
2018-07-12 文件操作 1 文件的讀 1.1 R(只讀) Log文件中有“hello,世界你好” 1.2 Rb(取出來的是bytes類型,在rb模式下,不能使用encoding) 直接讀取文件存儲的二進位,但在pycharm中將二進位轉換成了16進位來顯示。 Rb的作用:當處理一些非文本數據 ...
2018-07-12
文件操作
1 文件的讀
1.1 R(只讀)
Log文件中有“hello,世界你好”
f = open('file/log',mode='r',encoding='utf-8')
Read_new = f.read()
print(Read_new)
f.close()
# 結果:哈嘍,世界你好
1.2 Rb(取出來的是bytes類型,在rb模式下,不能使用encoding)
直接讀取文件存儲的二進位,但在pycharm中將二進位轉換成了16進位來顯示。
# rb
f = open('file/log',mode='rb')
Read_now_bytes = f.read()
print(Read_now_bytes)
f.close()
# 結果:b'\xe5\x93\x88\xe5\x96\xbd,\xe4\xb8\x96\xe7\x95\x8c\xe4\xbd\xa0\xe5\xa5\xbd'
中文在UTF-8編碼中,一個漢字占用三個字元,可以看出哈嘍,世界你好,六個字一共占用了18個字元,每一個“\x”都是一位
Rb的作用:當處理一些非文本數據值,要用到,比如MP3,視屏,圖片等,還有上傳,下載,我們看的直播也都是傳輸的是rb這種格式。
當文件過大時,直接read是不合適的,很容易把電腦記憶體溢出
1.3 read的功能操作
1.3.1 r讀取n個字元
# 讀取n個字元
f = open('file/log',mode='r',encoding='utf-8')
Read_new_n = f.read(4) # 讀的是漢字個數,從頭開始,讀取4個
print(Read_new_n)
f.close()
# 白日依山
那麼多次執行呢?
f = open('file/log',mode='r',encoding='utf-8')
Read_new_n_1 = f.read(4)
Read_new_n_2 = f.read(4)
Read_new_n_3 = f.read(4)
Read_new_n_4 = f.read(4)
Read_new_n_5 = f.read(4)
print(Read_new_n_1,end="a")
print(Read_new_n_2,end="a")
print(Read_new_n_3,end="a")
print(Read_new_n_4,end="a")
print(Read_new_n_5)
# 結果:
# f.close()
# 白日依山a盡,
# 黃a河入海流a。
# 欲窮a千里目,
# 第一次從開頭開始讀娶四個字(標點符號,換行符都算),第二次從現在游標的為值繼續讀取4個字
1.3.2 使用rb讀取指定的字元數
# rb讀取n個字元
f = open('file/log',mode='rb')
Read_new = f.read(3)
Read_new_1 = f.read(3)
print(Read_new)
print(Read_new_1)
f.close()
# 結果:
# b'\xe7\x99\xbd'
# b'\xe6\x97\xa5'
# 可以看出每次讀取了三個位元組,
1.3.3 readline 一行一行的讀取
# readline 一行一行的讀取
f = open('file/log',mode='r',encoding='utf-8')
Read_line = f.readline()
print(Read_line)
f.close()
# 結果:白日依山盡, 讀取的是第一行內容
如果早readline中加上參數是怎樣。
f = open('file/log',mode='r',encoding='utf-8')
Read_line = f.readline(3)
print(Read_line)
f.close()
# 結果:白日依
# 3代表這一行的前幾個字元,加入輸入的字元超過了最大的字元數,就只會顯示到本行末尾
1.3.4 readlines,將所有的行都讀出來
f = open('file/log',mode='r',encoding='utf-8')
Read_lines = f.readlines()
print(Read_lines)
f.close()
# ['白日依山盡,\n', '黃。河入海流\n', '欲窮千里目,\n', '更上一層樓。']
# 將文本中的所有行全部列印出來,不過是放到了列表中,還把換行符都列印出來,要是用的話可以用strip去除換行符
1.3.5, for迴圈讀取
f = open('file/log',mode='r',encoding='utf-8')
for Read_for in f:
print(Read_for,end="")
# 結果:
# 白日依山盡,
# 黃河入海流。
# 欲窮千里目,
# 更上一層樓。
1.3.6 查詢文件是否可讀
f = open('file/log',mode='r',encoding='utf-8')
Read_YN = f.readable()
print(Read_YN)
f.close()
# 結果:True 當mode為“r”是文件就是可讀的,而且是只讀
f = open('file/log',mode='w',encoding='utf-8')
Read_YN = f.readable()
print(Read_YN)
f.close()
# 結果:False 當mode為“w”是,去判斷這個文件是不是可讀,返回False
2 文件的寫
2.1 w(只寫)
在寫的時候,如果目標文件不存在,將會創建,若果存在,將會刪除裡面的內容,寫入新的內容。
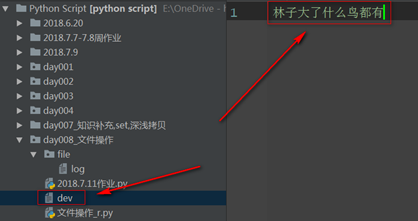
f = open('dev',mode='w',encoding='utf-8')
Write_only = f.write("林子大了什麼鳥都有")
f.flush()
f.close()
結果:
2.2 wb(二進位寫入)
Wb模式下可以不指定“encoding”的編碼格式,但是再寫的時候需要編碼格式
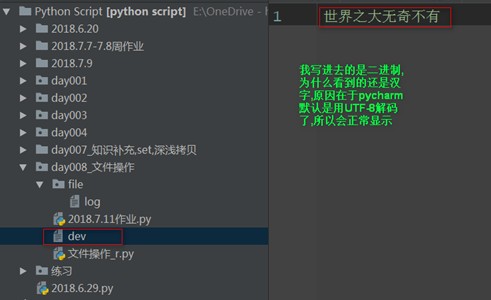
f = open('dev',mode='wb')
Write_bytes = f.write("世界之大無奇不有".encode('utf-8'))
f.flush()
f.close()
3 文件的追加
3.1 a(追加)
追加在文件的末尾
f = open('dev',mode='a',encoding='utf-8')
file_add = f.write('我來了,你還在嗎?')
f.flush()
f.close()
之前的內容還是存在,只是在末尾添加了新的內容

3.2 ab(二進位追加)
4 r+,r+b(讀寫模式)
對於讀寫模式. 必須是先讀. 後寫入,因為預設游標是在開頭的. 準備讀取的. 當讀完了了之後再進⾏行行寫入. 我們以後使⽤用頻率最高的模式就是r+
# r+ 讀寫
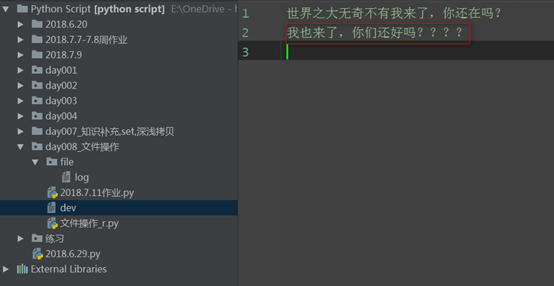
f = open('dev',mode='r+',encoding='utf-8')
read_1 = f.read()
print(read_1)
f.write("\n我也來了,你們還好嗎????")
f.flush()
f.close()
# 世界之大無奇不有我來了,你還在嗎? 先讀後寫,否則會先從頭開始寫,覆蓋原有的字元,然後讀剩下的字元,加入全部覆蓋,那麼久就沒有內容可讀了
深坑請註意: 在r+模式下. 如果讀取了內容. 不論讀取內容多少. 游標顯⽰的是多少. 再寫入或者操作⽂件的時候都是在結尾進行的操作.
5 w+,w+b(寫讀模式)
先將所有的內容清空. 然後寫入. 最後讀取. 但是讀取的內容是空的, 不常用
# w+,w+b 寫讀模式
f = open('dev',mode='w+',encoding='utf-8')
f.write("哈嘍哈嘍,大家好,才是真的好")
read_1 = f.read()
print(read_1)
f.flush()
f.close()
6 a+,a+b(追加讀)
a+模式下, 不論先讀還是後讀. 都是讀取不到數據的.
# a+ a+b 追加讀
f = open('dev',mode='a+',encoding='utf-8')
f.write("594504110")
read_1 = f.read()
print(read_1)
f.flush()
f.close()
7其他操作
7.1 seek(移動游標)
1. seek(n) 游標移動到n位置, 註意, 移動的單位是byte. 所以如果是UTF-8的中文部分要是3的倍數.通常我們使用seek都是移動到開頭或者結尾.
移動到開頭: seek(0)
移動到結尾: seek(0,2) seek的第⼆個參數表⽰的是從哪個位置進⾏偏移, 預設是0, 表
⽰開頭, 1表⽰當前位置, 2表⽰結尾
7.2 tell (查看當前游標的位置)
tell()使用可以幫我們獲取到當前游標在什麼位置
7.3 truncate(截斷文件)
所以如果想做截斷操作. 記住了. 要先挪動游標. 挪動到你想要截斷的位置. 然後再進行截斷關於truncate(n), 如果給出了n. 則從開頭進行截斷, 如果不給n, 則從當前位置截斷. 後面的內容將會被刪除
7.4 文件操作的另一種方式
import os
with open('dev',mode='r',encoding='utf-8') as f:
for read_1 in f:
print(read_1)
# 哈嘍哈嘍,大家好,才是真的好594504110
os.remove('dev') #刪除這個文件
os.renames("old","new") #文件重命名


