到 Standby,或是從 Standby 到 Active。
自動切換:基於 Zookeeper,但是區別於 HDFS 的 HA,2 個節點間無需配置額外的 ZFKC守護進程來同步數據。


