
時間序列深度學習:狀態 LSTM 模型預測太陽黑子 本文翻譯自《Time Series Deep Learning: Forecasting Sunspots With Keras Stateful Lstm In R》 "原文鏈接" 由於數據科學機器學習和深度學習的發展,時間序列預測在預測準確性方 ...
時間序列深度學習:狀態 LSTM 模型預測太陽黑子
本文翻譯自《Time Series Deep Learning: Forecasting Sunspots With Keras Stateful Lstm In R》
由於數據科學機器學習和深度學習的發展,時間序列預測在預測準確性方面取得了顯著進展。隨著這些 ML/DL 工具的發展,企業和金融機構現在可以通過應用這些新技術來解決舊問題,從而更好地進行預測。在本文中,我們展示了使用稱為 LSTM(長短期記憶)的特殊類型深度學習模型,該模型對涉及自相關性的序列預測問題很有用。我們分析了一個名為“太陽黑子”的著名歷史數據集(太陽黑子是指太陽錶面形成黑點的太陽現象)。我們將展示如何使用 LSTM 模型預測未來 10 年的太陽黑子數量。
教程概覽
此代碼教程對應於 2018 年 4 月 19 日星期四向 SP Global 提供的 Time Series Deep Learning 演示文稿。可以下載補充本文的幻燈片。
這是一個涉及時間序列深度學習和其他複雜機器學習主題(如回測交叉驗證)的高級教程。如果想要瞭解 R 中的 Keras,請查看:Customer Analytics: Using Deep Learning With Keras To Predict Customer Churn。
本教程中,你將會學到:
- 用
keras包開發一個狀態 LSTM 模型,該 R 包將 R TensorFlow 作為後端。 - 將狀態 LSTM 模型應用到著名的太陽黑子數據集上。
- 藉助
rsample包在初始抽樣上滾動預測,實現時間序列的交叉檢驗。 - 藉助
ggplot2和cowplot可視化回測和預測結果。 - 通過自相關函數(Autocorrelation Function,ACF)圖評估時間序列數據是否適合應用 LSTM 模型。
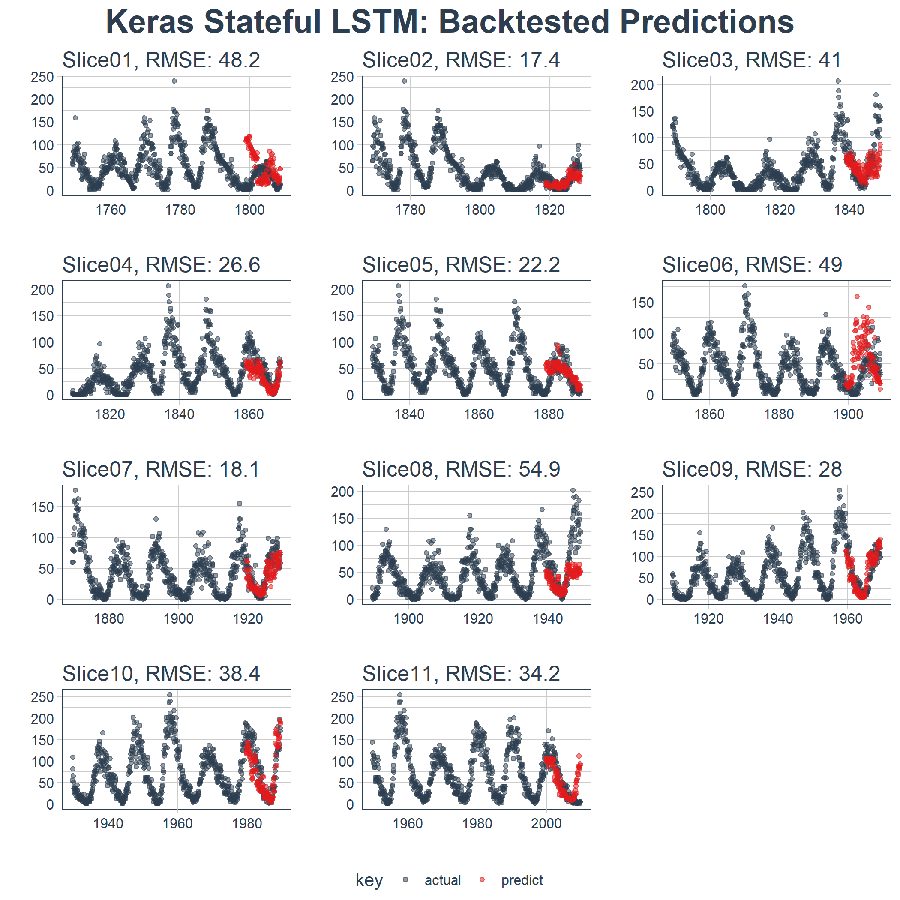
本文的最終結果是一個高性能的深度學習演算法,在預測未來 10 年太陽黑子數量方面表現非常出色!這是回測後狀態 LSTM 模型的結果。
商業應用
時間序列預測對營收和利潤有顯著影響。在商業方面,我們可能有興趣預測每月、每季度或每年的哪一天會發生大額支出,或者我們可能有興趣瞭解消費者物價指數(CPI)在未來六年個月如何變化。這些都是在微觀經濟和巨集觀經濟層面影響商業組織的常見問題。雖然本教程中使用的數據集不是“商業”數據集,但它顯示了工具-問題匹配的強大力量,意味著使用正確的工具進行工作可以大大提高準確性。最終的結果是預測準確性的提高將對營收和利潤帶來可量化的提升。
長短期記憶(LSTM)模型
長短期記憶(LSTM)模型是一種強大的遞歸神經網路(RNN)。博文《Understanding LSTM Networks》(翻譯版)以簡單易懂的方式解釋了模型的複雜性機制。下麵是描述 LSTM 內部單元架構的示意圖,除短期狀態之外,該架構使其能夠保持長期狀態,而這是傳統的 RNN 處理起來有困難的:
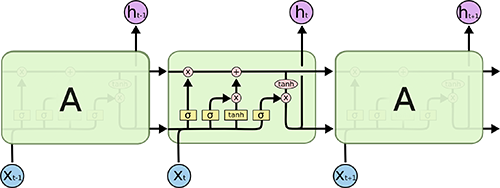
來源:Understanding LSTM Networks
LSTM 模型在預測具有自相關性(時間序列和滯後項之間存在相關性)的時間序列時非常有用,因為模型能夠保持狀態並識別時間序列上的模式。在每次處理過程中,遞歸架構能使狀態在更新權重時保持或者傳遞下去。此外,LSTM 模型的單元架構在短期持久化的基礎上實現了長期持久化,進而強化了 RNN,這一點非常吸引人!
在 Keras 中,LSTM 模型可以有“狀態”模式,Keras 文檔中這樣解釋:
索引 i 處每個樣本的最後狀態將被用作下一次批處理中索引 i 處樣本的初始狀態
在正常(或“無狀態”)模式下,Keras 對樣本重新洗牌,時間序列與其滯後項之間的依賴關係丟失。但是,在“狀態”模式下運行時,我們通常可以通過利用時間序列中存在的自相關性來獲得高質量的預測結果。
在完成本教程時,我們會進一步解釋。就目前而言,可以認為 LSTM 模型對涉及自相關性的時間序列問題可能非常有用,而且 Keras 有能力創建完美的時間序列建模工具——狀態 LSTM 模型。
太陽黑子數據集
太陽黑子是隨 R 發佈的著名數據集(參見 datasets 包)。數據集跟蹤記錄太陽黑子,即太陽錶面出現黑點的事件。這是來自 NASA 的一張照片,顯示了太陽黑子現象。相當酷!

來源:NASA
本教程所用的數據集稱為 sunspots.month,包含了 265(1749 ~ 2013)年間每月太陽黑子數量的月度數據。
構建 LSTM 模型預測太陽黑子
讓我們開動起來,預測太陽黑子。這是我們的目標:
目標:使用 LSTM 模型預測未來 10 年的太陽黑子數量。
1 若幹相關包
以下是本教程所需的包,所有這些包都可以在 CRAN 上找到。如果你尚未安裝這些包,可以使用 install.packages() 進行安裝。註意:在繼續使用此代碼教程之前,請確保更新所有包,因為這些包的先前版本可能與所用代碼不相容。
# Core Tidyverse
library(tidyverse)
library(glue)
library(forcats)
# Time Series
library(timetk)
library(tidyquant)
library(tibbletime)
# Visualization
library(cowplot)
# Preprocessing
library(recipes)
# Sampling / Accuracy
library(rsample)
library(yardstick)
# Modeling
library(keras)如果你之前沒有在 R 中運行過 Keras,你需要用 install_keras() 函數安裝 Keras。
# Install Keras if you have not installed before
install_keras()2 數據
數據集 sunspot.month 隨 R 一起發佈,可以輕易獲得。它是一個 ts 類對象(非 tidy 類),所以我們將使用 timetk 中的 tk_tbl() 函數轉換為 tidy 數據集。我們使用這個函數而不是來自 tibble 的 as.tibble(),用來自動將時間序列索引保存為zoo yearmon 索引。最後,我們將使用 lubridate::as_date()(使用 tidyquant 時載入)將 zoo 索引轉換為日期,然後轉換為 tbl_time 對象以使時間序列操作起來更容易。
sun_spots <- datasets::sunspot.month %>%
tk_tbl() %>%
mutate(index = as_date(index)) %>%
as_tbl_time(index = index)
sun_spots## # A time tibble: 3,177 x 2
## # Index: index
## index value
## <date> <dbl>
## 1 1749-01-01 58.0
## 2 1749-02-01 62.6
## 3 1749-03-01 70.0
## 4 1749-04-01 55.7
## 5 1749-05-01 85.0
## 6 1749-06-01 83.5
## 7 1749-07-01 94.8
## 8 1749-08-01 66.3
## 9 1749-09-01 75.9
## 10 1749-10-01 75.5
## # ... with 3,167 more rows3 探索性數據分析
時間序列很長(有 265 年!)。我們可以將時間序列的全部(265 年)以及前 50 年的數據可視化,以獲得該時間系列的直觀感受。
3.1 使用 COWPLOT 可視化太陽黑子數據
我們將創建若幹 ggplot 對象並藉助 cowplot::plot_grid() 把這些對象組合起來。對於需要縮放的部分,我們使用 tibbletime::time_filter(),可以方便的實現基於時間的過濾。
p1 <- sun_spots %>%
ggplot(aes(index, value)) +
geom_point(
color = palette_light()[[1]], alpha = 0.5) +
theme_tq() +
labs(title = "From 1749 to 2013 (Full Data Set)")
p2 <- sun_spots %>%
filter_time("start" ~ "1800") %>%
ggplot(aes(index, value)) +
geom_line(color = palette_light()[[1]], alpha = 0.5) +
geom_point(color = palette_light()[[1]]) +
geom_smooth(method = "loess", span = 0.2, se = FALSE) +
theme_tq() +
labs(
title = "1749 to 1800 (Zoomed In To Show Cycle)",
caption = "datasets::sunspot.month")
p_title <- ggdraw() +
draw_label(
"Sunspots",
size = 18,
fontface = "bold",
colour = palette_light()[[1]])
plot_grid(
p_title, p1, p2,
ncol = 1,
rel_heights = c(0.1, 1, 1))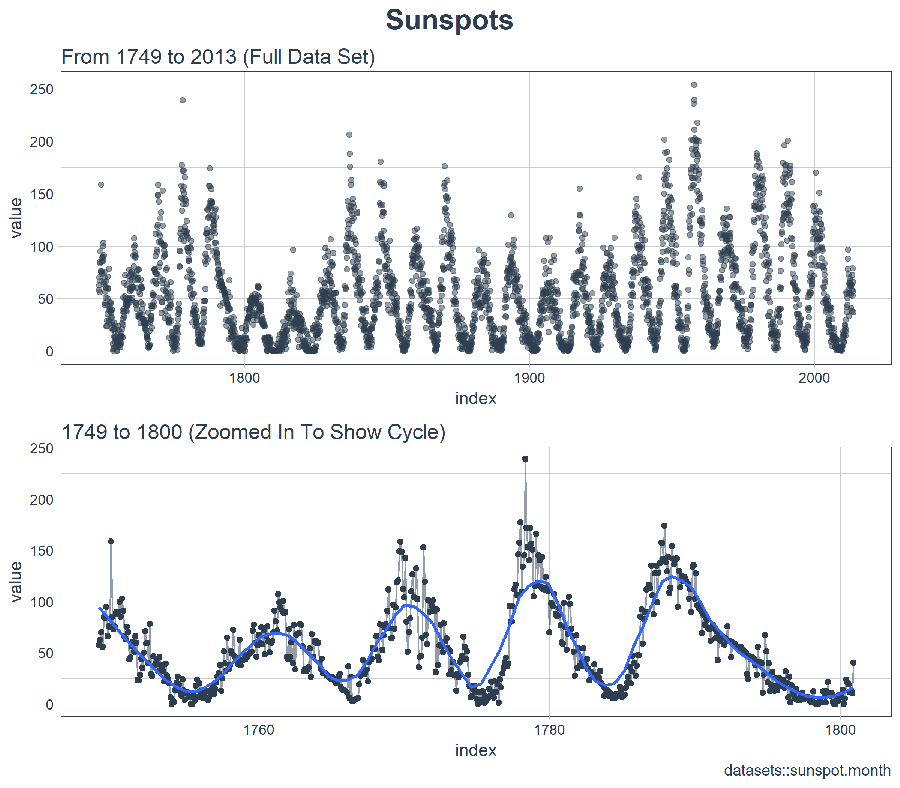
乍一看,這個時間序列應該很容易預測。但是,我們可以看到,周期(10 年)和振幅(太陽黑子的數量)似乎在 1780 年至 1800 年之間發生變化。這產生了一些挑戰。
3.2 計算 ACF
接下來我們要做的是確定 LSTM 模型是否是一個適用的好方法。LSTM 模型利用自相關性產生序列預測。我們的目標是使用批量預測(一種在整個預測區域內創建單一預測批次的技術,不同於在未來一個或多個步驟中迭代執行的單一預測)產生未來 10 年的預測。批量預測只有在自相關性持續 10 年以上時才有效。下麵,我們來檢查一下。
首先,我們需要回顧自相關函數(Autocorrelation Function,ACF),它表示時間序列與自身滯後項之間的相關性。stats 包庫中的 acf() 函數以曲線的形式返回每個滯後階數的 ACF 值。但是,我們希望將 ACF 值提取出來以便研究。為此,我們將創建一個自定義函數 tidy_acf(),以 tidy tibble 的形式返回 ACF 值。
tidy_acf <- function(data,
value,
lags = 0:20) {
value_expr <- enquo(value)
acf_values <- data %>%
pull(value) %>%
acf(lag.max = tail(lags, 1), plot = FALSE) %>%
.$acf %>%
.[,,1]
ret <- tibble(acf = acf_values) %>%
rowid_to_column(var = "lag") %>%
mutate(lag = lag - 1) %>%
filter(lag %in% lags)
return(ret)
}接下來,讓我們測試一下這個函數以確保它按預期工作。該函數使用我們的 tidy 時間序列,提取數值列,並以 tibble 的形式返回 ACF 值以及對應的滯後階數。我們有 601 個自相關係數(一個對應時間序列自身,剩下的對應 600 個滯後階數)。一切看起來不錯。
max_lag <- 12 * 50
sun_spots %>%
tidy_acf(value, lags = 0:max_lag)## # A tibble: 601 x 2
## lag acf
## <dbl> <dbl>
## 1 0. 1.00
## 2 1. 0.923
## 3 2. 0.893
## 4 3. 0.878
## 5 4. 0.867
## 6 5. 0.853
## 7 6. 0.840
## 8 7. 0.822
## 9 8. 0.809
## 10 9. 0.799
## # ... with 591 more rows下麵藉助 ggplot2 包把 ACF 數據可視化,以便確定 10 年後是否存在高自相關滯後項。
sun_spots %>%
tidy_acf(value, lags = 0:max_lag) %>%
ggplot(aes(lag, acf)) +
geom_segment(
aes(xend = lag, yend = 0),
color = palette_light()[[1]]) +
geom_vline(
xintercept = 120, size = 3,
color = palette_light()[[2]]) +
annotate(
"text", label = "10 Year Mark",
x = 130, y = 0.8,
color = palette_light()[[2]],
size = 6, hjust = 0) +
theme_tq() +
labs(title = "ACF: Sunspots")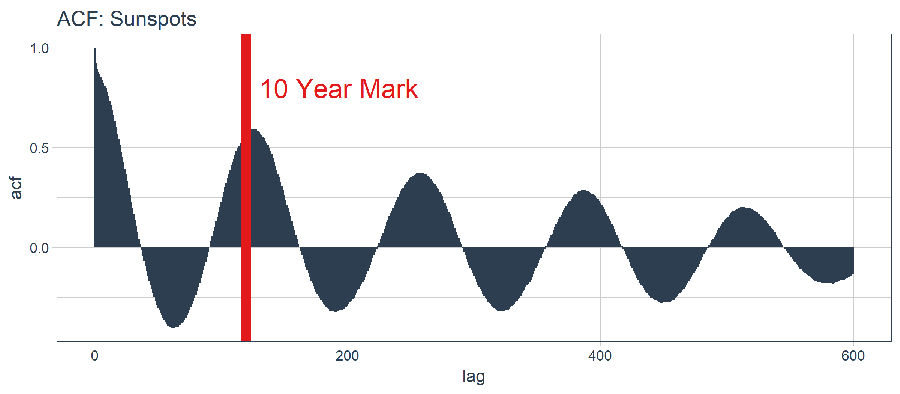
好消息。自相關係數在 120 階(10年標誌)之後依然超過 0.5。理論上,我們可以使用高自相關滯後項來開發 LSTM 模型。
sun_spots %>%
tidy_acf(value, lags = 115:135) %>%
ggplot(aes(lag, acf)) +
geom_vline(
xintercept = 120, size = 3,
color = palette_light()[[2]]) +
geom_segment(
aes(xend = lag, yend = 0),
color = palette_light()[[1]]) +
geom_point(
color = palette_light()[[1]],
size = 2) +
geom_label(
aes(label = acf %>% round(2)),
vjust = -1,
color = palette_light()[[1]]) +
annotate(
"text", label = "10 Year Mark",
x = 121, y = 0.8,
color = palette_light()[[2]],
size = 5, hjust = 0) +
theme_tq() +
labs(
title = "ACF: Sunspots",
subtitle = "Zoomed in on Lags 115 to 135")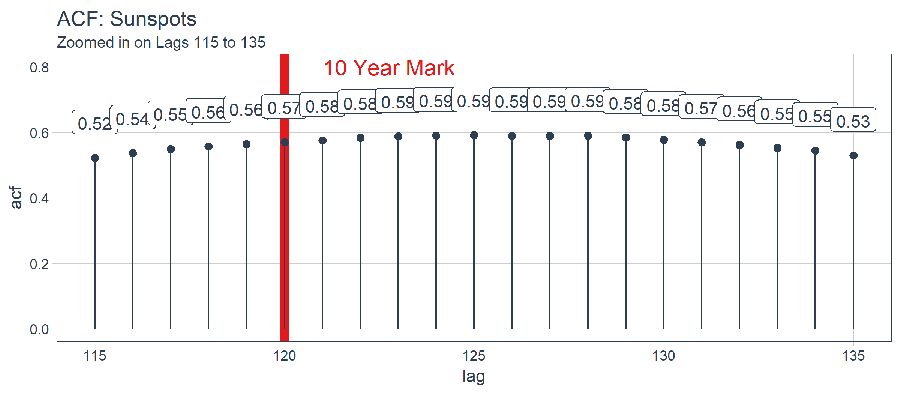
經過檢查,最優滯後階數位於在 125 階。這不一定是我們將使用的,因為我們要更多地考慮使用 Keras 實現的 LSTM 模型進行批量預測。有了這個觀點,以下是如何 filter() 獲得最優滯後階數。
optimal_lag_setting <- sun_spots %>%
tidy_acf(value, lags = 115:135) %>%
filter(acf == max(acf)) %>%
pull(lag)
optimal_lag_setting## [1] 1254 回測:時間序列交叉驗證
交叉驗證是在子樣本數據上針對驗證集數據開發模型的過程,其目標是確定預期的準確度級別和誤差範圍。在交叉驗證方面,時間序列與非序列數據有點不同。具體而言,在制定抽樣計劃時,必須保留對以前時間樣本的時間依賴性。我們可以通過平移視窗的方式選擇連續子樣本,進而創建交叉驗證抽樣計劃。在金融領域,這種類型的分析通常被稱為“回測”,它需要在一個時間序列上平移若幹視窗來分割成多個不間斷的序列,以在當前和過去的觀測上測試策略。
最近的一個發展是 rsample 包,它使交叉驗證抽樣計劃非常易於實施。此外,rsample 包還包含回測功能。“Time Series Analysis Example”描述了一個使用 rolling_origin() 函數為時間序列交叉驗證創建樣本的過程。我們將使用這種方法。
4.1 開發一個回測策略
我們創建的抽樣計劃使用 50 年(initial = 12 x 50)的數據作為訓練集,10 年(assess = 12 x 10)的數據用於測試(驗證)集。我們選擇 20 年的跳躍跨度(skip = 12 x 20),將樣本均勻分佈到 11 組中,跨越整個 265 年的太陽黑子歷史。最後,我們選擇 cumulative = FALSE 來允許平移起始點,這確保了較近期數據上的模型相較那些不太新近的數據沒有不公平的優勢(使用更多的觀測數據)。rolling_origin_resamples 是一個 tibble 型的返回值。
periods_train <- 12 * 50
periods_test <- 12 * 10
skip_span <- 12 * 20
rolling_origin_resamples <- rolling_origin(
sun_spots,
initial = periods_train,
assess = periods_test,
cumulative = FALSE,
skip = skip_span)
rolling_origin_resamples## # Rolling origin forecast resampling
## # A tibble: 11 x 2
## splits id
## <list> <chr>
## 1 <S3: rsplit> Slice01
## 2 <S3: rsplit> Slice02
## 3 <S3: rsplit> Slice03
## 4 <S3: rsplit> Slice04
## 5 <S3: rsplit> Slice05
## 6 <S3: rsplit> Slice06
## 7 <S3: rsplit> Slice07
## 8 <S3: rsplit> Slice08
## 9 <S3: rsplit> Slice09
## 10 <S3: rsplit> Slice10
## 11 <S3: rsplit> Slice114.2 可視化回測策略
我們可以用兩個自定義函數來可視化再抽樣。首先是 plot_split(),使用 ggplot2 繪製一個再抽樣分割圖。請註意,expand_y_axis 參數預設將日期範圍擴展成整個 sun_spots 數據集的日期範圍。當我們將所有的圖形同時可視化時,這將變得有用。
# Plotting function for a single split
plot_split <- function(split,
expand_y_axis = TRUE,
alpha = 1,
size = 1,
base_size = 14) {
# Manipulate data
train_tbl <- training(split) %>%
add_column(key = "training")
test_tbl <- testing(split) %>%
add_column(key = "testing")
data_manipulated <- bind_rows(
train_tbl, test_tbl) %>%
as_tbl_time(index = index) %>%
mutate(
key = fct_relevel(
key, "training", "testing"))
# Collect attributes
train_time_summary <- train_tbl %>%
tk_index() %>%
tk_get_timeseries_summary()
test_time_summary <- test_tbl %>%
tk_index() %>%
tk_get_timeseries_summary()
# Visualize
g <- data_manipulated %>%
ggplot(
aes(x = index,
y = value,
color = key)) +
geom_line(size = size, alpha = alpha) +
theme_tq(base_size = base_size) +
scale_color_tq() +
labs(
title = glue("Split: {split$id}"),
subtitle = glue(
"{train_time_summary$start} to {test_time_summary$end}"),
y = "", x = "") +
theme(legend.position = "none")
if (expand_y_axis) {
sun_spots_time_summary <- sun_spots %>%
tk_index() %>%
tk_get_timeseries_summary()
g <- g +
scale_x_date(
limits = c(
sun_spots_time_summary$start,
sun_spots_time_summary$end))
}
return(g)
}plot_split() 函數接受一個分割(在本例中為 Slice01),並可視化抽樣策略。我們使用 expand_y_axis = TRUE 將橫坐標範圍擴展到整個數據集的日期範圍。
rolling_origin_resamples$splits[[1]] %>%
plot_split(expand_y_axis = TRUE) +
theme(legend.position = "bottom")
第二個函數是 plot_sampling_plan(),使用 purrr 和 cowplot 將 plot_split() 函數應用到所有樣本上。
# Plotting function that scales to all splits
plot_sampling_plan <- function(sampling_tbl,
expand_y_axis = TRUE,
ncol = 3,
alpha = 1,
size = 1,
base_size = 14,
title = "Sampling Plan") {
# Map plot_split() to sampling_tbl
sampling_tbl_with_plots <- sampling_tbl %>%
mutate(
gg_plots = map(
splits, plot_split,
expand_y_axis = expand_y_axis,
alpha = alpha,
base_size = base_size))
# Make plots with cowplot
plot_list <- sampling_tbl_with_plots$gg_plots
p_temp <- plot_list[[1]] + theme(legend.position = "bottom")
legend <- get_legend(p_temp)
p_body <- plot_grid(
plotlist = plot_list, ncol = ncol)
p_title <- ggdraw() +
draw_label(
title,
size = 18,
fontface = "bold",
colour = palette_light()[[1]])
g <- plot_grid(
p_title,
p_body,
legend,
ncol = 1,
rel_heights = c(0.05, 1, 0.05))
return(g)
}現在我們可以使用 plot_sampling_plan() 可視化整個回測策略!我們可以看到抽樣計劃如何平移抽樣視窗逐漸切分出訓練和測試子樣本。
rolling_origin_resamples %>%
plot_sampling_plan(
expand_y_axis = T,
ncol = 3, alpha = 1,
size = 1, base_size = 10,
title = "Backtesting Strategy: Rolling Origin Sampling Plan")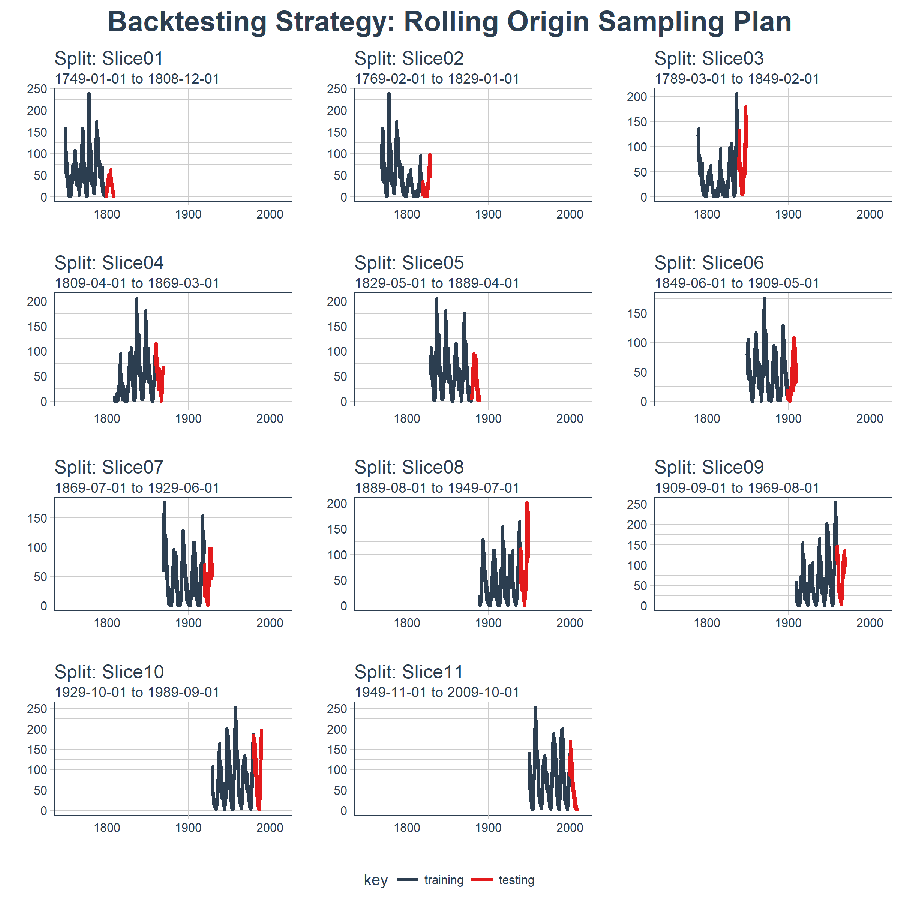
此外,我們可以讓 expand_y_axis = FALSE,對每個樣本進行縮放。
rolling_origin_resamples %>%
plot_sampling_plan(
expand_y_axis = F,
ncol = 3, alpha = 1,
size = 1, base_size = 10,
title = "Backtesting Strategy: Zoomed In")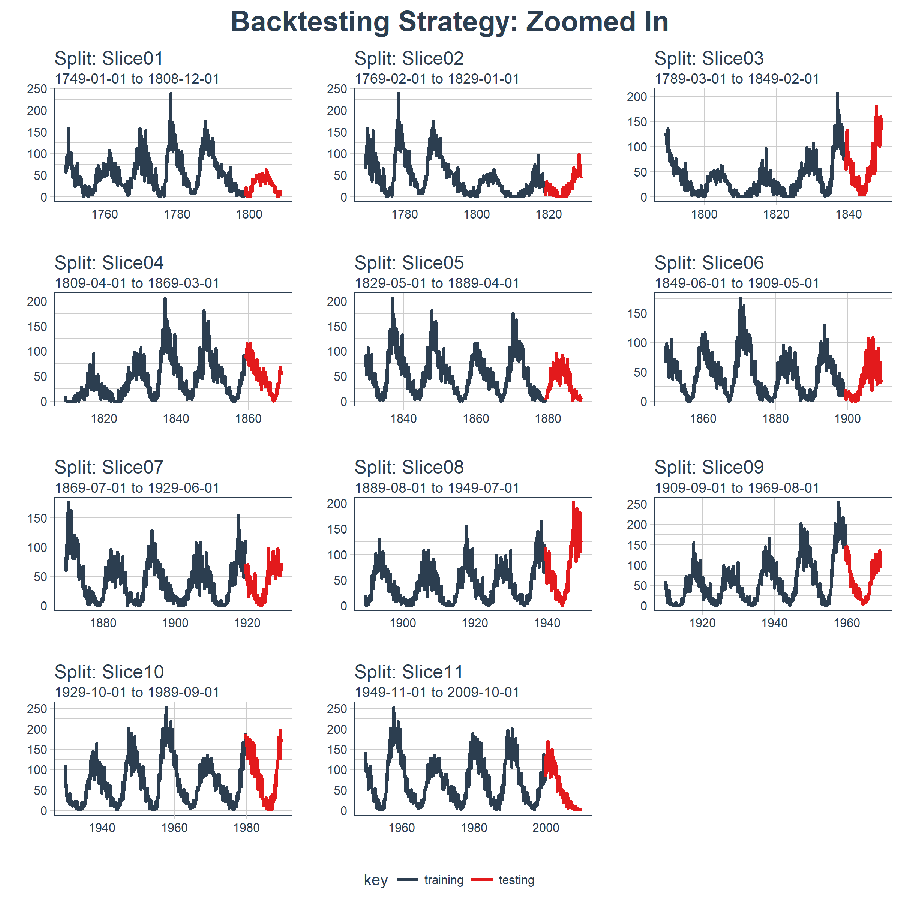
當在太陽黑子數據集上測試 LSTM 模型準確性時,我們將使用這種回測策略(來自一個時間序列的 11 個樣本,每個時間序列分為 50/10 兩部分,並且樣本之間有 20 年的偏移)。
5 用 Keras 構建狀態 LSTM 模型
首先,我們將在回測策略的某個樣本上用 Keras 開發一個狀態 LSTM 模型。然後,我們將模型套用到所有樣本,以測試和驗證模型性能。
5.1 單個 LSTM 模型
對單個 LSTM 模型,我們選擇並可視化最近一期的分割樣本(Slice11),這一樣本包含了最新的數據。
split <- rolling_origin_resamples$splits[[11]]
split_id <- rolling_origin_resamples$id[[11]]5.1.1 可視化該分割樣本
我麽可以用 plot_split() 函數可視化該分割,設定 expand_y_axis = FALSE 以便將橫坐標縮放到樣本本身的範圍。
plot_split(
split,
expand_y_axis = FALSE,
size = 0.5) +
theme(legend.position = "bottom") +
ggtitle(glue("Split: {split_id}"))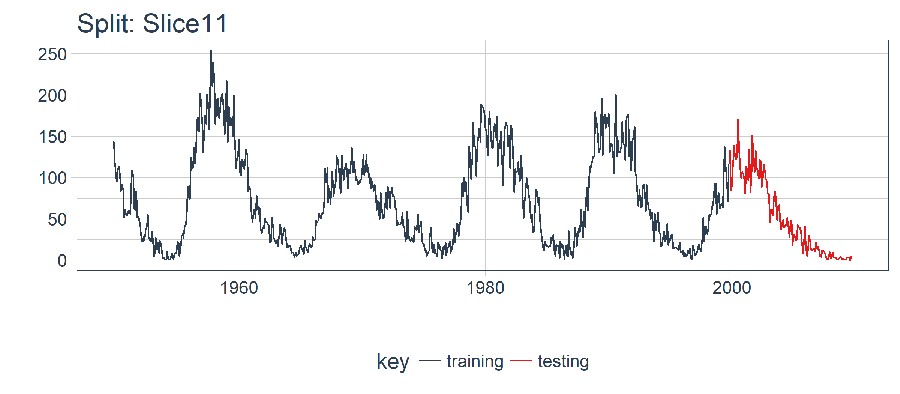
5.1.2 數據準備
首先,我們將訓練和測試數據集合成一個數據集,並使用列 key 來標記它們來自哪個集合(training 或 testing)。請註意,tbl_time 對象需要在調用 bind_rows() 時重新指定索引,但是這個問題應該很快在 dplyr 包中得到糾正。
df_trn <- training(split)
df_tst <- testing(split)
df <- bind_rows(
df_trn %>% add_column(key = "training"),
df_tst %>% add_column(key = "testing")) %>%
as_tbl_time(index = index)
df## # A time tibble: 720 x 3
## # Index: index
## index value key
## <date> <dbl> <chr>
## 1 1949-11-01 144. training
## 2 1949-12-01 118. training
## 3 1950-01-01 102. training
## 4 1950-02-01 94.8 training
## 5 1950-03-01 110. training
## 6 1950-04-01 113. training
## 7 1950-05-01 106. training
## 8 1950-06-01 83.6 training
## 9 1950-07-01 91.0 training
## 10 1950-08-01 85.2 training
## # ... with 710 more rows5.1.3 用 recipe 做數據預處理
LSTM 演算法要求輸入數據經過中心化並標度化。我們可以使用 recipe 包預處理數據。我們用 step_sqrt 來轉換數據以減少異常值的影響,再結合 step_center 和 step_scale 對數據進行中心化和標度化。最後,數據使用 bake() 函數實現處理轉換。
rec_obj <- recipe(value ~ ., df) %>%
step_sqrt(value) %>%
step_center(value) %>%
step_scale(value) %>%
prep()
df_processed_tbl <- bake(rec_obj, df)
df_processed_tbl## # A tibble: 720 x 3
## index value key
## <date> <dbl> <fct>
## 1 1949-11-01 1.25 training
## 2 1949-12-01 0.929 training
## 3 1950-01-01 0.714 training
## 4 1950-02-01 0.617 training
## 5 1950-03-01 0.825 training
## 6 1950-04-01 0.874 training
## 7 1950-05-01 0.777 training
## 8 1950-06-01 0.450 training
## 9 1950-07-01 0.561 training
## 10 1950-08-01 0.474 training
## # ... with 710 more rows接著,記錄中心化和標度化的信息,以便在建模完成之後可以將數據逆向轉換回去。平方根轉換可以通過乘方運算逆轉回去,但要在逆轉中心化和標度化之後。
center_history <- rec_obj$steps[[2]]$means["value"]
scale_history <- rec_obj$steps[[3]]$sds["value"]
c("center" = center_history, "scale" = scale_history)## center.value scale.value
## 7.549526 3.5455615.1.4 規劃 LSTM 模型
我們需要規划下如何構建 LSTM 模型。首先,瞭解幾個 LSTM 模型的專業術語:
張量格式(Tensor Format):
- 預測變數(X)必須是一個 3 維數組,維度分別是:
samples、timesteps和features。第一維代表變數的長度;第二維是時間步(滯後階數);第三維是預測變數的個數(1 表示單變數,n 表示多變數) - 輸出或目標變數(y)必須是一個 2 維數組,維度分別是:
samples和timesteps。第一維代表變數的長度;第二維是時間步(之後階數)
訓練與測試:
- 訓練與測試的長度必須是可分的(訓練集長度除以測試集長度必須是一個整數)
批量大小(Batch Size):
- 批量大小是在 RNN 權重更新之前一次前向 / 後向傳播過程中訓練樣本的數量
- 批量大小關於訓練集和測試集長度必須是可分的(訓練集長度除以批量大小,以及測試集長度除以批量大小必須是一個整數)
時間步(Time Steps):
- 時間步是訓練集與測試集中的滯後階數
- 我們的例子中滯後 1 階
周期(Epochs):
- 周期是前向 / 後向傳播迭代的總次數
- 通常情況下周期越多,模型表現越好,直到驗證集上的精確度或損失不再增加,這時便出現過度擬合
考慮到這一點,我們可以提出一個計劃。我們將預測視窗或測試集的長度定在 120 個月(10年)。最優相關性發生在 125 階,但這並不能被預測範圍整除。我們可以增加預測範圍,但是這僅提供了自相關性的最小幅度增加。我們選擇批量大小為 40,它可以整除測試集和訓練集的觀察個數。我們選擇時間步等於 1,這是因為我們只使用 1 階滯後(只向前預測一步)。最後,我們設置 epochs = 300,但這需要調整以平衡偏差與方差。
# Model inputs
lag_setting <- 120 # = nrow(df_tst)
batch_size <- 40
train_length <- 440
tsteps <- 1
epochs <- 3005.1.5 2 維與 3 維的訓練、測試數組
下麵將訓練集和測試集數據轉換成合適的形式(數組)。記住,LSTM 模型要求預測變數(X)是 3 維的,輸出或目標變數(y)是 2 維的。
# Training Set
lag_train_tbl <- df_processed_tbl %>%
mutate(value_lag = lag(value, n = lag_setting)) %>%
filter(!is.na(value_lag)) %>%
filter(key == "training") %>%
tail(train_length)
x_train_vec <- lag_train_tbl$value_lag
x_train_arr <- array(
data = x_train_vec, dim = c(length(x_train_vec), 1, 1))
y_train_vec <- lag_train_tbl$value
y_train_arr <- array(
data = y_train_vec, dim = c(length(y_train_vec), 1))
# Testing Set
lag_test_tbl <- df_processed_tbl %>%
mutate(
value_lag = lag(
value, n = lag_setting)) %>%
filter(!is.na(value_lag)) %>%
filter(key == "testing")
x_test_vec <- lag_test_tbl$value_lag
x_test_arr <- array(
data = x_test_vec,
dim = c(length(x_test_vec), 1, 1))
y_test_vec <- lag_test_tbl$value
y_test_arr <- array(
data = y_test_vec,
dim = c(length(y_test_vec), 1))5.1.6 構建 LSTM 模型
我們可以使用 keras_model_sequential() 構建 LSTM 模型,並像堆磚塊一樣堆疊神經網路層。我們將使用兩個 LSTM 層,每層都設定 units = 50。第一個 LSTM 層接收所需的輸入形狀,即[時間步,特征數量]。批量大小就是我們的批量大小。我們將第一層設置為 return_sequences = TRUE 和 stateful = TRUE。第二層和前面相同,除了 batch_size(batch_size 只需要在第一層中指定),另外 return_sequences = FALSE 不返回時間戳維度(從第一個 LSTM 層返回 2 維數組,而不是 3 維)。我們使用 layer_dense(units = 1),這是 Keras 序列模型的標準結尾。最後,我們在 compile() 中使用 loss ="mae" 以及流行的 optimizer = "adam"。
model <- keras_model_sequential()
model %>%
layer_lstm(
units = 50,
input_shape = c(tsteps, 1),
batch_size = batch_size,
return_sequences = TRUE,
stateful = TRUE) %>%
layer_lstm(
units = 50,
return_sequences = FALSE,
stateful = TRUE) %>%
layer_dense(units = 1)
model %>%
compile(loss = 'mae', optimizer = 'adam')
model## Model
## ______________________________________________________________________
## Layer (type) Output Shape Param #
## ======================================================================
## lstm_1 (LSTM) (40, 1, 50) 10400
## ______________________________________________________________________
## lstm_2 (LSTM) (40, 50) 20200
## ______________________________________________________________________
## dense_1 (Dense) (40, 1) 51
## ======================================================================
## Total params: 30,651
## Trainable params: 30,651
## Non-trainable params: 0
## ______________________________________________________________________5.1.7 擬合 LSTM 模型
下一步,我們使用一個 for 迴圈擬合狀態 LSTM 模型(需要手動重置狀態)。有 300 個周期要迴圈,運行需要一點時間。我們設置 shuffle = FALSE 來保存序列,並且我們使用 reset_states() 在每個迴圈後手動重置狀態。
for (i in 1:epochs) {
model %>%
fit(x = x_train_arr,
y = y_train_arr,
batch_size = batch_size,
epochs = 1,
verbose = 1,
shuffle = FALSE)
model %>% reset_states()
cat("Epoch: ", i)
}5.1.8 使用 LSTM 模型預測
然後,我們可以使用 predict() 函數對測試集 x_test_arr 進行預測。我們可以使用之前保存的 scale_history 和 center_history 轉換得到的預測,然後對結果進行平方。最後,我們使用 reduce() 和自定義的 time_bind_rows() 函數將預測與一列原始數據結合起來。
# Make Predictions
pred_out <- model %>%
predict(x_test_arr, batch_size = batch_size) %>%
.[,1]
# Retransform values
pred_tbl <- tibble(
index = lag_test_tbl$index,
value = (pred_out * scale_history + center_history)^2)
# Combine actual data with predictions
tbl_1 <- df_trn %>%
add_column(key = "actual")
tbl_2 <- df_tst %>%
add_column(key = "actual")
tbl_3 <- pred_tbl %>%
add_column(key = "predict")
# Create time_bind_rows() to solve dplyr issue
time_bind_rows <- function(data_1,
data_2, index) {
index_expr <- enquo(index)
bind_rows(data_1, data_2) %>%
as_tbl_time(index = !! index_expr)
}
ret <- list(tbl_1, tbl_2, tbl_3) %>%
reduce(time_bind_rows, index = index) %>%
arrange(key, index) %>%
mutate(key = as_factor(key))
ret## # A time tibble: 840 x 3
## # Index: index
## index value key
## <date> <dbl> <fct>
## 1 1949-11-01 144. actual
## 2 1949-12-01 118. actual
## 3 1950-01-01 102. actual
## 4 1950-02-01 94.8 actual
## 5 1950-03-01 110. actual
## 6 1950-04-01 113. actual
## 7 1950-05-01 106. actual
## 8 1950-06-01 83.6 actual
## 9 1950-07-01 91.0 actual
## 10 1950-08-01 85.2 actual
## # ... with 830 more rows5.1.9 評估單個分割樣本上 LSTM 模型的表現
我們使用 yardstick 包里的 rmse() 函數評估表現,rmse() 返回均方誤差平方根(RMSE)。我們的數據以“長”格式的形式存在(使用 ggplot2 可視化的最佳格式),所以需要創建一個包裝器函數 calc_rmse() 對數據做預處理,以適應 yardstick::rmse() 的要求。
calc_rmse <- function(prediction_tbl) {
rmse_calculation <- function(data) {
data %>%
spread(key = key, value = value) %>%
select(-index) %>%
filter(!is.na(predict)) %>%
rename(
truth = actual,
estimate = predict) %>%
rmse(truth, estimate)
}
safe_rmse <- possibly(
rmse_calculation, otherwise = NA)
safe_rmse(prediction_tbl)
}我們計算模型的 RMSE。
calc_rmse(ret)## [1] 31.81798RMSE 提供的信息有限,我們需要可視化。註意:當我們擴展到回測策略中的所有樣本時,RMSE 將在確定預期誤差時派上用場。
5.1.10 可視化一步預測
下一步,我們創建一個繪圖函數——plot_prediction(),藉助 ggplot2 可視化單一樣本上的結果。
# Setup single plot function
plot_prediction <- function(data,
id,
alpha = 1,
size = 2,
base_size = 14) {
rmse_val <- calc_rmse(data)
g <- data %>%
ggplot(aes(index, value, color = key)) +
geom_point(alpha = alpha, size = size) +
theme_tq(base_size = base_size) +
scale_color_tq() +
theme(legend.position = "none") +
labs(
title = glue(
"{id}, RMSE: {round(rmse_val, digits = 1)}"),
x = "", y = "")
return(g)
}我們設置 id = split_id,在 Slice11 上測試函數。
ret %>%
plot_prediction(id = split_id, alpha = 0.65) +
theme(legend.position = "bottom")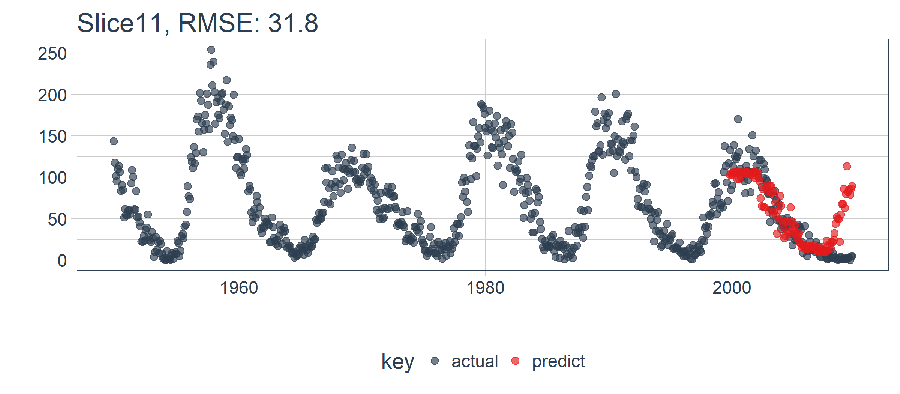
LSTM 模型表現相對較好! 我們選擇的設置似乎產生了一個不錯的模型,可以捕捉到數據中的趨勢。預測在下一個上升趨勢前搶跑了,但總體上好過了我的預期。現在,我們需要通過回測來查看隨著時間推移的真實表現!
5.2 在 11 個樣本上回測 LSTM 模型
一旦我們有了能在一個樣本上工作的 LSTM 模型,擴展到全部 11 個樣本上就相對簡單。我們只需創建一個預測函數,再套用到 rolling_origin_resamples 中抽樣計劃包含的數據上。
5.2.1 構建一個 LSTM 預測函數
這一步看起來很嚇人,但實際上很簡單。我們將 5.1 節的代碼複製到一個函數中。我們將它作為一個安全函數,對於任何長時間運行的函數來說,這是一個很好的做法,可以防止單個故障停止整個過程。
predict_keras_lstm <- function(split,
epochs = 300,
...) {
lstm_prediction <- function(split,
epochs,
...) {
# 5.1.2 Data Setup
df_trn <- training(split)
df_tst <- testing(split)
df <- bind_rows(
df_trn %>% add_column(key = "training"),
df_tst %>% add_column(key = "testing")) %>%
as_tbl_time(index = index)
# 5.1.3 Preprocessing
rec_obj <- recipe(value ~ ., df) %>%
step_sqrt(value) %>%
step_center(value) %>%
step_scale(value) %>%
prep()
df_processed_tbl <- bake(rec_obj, df)
center_history <- rec_obj$steps[[2]]$means["value"]
scale_history <- rec_obj$steps[[3]]$sds["value"]
# 5.1.4 LSTM Plan
lag_setting <- 120 # = nrow(df_tst)
batch_size <- 40
train_length <- 440
tsteps <- 1
epochs <- epochs
# 5.1.5 Train/Test Setup
lag_train_tbl <- df_processed_tbl %>%
mutate(
value_lag = lag(value, n = lag_setting)) %>%
filter(!is.na(value_lag)) %>%
filter(key == "training") %>%
tail(train_length)
x_train_vec <- lag_train_tbl$value_lag
x_train_arr <- array(


