
Q: 為什麼要引入鏈表的概念?它是解決什麼問題的? A: 數組作為數據存儲結構有一定的缺陷,在無序數組中,搜索是低效的;而在有序數組中,插入效率又很低;不管在哪一個數組中刪除效率都很低;況且一個數組創建後,它的大小是不可改變的。 A: 在本篇中,我們將學習一種新的數據結構 —— 鏈表,它可以解決上面 ...
Q: 為什麼要引入鏈表的概念?它是解決什麼問題的?
A: 數組作為數據存儲結構有一定的缺陷,在無序數組中,搜索是低效的;而在有序數組中,插入效率又很低;不管在哪一個數組中刪除效率都很低;況且一個數組創建後,它的大小是不可改變的。
A: 在本篇中,我們將學習一種新的數據結構 —— 鏈表,它可以解決上面的一些問題,鏈表可能是繼數組之後第二種使用最廣泛的通用存儲結構了。
Q: 結點?
A: 在鏈表中,每個數據項都被包含在“結點”中,可以使用Node, 或者Entry等名詞來表示結點,本篇使用Entry來表示。每個Entry對象中包含一個對下一個結點引用的欄位(通常叫做next),單鏈表中每個結點的結構圖如下: 
定義單鏈表結點的類定義如下:
class Entry<E> {
E mElement;
Entry<E> mNext;
public Entry(E element, Entry<E> next) {
mElement = element;
mNext = next;
}
}
Q: 單鏈表?
A: 構成鏈表的結點只有一個指向後繼結點的指針域。
Q: 單鏈表的Java實現?
A: 示例:SingleLinkedList.java
A: LinkedList類只包含一個數據項mHeader,叫做表頭:即對鏈表中第一個節點的引用。它是唯一的鏈表需要維護的永久信息,用以定位所有其他的鏈接點。從mHeader出發,沿著鏈表通過每個結點的mNext欄位,就可以找到其他的結點。
A: addFirst()方法 —— 作用是在表頭插入一個新結點。
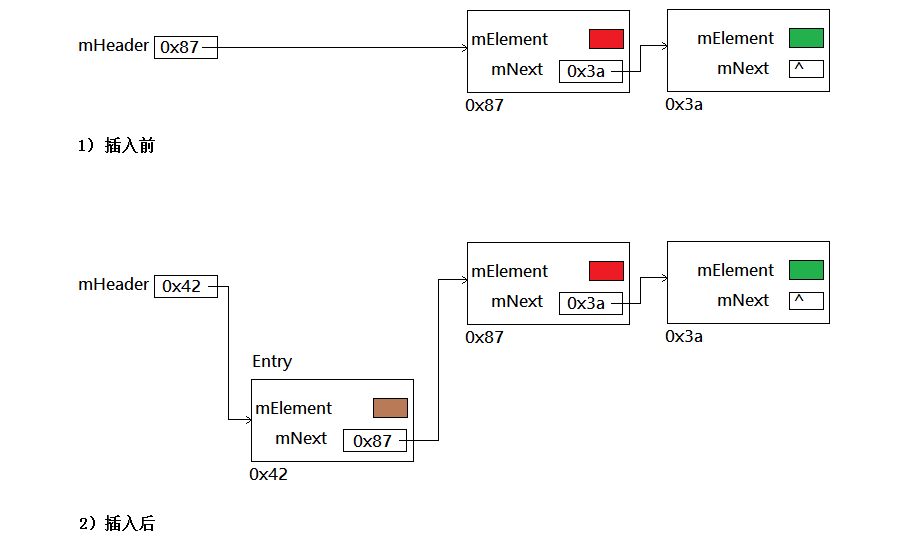
A: removeFirst()方法 —— 是addFirst()方法的逆操作,它通過把mHeader重新指向第二個結點,斷開了和第一個結點的連接。 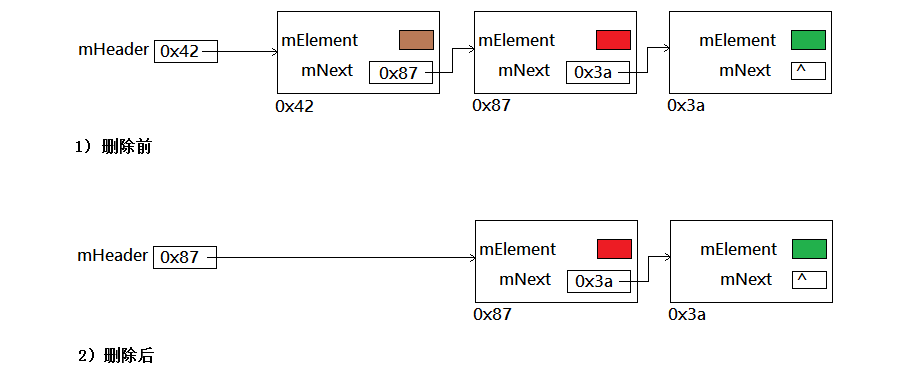
在C++中,從鏈表取下一個結點後,需要考慮如何釋放這個結點。它仍然在記憶體中的某個地方,但是現在沒有任何指針指向它,將如何處理它呢?在Java中,垃圾回收(GC)將在未來的某個時刻銷毀它,現在這不是程式員操心的工作。
註意,removeFirst()方法假定鏈表不是空的,因此調用它之前,應該首先調用empty()方法核實這一點。
Q: 如何查找和刪除指定的結點?
A: indexOf(Object)方法 —— 返回此列表中首次出現的指定元素的索引,如果此列表中不包含該元素,則返回 -1。
get(int)方法 —— 返回此列表中指定位置處的元素。
A: remove(Object) —— 從此列表中移除首次出現的指定元素(如果存在)。
先搜索要刪除的結點,如果找到了,必須把前一個結點和後一個結點連起來,知道前一個結點的唯一方法就是擁有一個對它的引用previous(每當current變數賦值為current.next之前,先把previous變數賦值為current)。 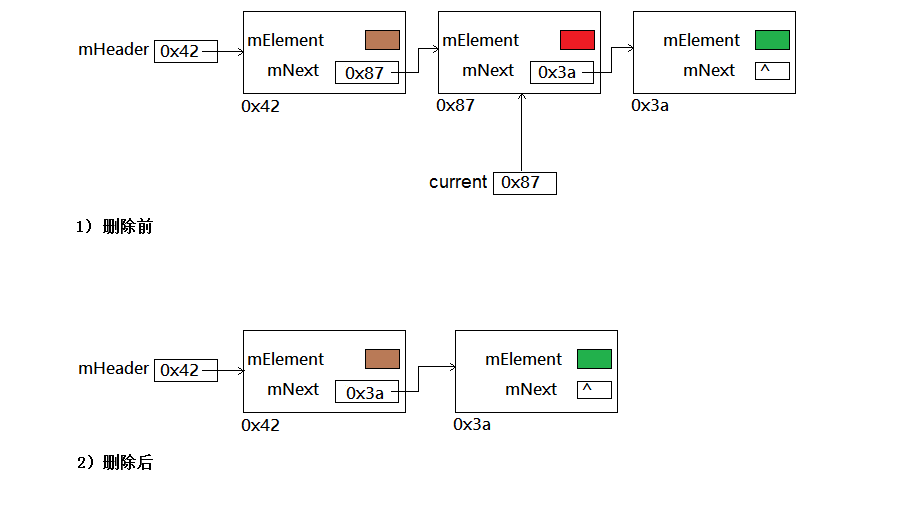
A: 示例: SingleLinkedList.java
Q: 雙端鏈表?
A: 雙端鏈表(double-ended list )是在上邊的單鏈表基礎上加了一個表尾,即對最後一個結點的引用。如下圖: 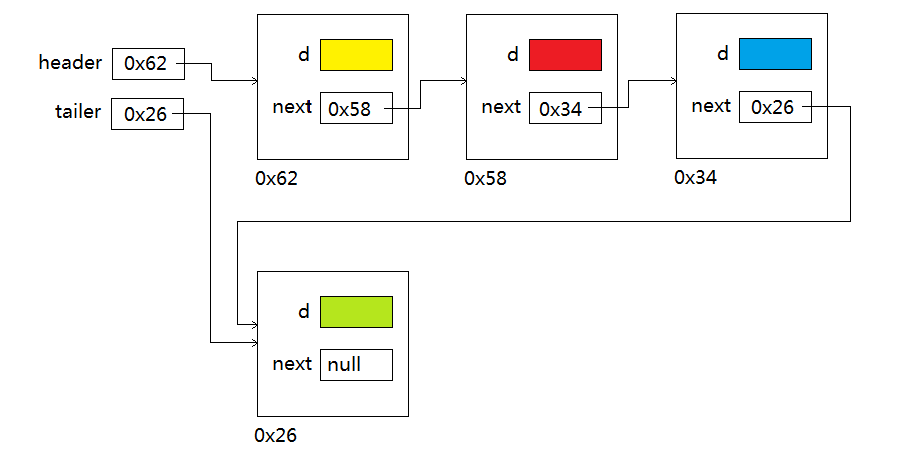
A: 對最後一個結點的引用允許像表頭一樣,在表尾直接插入一個結點。當然,仍然可以在普通的單鏈表的表尾插入一個結點,方法是遍歷整個鏈表直到到達表尾,但是這種方法效率很低。
Q: 雙端鏈表的Java實現?
A: 示例: DoubleEndedList.java
A: DoubleEndedList有兩個項,header和tailer,一個指向鏈表中的第一個結點,另一個指向最後一個結點。
A: 如果鏈表中只有一個結點,header和last都指向它。如果沒有結點,兩個都為null值。
A: 如果鏈表只有一個結點,刪除時tailer必須被賦值為null。
A: addLast()方法 —— 在表尾插入一個新結點。
Q: 鏈表的效率?
A: 在表頭插入和刪除速度很快,僅需要改變一兩個引用值,所以花費O(1)的時間。
A: 查找、刪除和在指定結點的前面插入都需要搜索鏈表中一半的結點,需要O(N)次比較,在數組中執行這些操作也需要O(N)次比較。但是鏈表仍然要快一些,因為插入和刪除結點時,鏈表不需要移動任何東西。
A: 鏈表比數組還有一個優點是,鏈表需要多少記憶體就可以用多少記憶體,不像數組在創建時大小就固定了。
A: 向量是一種可擴展的數組,它可以通過可變長度解決這個問題,但是它經常只允許以固定的增量擴展(比如快要溢出的時候,就增加1倍的數組容量)。這個解決方案在記憶體使用效率上來說還是要比鏈表低。
Q: 用鏈表實現的棧?
A: 示例:Stack.java
A: 棧的使用者不需要知道棧用的是鏈表還是數組實現。 因此Stack類的測試用例在這兩個上是沒有分別的。
Q: 用鏈表實現的隊列?
A: 示例:Queue.java
A: 展示了一個用雙端鏈表實現的隊列。
Q: 什麼時候應該使用鏈表而不是數組來實現棧和隊列呢?
A: 這一點要取決於是否能精準地預測棧或隊列需要容納的數據量。如果這一點不是很清楚的話,鏈表就比數組表現出更好的適用性。兩者都很快,所以速度可能不是考慮的重點。
Q: 什麼是抽象數據類型(ADT)?
A: 簡單來說,它是一種考慮數據結構的方式:著重於它做了什麼,而忽略它是怎麼做的。
A: 棧和隊列都是ADT的例子,前面已經看到棧和隊列既可以用數組實現,也可以使用鏈表實現,而對於使用它們的用戶完全不知道具體的實現細節(用戶不僅不知道方法是怎樣運行,也不知道數據是如何存儲的)。
A: ADT的概念在軟體設計過程中很重要,如果需要存儲數據,那麼就要從它的實際操作上開始考慮,比如,是存取最後一個插入的數據項?還是第一個?是特定值的項?還是在特定位置上的項?回答這些問題會引出ADT的定義。
A: 只有在完整定義ADT後,才應該考慮細節問題。
A: 通過從ADT規範中剔除實現的細節,可以簡化設計過程,在未來的某個時刻,易於修改實現。如果用戶只接觸ADT介面,應該可以在不“干擾”用戶代碼的情況下修改介面的實現。
A: 當然,一旦設計好ADT,必須仔細選擇內部的數據結構,以使規定的操作的效率儘可能高。例如隨機存取元素a,那麼用鏈表表示就不夠好,因為對鏈表來說,隨機訪問不是一個高效的操作,選擇數據會得到更好的效果。
Q: 有序鏈表?
A: 在有序鏈表中,數據是按照關鍵值有序排列的,有序鏈表的刪除常常是只限於刪除在表頭的最小(或最大)的節點。
A: 一般,在大多數需要使用有序數組的場合也可以使用有序鏈表。有序鏈表的優勢在於插入的速度,因為元素不需要移動,而且鏈表可以隨時擴展所需記憶體,數組只能局限於一個固定大小的記憶體。
A: 示例:SortedLinkedList.java
A: 當演算法找到要插入的位置,用通常的方式插入數據項:把新節點的next欄位指向下一個節點,然後把前一個結點的next欄位指向新節點。然而,需要考慮一些特殊情況:節點有可能插在表頭,或者表尾。
Q: 有序鏈表的效率?
A: 在有序鏈表插入或刪除某一項最多需要O(N)次比較(平均N/2),因為必須沿著鏈表一步一步走才能找到正確的位置。然而,可以在O(1)的時間內找到或刪除最小值,因為它總在表頭。
A: 如果一個應用頻繁地存取最小項,且不需要快速地插入,那麼有序鏈表是一個有效的方案選擇,例如,優先順序隊列可以用有序鏈表來實現。
Q: 鏈表插入排序(List Insertion Sort)?
A: 有序鏈表可以用於一種高效的排序機制。假設有一個無序數組,如果從這個數組中取出數據,然後一個一個地插入有序鏈表,它們自動地按照順序排列。然後把它們從有序鏈表刪除,重新放入數組,那麼數組就排好序了。
A: 本質上與基於數組的插入排序是一樣的,都是O(N2)的比較次數,只是說對於數組會有一半已存在的數據會涉及移動,相當於N2/4次移動,相比之下,鏈表只需2 * N次移動:一次是從數組到鏈表,一次是從鏈表到數組。
A: 不過鏈表插入有一個缺點:就是它要開闢差不多兩倍的空間。
A: 示例: LinkedListSort.java
Q: 雙向鏈表?
A: 雙向鏈表提供了這樣的能力,即允許向前遍歷,也允許向後遍歷整個鏈表,其中秘密在於它的每個數據結點中都有兩個指針,分別指向直接後繼和直接前驅。
A: 雙向鏈表不必是雙端鏈表(保持一個對鏈表最後一個元素的引用),但這種方式是很有用的。所以下麵的示例將包含雙端的性質。
Q: 基於雙向鏈表的雙端鏈表的Java實現?
A: 示例:DoublyLinkedList.java
A: addFirst(E)方法:將指定元素插入此列表的開頭。 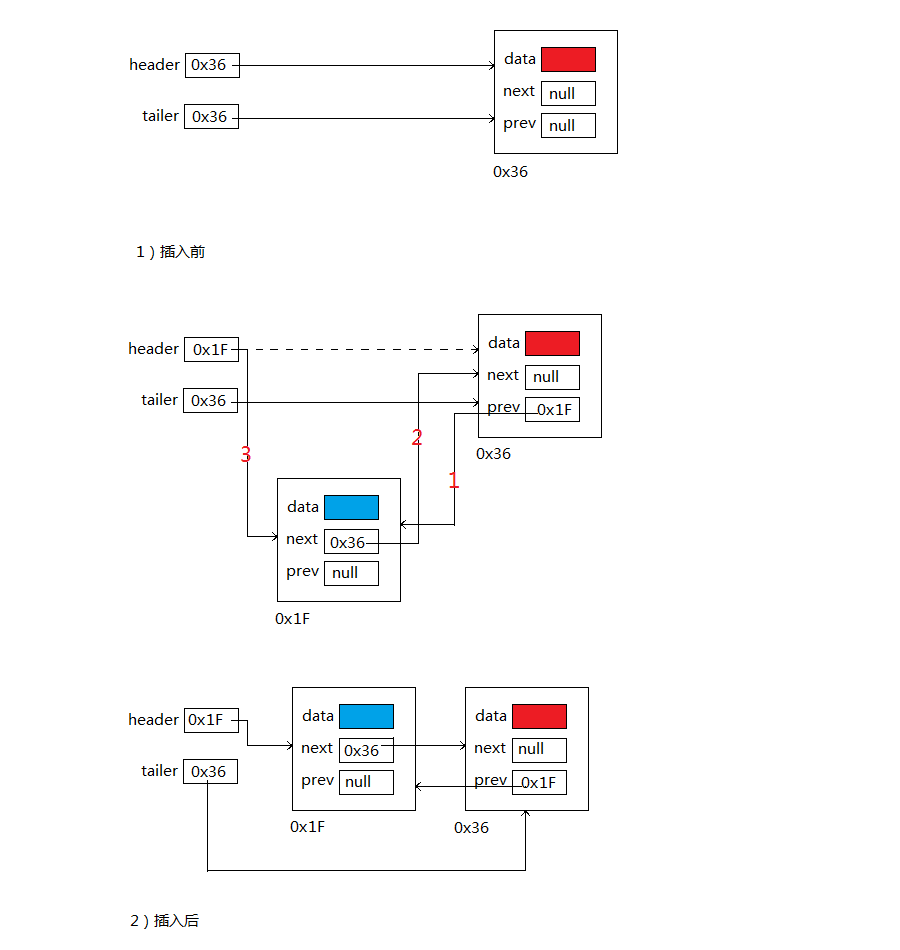
A: addLast(E)方法:將指定元素添加到此列表的結尾。 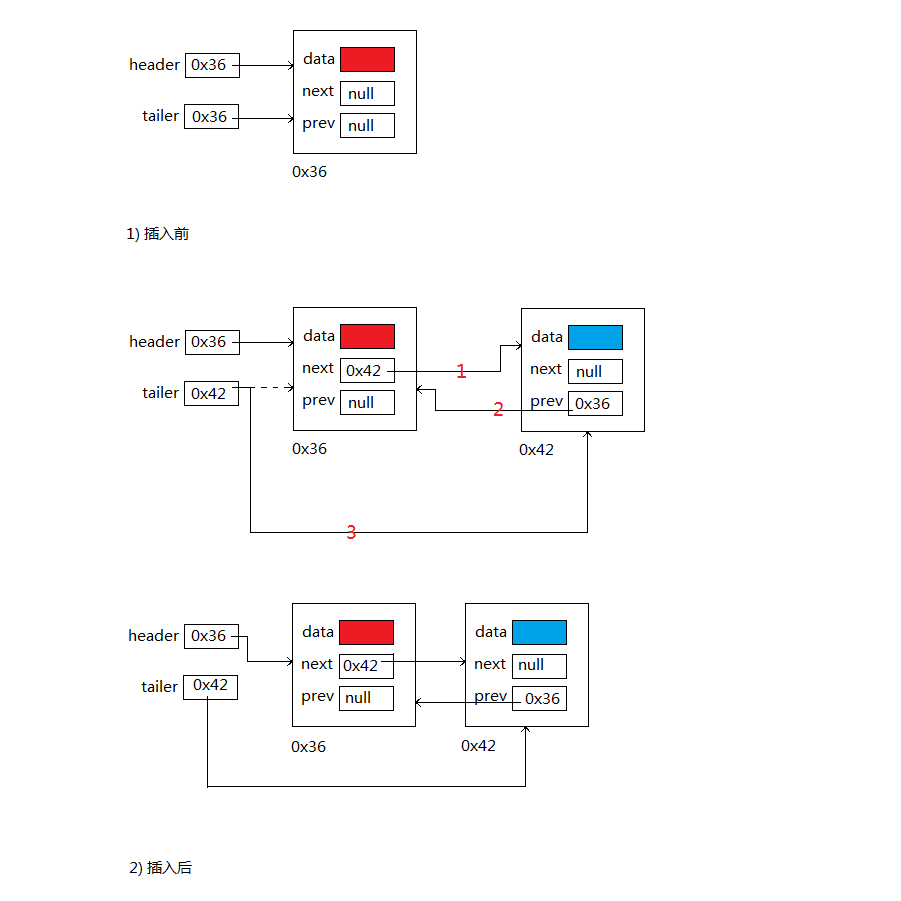
A: add(index, E)方法: 在此列表中指定的位置插入指定的元素。 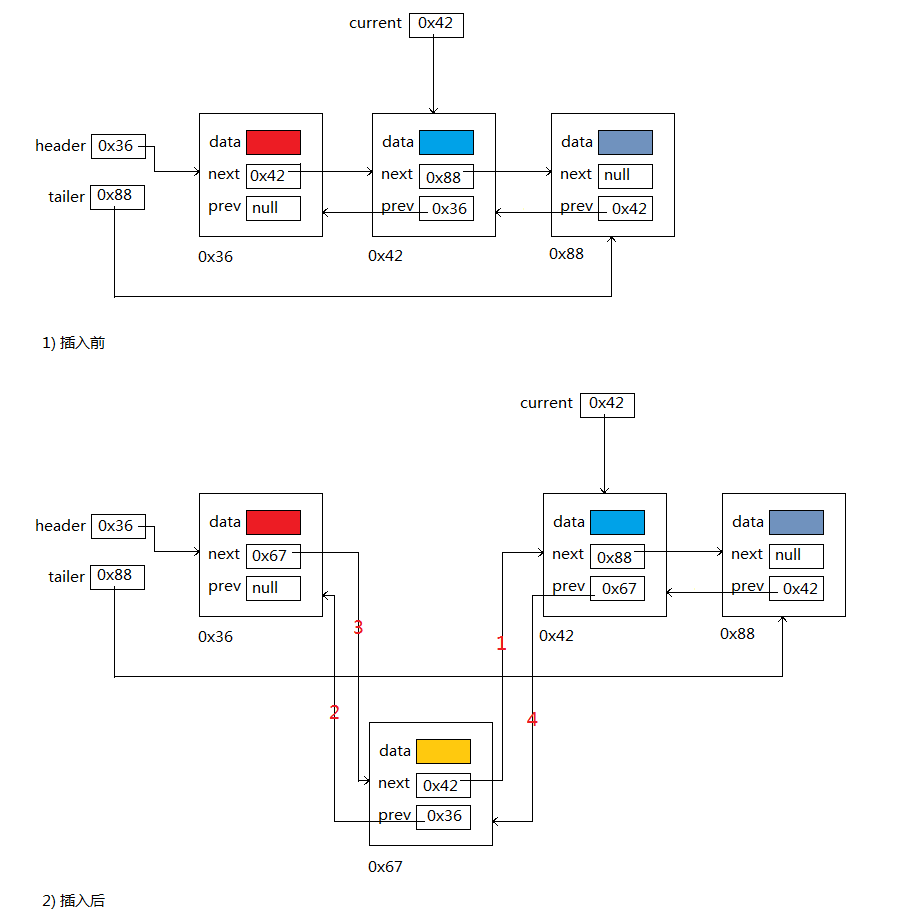
A: remove(Object o)方法: 從此列表中移除首次出現的指定元素(如果存在)。 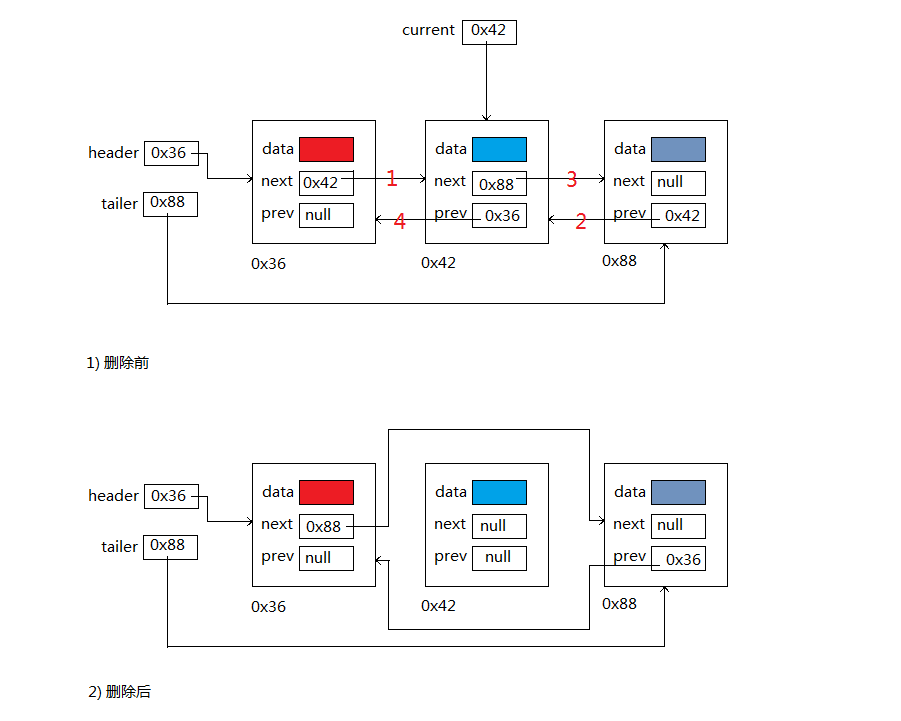
Q: 基於雙向鏈表的雙端隊列?
A: 雙向鏈表可以用來作為雙端隊列的基礎。在雙端隊列中,可以從任何一頭插入和刪除,雙向鏈表提供了這個能力。
Q: 為什麼要引入迭代器的概念?
A: ArrayList底層維護的是一個數組;LinkedList是鏈表結構的;HashSet依賴的是哈希表,每種容器都有自己特有的數據結構。因為容器的內部結構不同,很多時候可能不知道該怎樣去遍歷一個容器中的元素。所以為了使對容器內元素的操作更為簡單,Java引入了迭代器。
A: 把訪問邏輯從不同類型的集合類中抽取出來,從而避免向外部暴露集合的內部結構。
對於數組我們使用的是下標來進行處理的:
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
對於鏈表,我們從表頭開始遍歷:
public void displayForward() {
System.out.print("List (first-->last): [");
Entry<E> current = mHeader;
while(current != null) {
E e = current.mElement;
System.out.print(e);
if (current.mNext != null) {
System.out.print(" ");
}
current = current.mNext;
}
System.out.print("]\n");
}
A: 不同的集合會對應不同的遍歷方法,客戶端代碼無法復用。在實際應用中如何將上面兩個集合整合是相當麻煩的。所以才有Iterator,它總是用同一種邏輯來遍歷集合。使得客戶端自身不需要來維護集合的內部結構,所有的內部狀態都由Iterator來維護。客戶端不用直接和集合進行打交道,而是控制Iterator向它發送向前向後的指令,就可以遍歷集合。
A: 迭代器模式就是提供一種方法對一個容器對象中的各個元素進行訪問,而又不暴露該對象容器的內部細節。
Q: 迭代器定義的介面?
A: 迭代器包含對數據結構中數據項的引用,並且用來遍歷這些結構的對象。下麵是迭代器的介面定義:
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
public interface ListIterator<E> extends Iterator<E> {
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void set(E e);
}
A: 每個容器的iterator()方法返回一個標準的Iterator實現。一般而言,Java中迭代器和鏈表之前的連接是通過把迭代器設為鏈表的內部類來實現,而C++是"友元"來實現。
A: 如下圖顯示了指向鏈表的某個結點的兩個迭代器:
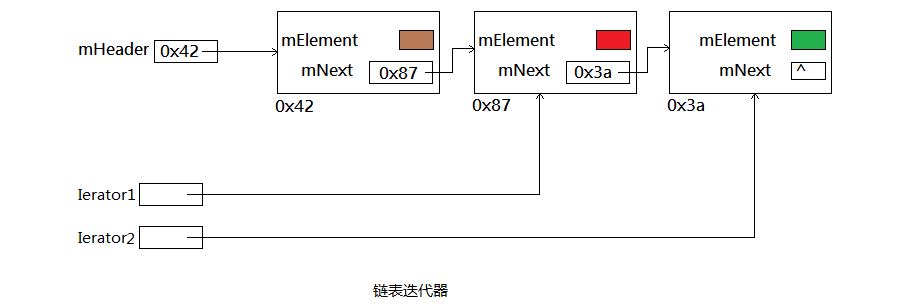
Q: JDK1.6的LinkedList的迭代器?
A: 迭代器類ListItr實現ListIterator介面,定義如下:
private class ListItr implements ListIterator<E> {
}
A: 示例:ListIteratorTestCase.java
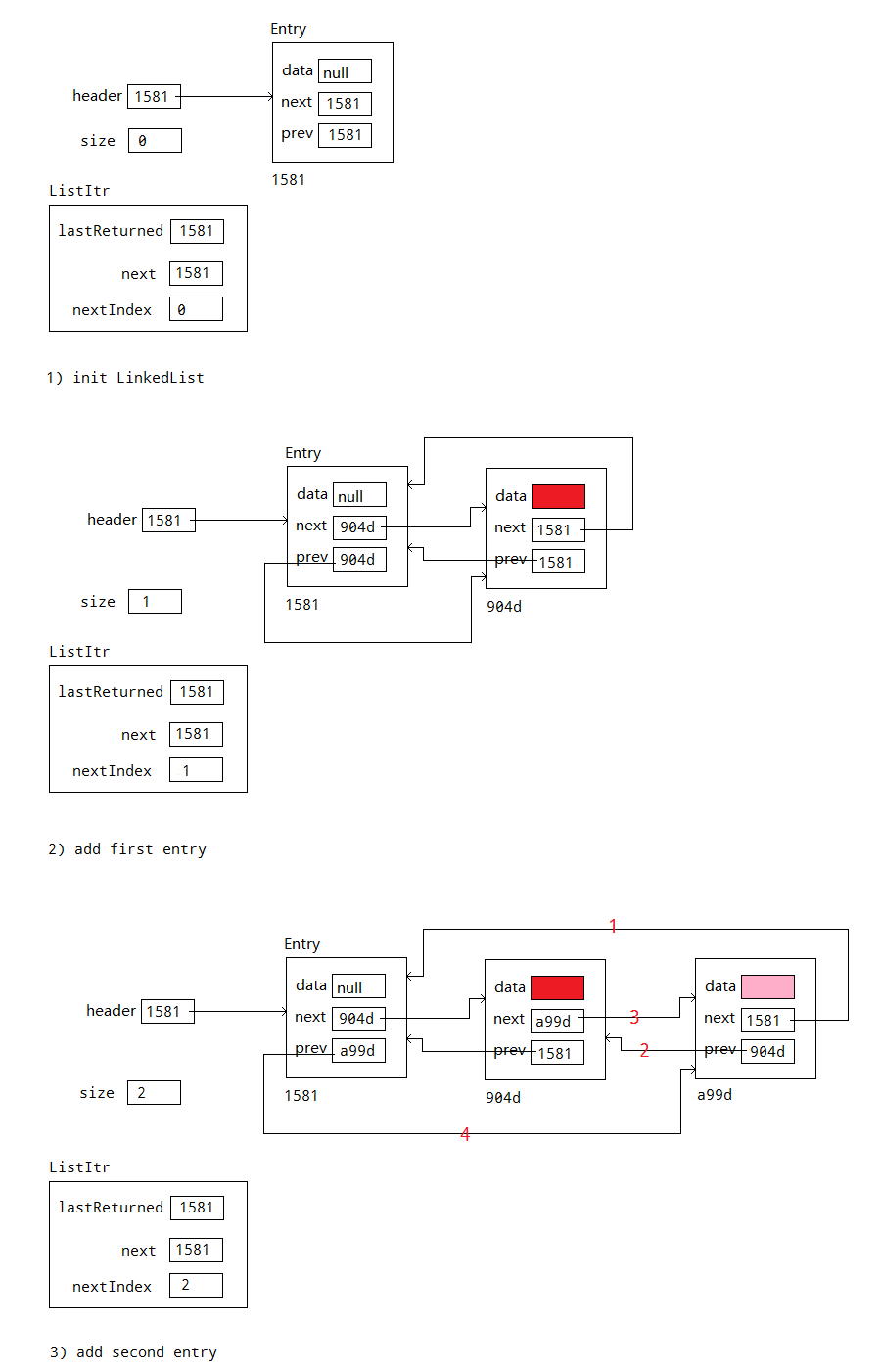
Q: 迭代器指向哪裡?
A: 迭代器類的一個設計問題是決定在不同的操作後,迭代器應該指向哪裡。而JDK1.6中LinkedList.ListItr中的add()實現,next指針一直指向表頭,這裡假設調用的是iterator(),不指定下標。
Q: 本篇小結
- 鏈表包含一個LinkedList對象和許多Entry對象。
- next欄位為null意味著鏈表的結尾。
- 在表頭插入結點需要把新結點的next欄位指向原來的第一個結點,然後把header指向新結點。
- 在表頭刪除結點要把header指向header.next。
- 為了遍歷鏈表,從header開始,然後從一個結點到下一個結點,方法是用每個結點的next欄位找到下一個結點。
- 通過遍歷鏈表可以找到擁有特定值的結點,一旦找到,可以顯示、刪除或用其他方式操縱該結點。
- 新結點可以插在某個特定值的結點的前面或後面,首先要遍歷找到這個結點。
- 雙端鏈表在鏈表中維護一個指向最後一個結點的引用,它通常和header一樣,叫做tailer。
- 雙端鏈表允許在表尾插入數據項。
- 抽象數據類型是一種數據存儲類,不涉及它的實現。
- 棧和隊列是ADT,它們既可以用數組實現,也可以用鏈表實現。
- 有序鏈表中,結點按照關鍵字升序或降序排列。
- 在有序鏈表中插入需要O(N) 的時間,因為必須要找到正確的插入點,最小值結點的刪除需要O(1)時間。
- 雙向鏈表中,每個結點包含對前一個結點的引用,同時有對後一個結點的引用。
- 雙向鏈表允許反向遍歷,並可以從表尾刪除。
- 迭代器是一個引用,它被封裝在類對象中,這個引用指向相關聯的鏈表中的結點。
- 迭代器方法允許使用者沿鏈表移動迭代器,並訪問當前所指的結點。
- 能用迭代器遍歷鏈表,在選定的結點上執行某些操作。

