
在鎖與事務系列里已經寫完了上篇中篇,這次寫完下篇。這個系列俺自認為是有條不紊的進行,但感覺鎖與事務還是有多很細節沒有講到,溫故而知新可以為師矣,也算是一次自我提高總結吧,也謝謝大伙的支持。在上一篇的末尾寫了事務隔離級別的不同表現,還沒寫完,只寫到了重覆讀的不同隔離表現,這篇繼續寫完序列化,快照的不同 ...
在鎖與事務系列里已經寫完了上篇中篇,這次寫完下篇。這個系列俺自認為是有條不紊的進行,但感覺鎖與事務還是有多很細節沒有講到,溫故而知新可以為師矣,也算是一次自我提高總結吧,也謝謝大伙的支持。在上一篇的末尾寫了事務隔離級別的不同表現,還沒寫完,只寫到了重覆讀的不同隔離表現,這篇繼續寫完序列化,快照的不同隔離表現,事務隔離級別的總結。最後講下事務的死鎖,事務的分散式,事務的併發檢查。
一. 事務隔離不同表現
設置序列化
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
設置行版本控制已提交讀
ALTER DATABASE Test SET READ_COMMITTED_SNAPSHOT on; SET TRANSACTION ISOLATION LEVEL READ COMMITTED
設置快照隔離
ALTER DATABASE Test SET ALLOW_SNAPSHOT_ISOLATION ON; SET TRANSACTION ISOLATION LEVEL SNAPSHOT
1.1 已重覆讀和序列化與其它事務併發,的區別如下表格:
|
可重覆讀 |
序列化 | 其它事務 |
|
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ |
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE |
|
|
begin tran select count(*) from product where memberID=9708 這裡顯示500條數據,事務還沒有結束 |
begin tran select count(*) from product where memberID=9708 這裡顯示500條數據,事務還沒有結束 |
|
|
begin tran insert into product values('test2',9708) 其它事務里,想增加一條數據。 如果併發的事務是可重覆讀, 這條數據可以插入成功。 如果併發的事務是序列化, 這條數據插入是阻塞的。 |
||
|
select count(*) from product where memberID=9708 在事務里再次查詢時,發現顯示501條數據 |
select count(*) from product
where memberID=9708 在事務再次查詢時,還是顯示500條數據 |
|
|
commit tran 在一個事務里,對批數據多次讀取,符合條件 的行數會不一樣。 |
commit tran 事務結束 |
如果併發是可序列化並且commit, 其它事務新增阻塞消失,插入開始執行。 |
1.2 已提交讀、行版本控制已提交讀、快照隔離,與其它事務併發,的區別如下表格:
|
已提交讀 |
行版本控制已提交讀 | 快照隔離 | 其它事務 |
|
SET TRANSACTION ISOLATION LEVEL READ COMMITTED |
ALTER DATABASE Test SET SET TRANSACTION ISOLATION |
ALTER DATABASE TEST SET SET TRANSACTION ISOLATION |
|
|
begin tran select model from product 得到值為test |
begin tran select model from product 得到值為test |
begin tran select model from product 得到值為test |
|
|
begin tran |
|||
|
select model from product 事務里再次查詢 阻塞 |
select model from product 事務里再次查詢值為test, 讀到行版本 |
select model from product |
|
| 阻塞解除,再次查詢返回 test1 |
再次查詢 test1 |
再次查詢 test 其它事務提交後,這裡讀取還是舊數據 |
commit tran |
| 事務里updaate修改 修改成功 | 事務里updaate修改 修改成功 | 事務里updaate修改, 修改失敗報錯 |
|
二. 事務總結
2.1 事務不同隔離級別的優缺點,以及使用場景 如下表格:
| 隔離級別 |
優點 |
缺點 | 使用場景 |
| 未提交讀 | 讀數據的時候,不申請共用鎖,所以不會被阻塞 | 讀到的數據,可能會臟讀,不一致。 | 如做年度,月度統計報表,數據不一定要非常精確 |
| 已提交讀 | 比較折中,而且是推薦的預設設置 | 有可能會阻塞,在一個事務里,多次讀取相同的數據行,得到的結果可能不同。 | 一般業務都是使用此場景 |
| 可重覆讀 | 在一個事務里,多次讀取相同的數據行,得到的結果可保證一致、 | 更嚴重的阻塞,在一個事務里,讀取符合某查詢的行數,會有變化(這是因為事務里允許新增) | 如當我們在事務里需要,多次統計查詢範圍條件行數, 做精確邏輯運算時,需要考慮邏輯是否會前後不一致. |
| 可序列化 | 最嚴重格的數據保護,讀取符合某查詢的行數,不會有變化(不允許新增)。 | 其它事務的增,刪,改,查 範圍內都會阻塞 | 如當我們在寫事務時,不用考慮新增數據帶來的邏輯錯誤。 |
| 行版本控制已提交讀 |
阻塞大大減少(讀與讀不阻塞,讀與寫不阻塞) 阻塞減少,能讀到新數據 |
寫與寫還是會阻塞,行版本是存放在tempdb里,數據修改的越多,需要 存儲的信息越多,維護行版本就 需要越多的的開銷 |
如果預設方式阻塞比較嚴重,推薦用行版本控制已提交讀,改善性能 |
| 快照隔離 |
阻塞大大減少(讀與讀不阻塞,讀與寫不阻塞) 阻塞減少,有可能讀到舊數據 |
維護行版本需要額外開銷,且可能讀到舊的數據 | 允許讀取稍微比較舊版本信息的情況下 |
2.2 鎖的隔離級別(補充)
瞭解了事務的隔離級別,鎖也是有隔離級別的,只是它針對是單獨的sql查詢。下麵包括顯示如下
select COUNT(1) from dbo.product(HOLDLOCK)
|
HOLDLOCK |
在該表上保持共用鎖,直到整個事務結束,而不是在語句執行完立即釋放所添加的鎖。 與SERIALIZABLE一樣 |
|
NOLOCK |
不添加共用鎖和排它鎖,僅應用於SELECT語句 與READ UNCOMMITTED一樣 |
|
PAGLOCK |
指定添加頁鎖(否則通常可能添加表鎖)。 |
|
READPAST |
跳過已經加鎖的數據行, 僅應用於READ COMMITTED隔離性級別下事務操作中的SELECT語句操作 |
|
ROWLOCK |
使用行級鎖,而不使用粒度更粗的頁級鎖和表級鎖 建議中用在UPDATE和DELETE語句中。 |
|
TABLOCKX |
表上使用排它鎖, 這個鎖可以阻止其他事務讀或更新這個表的數據 |
|
UPDLOCK |
指定在讀表中數據時設置更新鎖(update lock)而不是設置共用鎖,作用是允許用戶先讀取數據(而且不阻塞其他用戶讀數據),並且保證在後來再更新數據時,這一段時間內這些數據沒有被其他用戶修改 |
五.分散式事務
分散式事務是跨越兩個或多個稱為資源管理器的伺服器。 稱為事務管理器的伺服器組件必須在資源管理器之間協調事務管理。在 .NET Framework 中,分散式事務通過 System.Transactions 命名空間中的 API 進行管理。 如果涉及多個永久資源管理器,System.Transactions API 會將分散式事務處理委托給事務監視器,例如 Microsoft 分散式事務協調程式 (MS DTC),在Windows服務里該服務叫Distributed Transaction Coordinator 預設未啟動。
在sql server里 分散式是通過BEGIN DISTRIBUTED TRANSACTION 的T-SQL來實現,是分散式事務處理協調器 (MS DTC) 管理的 Microsoft 分散式事務的起點。執行 BEGIN DISTRIBUTED TRANSACTION 語句的 SQL Server 資料庫引擎的實例是事務創建者。並控制事務的完成。 當為會話發出後續 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 語句時,控制事務實例請求 MS DTC 在所涉及的所有實例間管理分散式事務的完成(事務級別的快照隔離不支持分散式事務)。
在執行T-sql里 查詢多個資料庫主要是通過引用鏈接伺服器的分散式查詢,下麵添加了RemoteServer鏈接伺服器
USE AdventureWorks2012;
GO
BEGIN DISTRIBUTED TRANSACTION;
-- Delete candidate from local instance.
DELETE AdventureWorks2012.HumanResources.JobCandidate
WHERE JobCandidateID = 13;
-- Delete candidate from remote instance.
DELETE RemoteServer.AdventureWorks2012.HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT TRANSACTION;
GO
六.事務死鎖
6.1 在關係型資料庫里都有死鎖的概念,在併發訪問量高時,事務里或者T-sql大批量操作(特別是修改刪除結果集),都有可能導致死鎖。死鎖是由兩個互相阻塞的線程組成也稱為抱死。sql server死鎖監視器進程會定期檢查死鎖,預設間隔為5秒,會自動判斷將回滾開銷影響最少的事務作為死鎖犧牲者,並收到1025 錯誤,消息模板來自master.dbo.sysmessages表的where error=1205。當發生死鎖時要瞭解兩方進程的sessionid各是多少, 各會話的查詢語句,衝突資源是什麼。請查看死鎖的分析排查。
會產生死鎖的資源主要是:鎖 (就是上篇講的數據行,頁,表等資源),其它的死鎖包括如:1. 工作者線程調度程式或CLR同步對象。2.兩個線程需要更多記憶體,但獲得授權前一個必須等待另一個。3.同一個查詢的並行線程。4.多動態結果集(MARS)資源線程內部衝突。這四種很少出現死鎖,重點只要關註鎖資源帶來的死鎖。
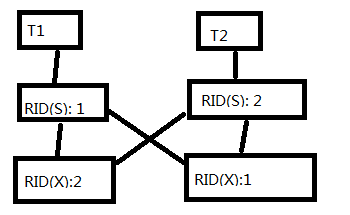
6.2 下麵事務鎖資源產生死鎖的原理:
1. 事務T1和事務T2 分別占用共用鎖RID第1行和共用鎖RID第2行。
2. 事務T1更新RID2試圖獲取X阻塞,事務T2更新RID2試圖獲取X阻塞。
3. 事務各自占有共用鎖未釋放,而要申請對方X鎖會排斥一切鎖
6.3 死鎖與阻塞的區別
阻塞是指:當一個事務請求一個資源嘗試獲取鎖時,被其它事務鎖定,請求的事務會一直等待,直到其它事務把該鎖釋放,這就發生了阻塞,預設情況sqlserver會一直等下去。所以阻塞往往能持續很長時間,這對程式的併發性能影響很大。
死鎖是兩個或多個進程之間的相互等待,一般在5秒就會檢測出來,消除死鎖。併發性能不像阻塞那麼嚴重。
阻塞是單向的,互相阻塞就變成了死鎖。
6.3 儘量避免死鎖的方法
按同一順序訪問對象
避免事務中的用戶交互
保持事務簡短
合理使用隔離級別
調整語句的執行計劃,減少鎖的申請數目。
七.事務併發檢查
在檢查併發方面,有很多種方式像原來的如sp_who,sp_who2等系統存儲過程,perfmon計數器,sql Trace/profiler工具等,檢測和分析併發問題,還包括sql server 2005以及以上的:
DMV 特別是sys.dm_os_wait_stats和sys.dm_os_waiting_tasks ,這裡簡單講下併發檢查
例如:查詢用戶會話的相關信息
SELECT blocking_session_id FROM sys.dm_os_waiting_tasks WHERE session_id>50
blocking_session_id 阻塞會話值有時為負數:
-2 :被阻塞資源屬於孤立分散式事務。
-3: 被阻塞資源屬於遞延恢復事務。
-4: 對於鎖存器等待,內鎖存器狀態轉換阻止了session的識別。
例如:下麵查詢阻塞超5秒的等待
SELECT blocking_session_id FROM sys.dm_os_waiting_tasks WHERE wait_duration_ms>5000
例如:只關註鎖的阻塞,可以查看sys.dm_tran_locks
SELECT * FROM sys.dm_tran_locks WHERE request_status='wait'
通過sys.dm_exec_requests查看用戶請求
通過sqlDiag.exe收集運行系統的信息
通過errorlog里打開跟蹤標識1222 來分析死鎖
通過sys.sysprocess 檢測阻塞。


