
https://www.cnblogs.com/asker009/p/9126354.html 最近要搭建一個Hadoop做實驗,因為版本的問題遇到不少的坑,本文記錄VM上搭建的CentOS7.0+Hadoop3.1偽分散式的整個過程。 CentOS7.0安裝這裡不贅述。 Hadoop下載3.1。 ...
https://www.cnblogs.com/asker009/p/9126354.html
最近要搭建一個Hadoop做實驗,因為版本的問題遇到不少的坑,本文記錄VM上搭建的CentOS7.0+Hadoop3.1偽分散式的整個過程。
CentOS7.0安裝這裡不贅述。
Hadoop下載3.1。
JDK需要安裝1.8。
一、VM
網路採用NAT模式,畢竟後續搭建分散式方便。
取消DHCP,NAT里的dns設置成虛擬的網關IP(192.168.31.2,可以加上外網的解析地址114.114.114.114)
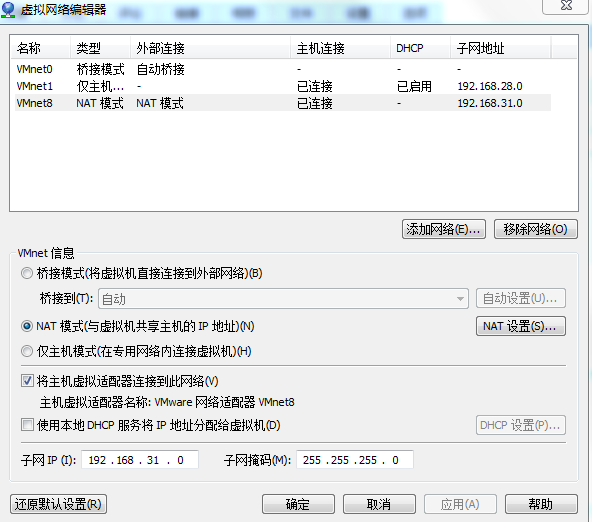
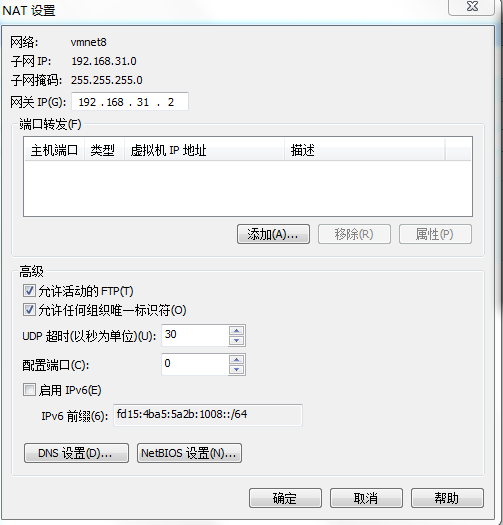
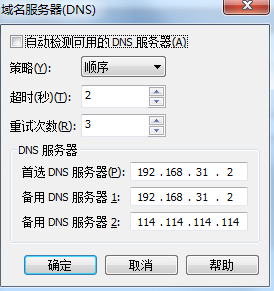
二、IP設置
使用NAT模式設置IP
預設宿主機ip192.168.31.1 #不同的PC,這裡的IP不一樣,但是宿主機一般都是.1,網關機(虛擬機的)一般都是.2
宿主機的虛擬網卡VMnet8有時候IP會出問題,建議手工設置IP:192.168.31.1
預設虛擬機網關192.168.31.2 ,虛擬機自動虛擬出來的。
虛擬機ip手動設置為192.168.31.10 #這裡隨意設置,不要和宿主機和網關相同就可以,確保在一個網段。
以上IP和原本宿主機的區域網IP不在一個網段。

linux的IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#註意這裡,不同的linux版本網卡名字可能不一樣,通常可能是eth0,CentOS7.0是ens33
以下是ifcfg-ens33里的內容:
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
##IPV6INIT=yes
##IPV6_AUTOCONF=yes
##IPV6_DEFROUTE=yes
##IPV6_FAILURE_FATAL=no
##IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=45fe5552-7117-4c84-9742-c87adfa222b9
DEVICE=ens33
ONBOOT=yes
ZONE=public #這裡設置ZONE方便後面設置防火牆
IPADDR=192.168.31.10
NETMASK=255.255.255.0
GATEWAY=192.168.31.2
DNS1=192.168.31.2
虛擬機ifconfig

宿主機ipconfig
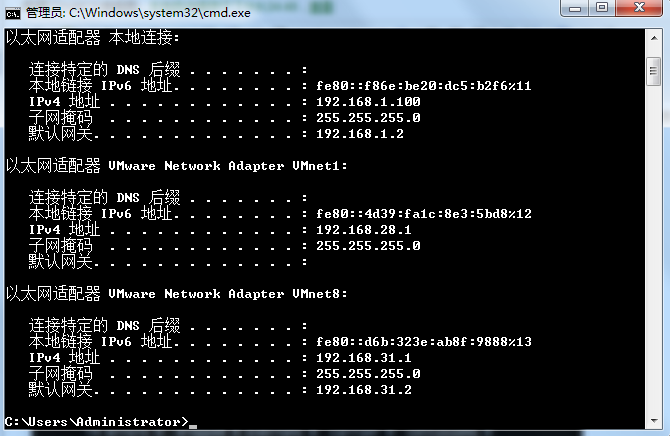
設置到這裡,宿主機可以ping通虛擬機,虛擬機可以ping通宿主機和網關。如果相互ping不同就需要檢查宿主機和虛擬機的防火牆。
三、設置主機名
修改hostname
vi /etc/sysconfig/network
NETWORKING=yes #使用網路
HOSTNAME=bigdata-senior01.home.com #設置主機名
配置hosts
vi /etc/host
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.31.10 bigdata-senior01.home.com
配置完linux的主機名,在windows的hosts里也需要配置一下192.168.31.10 bigdata-senior01.home.com
一定要設置主機名,一定要配置hosts,曾經被坑在這裡。
四、關閉selinux
selinux是Linux一個子安全機制,但是,請關閉它。
vi /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
五、Hadoop的用戶設置
1、 創建hadoop的普通用戶
useradd hadoop
passwd hadoop
2、 給hadoop用戶sudo許可權
vi /etc/sudoers
設置許可權(非生產環境可以隨意點)
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL
3、 切換到hadoop用戶
su - hadoop
4、 創建存放hadoop文件的目錄
sudo mkdir /opt/modules
5、 將hadoop文件夾的所有者指定為hadoop用戶
如果存放hadoop的目錄的所有者不是hadoop,之後hadoop運行中可能會有許可權問題。
sudo chown -R hadoop:hadoop /opt/modules
六、解壓Hadoop目錄文件
自行百度hadoop下載
1、 複製hadoop-3.1.0.tar.gz到/opt/modules目錄下。
2、 解壓hadoop-3.1.0.tar.gz
cd /opt/modules
tar -zxvf hadoop-3.1.0.tar.gz
七、配置hadoop環境變數
1、環境變數
vi /etc/profile
java的配置這裡也提一下:
#set java environment
JAVA_HOME=/home/java/jdk1.8.0_172
JRE_HOME=/home/java/jdk1.8.0_172/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
hadoop追加配置:
export HADOOP_HOME="/opt/modules/hadoop-3.1.0"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
執行:source /etc/profile 使得配置生效
驗證HADOOP_HOME參數:
echo $HADOOP_HOME
/opt/modules/hadoop-3.1.0
或者使用env檢查一下所有的配置情況。
2、 配置 hadoop-env.sh文件的JAVA_HOME參數
sudo vi ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
修改JAVA_HOME參數為:
export JAVA_HOME="/opt/modules/jdk1.8.0_172" #這裡一定要使用絕對路徑
3、 配置core-site.xml
vi ${HADOOP_HOME}/etc/hadoop/core-site.xml
(1) fs.defaultFS參數配置的是HDFS的地址。
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-senior01.home.com:9000</value>
</property>
(2) hadoop.tmp.dir配置的是Hadoop臨時目錄,比如HDFS的NameNode數據預設都存放這個目錄下,查看core-default.xml等預設配置文件,就可以看到很多依賴${hadoop.tmp.dir}的配置。
創建臨時目錄:
sudo mkdir -p /opt/data/tmp
將臨時目錄的所有者修改為hadoop:
sudo chown –R hadoop:hadoop /opt/data/tmp
修改hadoop.tmp.dir
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
最後core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-senior01.home.com:9000</value>
<description>HDFS的URI,文件系統://namenode標識:埠號</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
<description>namenode上本地的hadoop臨時文件夾</description>
</property>
</configuration>
八、配置HDFS,啟動HDFS
1、 配置hdfs-site.xml
vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本個數,配置預設是3,應小於datanode機器數量</description>
</property>
</property>
dfs.replication配置的是HDFS存儲時的備份數量,因為這裡是偽分散式環境只有一個節點,所以這裡設置為1。
其他配置,如果不配置以下屬性,hadoop將會在之前配置的臨時文件下麵創建name和data目錄
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hdfs/name</value>
<description>namenode上存儲hdfs名字空間元數據 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hdfs/data</value>
<description>datanode上數據塊的物理存儲位置</description>
</property>
2、 格式化HDFS
hdfs namenode –format #只需要在第一次的時候執行
格式化是對HDFS這個分散式文件系統中的DataNode進行分塊,統計所有分塊後的初始元數據的存儲在NameNode中。
格式化後,查看core-site.xml里hadoop.tmp.dir(/opt/data目錄)指定的目錄下是否有了dfs目錄,如果有,說明格式化成功。
註意許可權設置,最好把Hadoop設置成/opt/data目錄的所有者
sudo chown -R hadoop:hadoop /opt/data
查看NameNode格式化後的目錄。
ll /opt/data/tmp/dfs/name/current
3、 啟動NameNode
${HADOOP_HOME}/sbin/hadoop-daemon.sh start namenode
系統會告警,建議採用:hdfs --daemon start namenode
4、 啟動DataNode
${HADOOP_HOME}/sbin/hadoop-daemon.sh start datanode
系統會告警,建議採用:hdfs --daemon start datanode
5、 啟動SecondaryNameNode
${HADOOP_HOME}/sbin/hadoop-daemon.sh start secondarynamenode
系統會告警,建議採用:hdfs --daemon start secondarynamenode
6、 JPS命令查看是否已經啟動成功,有結果就是啟動成功了。
jps
1267 NameNode
1380 DataNode
1559 Jps
1528 SecondaryNameNode
7、 HDFS上測試創建目錄、上傳、下載文件
HDFS上創建目錄
hdfs dfs -mkdir /demo
上傳本地文件到HDFS上
hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/core-site.xml /demo
讀取HDFS上的文件內容
hdfs dfs -cat /demo/core-site.xml
從HDFS上下載文件到本地
hdfs dfs -get /demo/core-site.xml
查看目錄
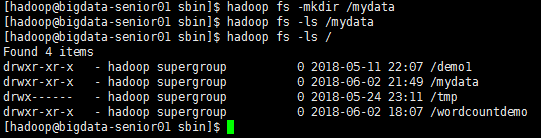
$ hdfs dfs -ls /demo
也可以使用hadoop fs -mkdir /mydata這樣的命令
九、配置和啟動YARN
1、 配置mapred-site.xml
vi ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
添加配置如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
指定mapreduce運行在yarn框架上。
2、 配置yarn-site.xml
vi ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
添加配置如下:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-senior01.home.com</value>
</property>
yarn.nodemanager.aux-services配置了yarn的預設混洗方式,選擇為mapreduce的預設混洗演算法。
yarn.resourcemanager.hostname指定了Resourcemanager運行在哪個節點上。
3、 啟動Resourcemanager
${HADOOP_HOME}/sbin/yarn-daemon.sh start resourcemanager
系統會告警,建議採用:yarn --daemon start resourcemanager
4、 啟動nodemanager
[hadoop@bigdata-senior01 hadoop-3.1.0]$ ${HADOOP_HOME}/sbin/yarn-daemon.sh start nodemanager
系統會告警,建議採用:yarn --daemon start nodemanager
5、 查看是否啟動成功
[hadoop@localhost sbin]$ jps
1395 DataNode
1507 SecondaryNameNode
2150 Jps
2075 NodeManager
1292 NameNode
1628 ResourceManager
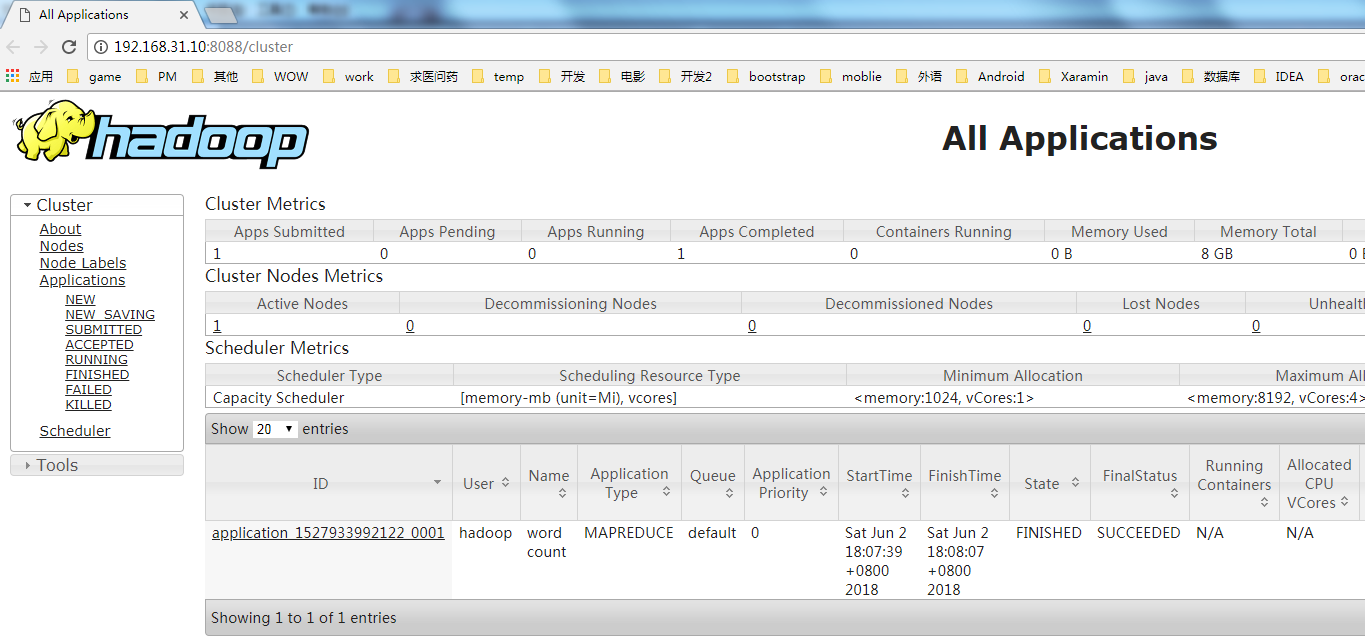
6、YARN的Web頁面
YARN的Web客戶端埠號是8088,通過http://192.168.31.10:8088/可以查看。
如果防火牆沒有關閉,還需要添加埠:
firewall-cmd --zone=public --add-port=8088/tcp --permanent
HDFS的web頁面:
http://192.168.31.10:9870/
firewall-cmd --zone=public --add-port=9870/tcp --permanent
#註意這裡,hadoop3.0以前hdfs的埠號不是9870
以後類似需要埠訪問的web管理頁面,都需要在防火牆裡添加埠,也可以直接關閉防火牆。
移除埠:firewall-cmd --zone=public --remove-port=8088/tcp --permanent
十、運行MapReduce Job
在Hadoop的share目錄里,自帶了一些jar包,裡面帶有一些mapreduce實例小例子,位置在$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar,可以運行這些例子體驗剛搭建好的Hadoop平臺,我們這裡來運行最經典的WordCount實例。版本不同,這個jar包的名字也有點區別。
1、添加類庫路徑
因為運行的是hadoop自帶的例子,所以例子里的類庫要加入
編輯 Hadoop 安裝目錄下 etc/hadoop/mapred-site.xml 文件,在 <configuration> 標簽和 </configuration> 標簽之間添加如下配置:
<property>
<description>CLASSPATH for MR applications. A comma-separated list
of CLASSPATH entries. If mapreduce.application.framework is set then this
must specify the appropriate classpath for that archive, and the name of
the archive must be present in the classpath.
If mapreduce.app-submission.cross-platform is false, platform-specific
environment vairable expansion syntax would be used to construct the default
CLASSPATH entries.
For Linux:
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*.
For Windows:
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*.
If mapreduce.app-submission.cross-platform is true, platform-agnostic default
CLASSPATH for MR applications would be used:
{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/*,
{{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/lib/*
Parameter expansion marker will be replaced by NodeManager on container
launch based on the underlying OS accordingly.
</description>
<name>mapreduce.application.classpath</name>
<value>/opt/modules/hadoop-3.1.0/share/hadoop/mapreduce/*, /opt/modules/hadoop-3.1.0/share/hadoop/mapreduce/lib-examples/*</value>
</property>
註意,這一點非常重要,必須填寫完整的路徑,即必須是絕對路徑,不能包含變數。
2、記憶體配置:
-----
安裝虛擬機的時候記憶體原本是1G,運行job一直出錯,各種修改配置文件里的記憶體都不行,最後把虛擬機記憶體調整成2G以運行成功。
關於記憶體這塊,要非常熟悉hadoop的各類配置才好下手,新手入門還是先不折騰。
-----
3、 創建測試用的Input文件
創建輸入目錄:
hdfs dfs -mkdir -p /wordcountdemo/input
創建原始文件:
在本地/opt/data目錄創建一個文件mydata.input,內容如下:
cat /opt/data/mydata.input
abc def kkk
abc kkk sss
ddd abc sss
abc abc sss
將wc.input文件上傳到HDFS的/wordcountdemo/input目錄中:
hdfs dfs -put /opt/data/mydata.input /wordcountdemo/input
運行WordCount MapReduce Job
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.0.jar wordcount /wordcountdemo/input /wordcountdemo/output
2018-05-29 22:18:34,201 INFO client.RMProxy: Connecting to ResourceManager at bigdata-senior01.home.com/192.168.31.10:8032
2018-05-29 22:18:35,314 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1527603486527_0001
2018-05-29 22:18:36,437 INFO input.FileInputFormat: Total input files to process : 1
2018-05-29 22:18:37,402 INFO mapreduce.JobSubmitter: number of splits:1
2018-05-29 22:18:37,472 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2018-05-29 22:18:37,834 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1527603486527_0001
2018-05-29 22:18:37,845 INFO mapreduce.JobSubmitter: Executing with tokens: []
2018-05-29 22:18:38,124 INFO conf.Configuration: resource-types.xml not found
2018-05-29 22:18:38,124 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2018-05-29 22:18:38,671 INFO impl.YarnClientImpl: Submitted application application_1527603486527_0001
2018-05-29 22:18:38,737 INFO mapreduce.Job: The url to track the job: http://bigdata-senior01.home.com:8088/proxy/application_1527603486527_0001/
2018-05-29 22:18:38,738 INFO mapreduce.Job: Running job: job_1527603486527_0001
2018-05-29 22:18:51,002 INFO mapreduce.Job: Job job_1527603486527_0001 running in uber mode : false
2018-05-29 22:18:51,003 INFO mapreduce.Job: map 0% reduce 0%
2018-05-29 22:18:57,124 INFO mapreduce.Job: map 100% reduce 0%
2018-05-29 22:19:04,187 INFO mapreduce.Job: map 100% reduce 100%
2018-05-29 22:19:06,209 INFO mapreduce.Job: Job job_1527603486527_0001 completed successfully
2018-05-29 22:19:06,363 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=425699
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=202
HDFS: Number of bytes written=60
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4455
Total time spent by all reduces in occupied slots (ms)=4530
Total time spent by all map tasks (ms)=4455
Total time spent by all reduce tasks (ms)=4530
Total vcore-milliseconds taken by all map tasks=4455
Total vcore-milliseconds taken by all reduce tasks=4530
Total megabyte-milliseconds taken by all map tasks=4561920
Total megabyte-milliseconds taken by all reduce tasks=4638720
Map-Reduce Framework
Map input records=4
Map output records=11
Map output bytes=115
Map output materialized bytes=94
Input split bytes=131
Combine input records=11
Combine output records=7
Reduce input groups=7
Reduce shuffle bytes=94
Reduce input records=7
Reduce output records=7
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=172
CPU time spent (ms)=1230
Physical memory (bytes) snapshot=388255744
Virtual memory (bytes) snapshot=5476073472
Total committed heap usage (bytes)=165810176
Peak Map Physical memory (bytes)=242692096
Peak Map Virtual memory (bytes)=2733621248
Peak Reduce Physical memory (bytes)=145563648
Peak Reduce Virtual memory (bytes)=2742452224
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=71
File Output Format Counters
Bytes Written=60
查看輸出結果目錄
hdfs dfs -ls /wordcountdemo/output
--用命令:hadoop fs -cat /wordcountdemo/output/part-r-00000,也可以,上面也一樣
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2018-05-29 22:19 /wordcountdemo/output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 60 2018-05-29 22:19 /wordcountdemo/output/part-r-00000
output目錄中有兩個文件,_SUCCESS文件是空文件,有這個文件說明Job執行成功。
part-r-00000文件是結果文件,其中-r-說明這個文件是Reduce階段產生的結果,mapreduce程式執行時,可以沒有reduce階段,但是肯定會有map階段,如果沒有reduce階段這個地方有是-m-。
一個reduce會產生一個part-r-開頭的文件。
查看輸出文件內容。
hdfs dfs -cat /wordcountdemo/output/part-r-00000
在虛擬機上,因為記憶體不足這裡經常會出現的情況就是記憶體溢出,然後hadoop的運行容器被kill。
十一、開啟歷史服務
Hadoop開啟歷史服務可以在web頁面上查看Yarn上執行job情況的詳細信息。可以通過歷史伺服器查看已經運行完的Mapreduce作業記錄,比如用了多少個Map、用了多少個Reduce、作業提交時間、作業啟動時間、作業完成時間等信息。
mr-jobhistory-daemon.sh start historyserver、
此命令已經被棄用,建議使用:mapred --daemon start historyserver
開啟後,可以通過Web頁面查看歷史伺服器:
http://bigdata-senior01.home.com:19888/
歷史伺服器的Web埠預設是19888,可以查看Web界面。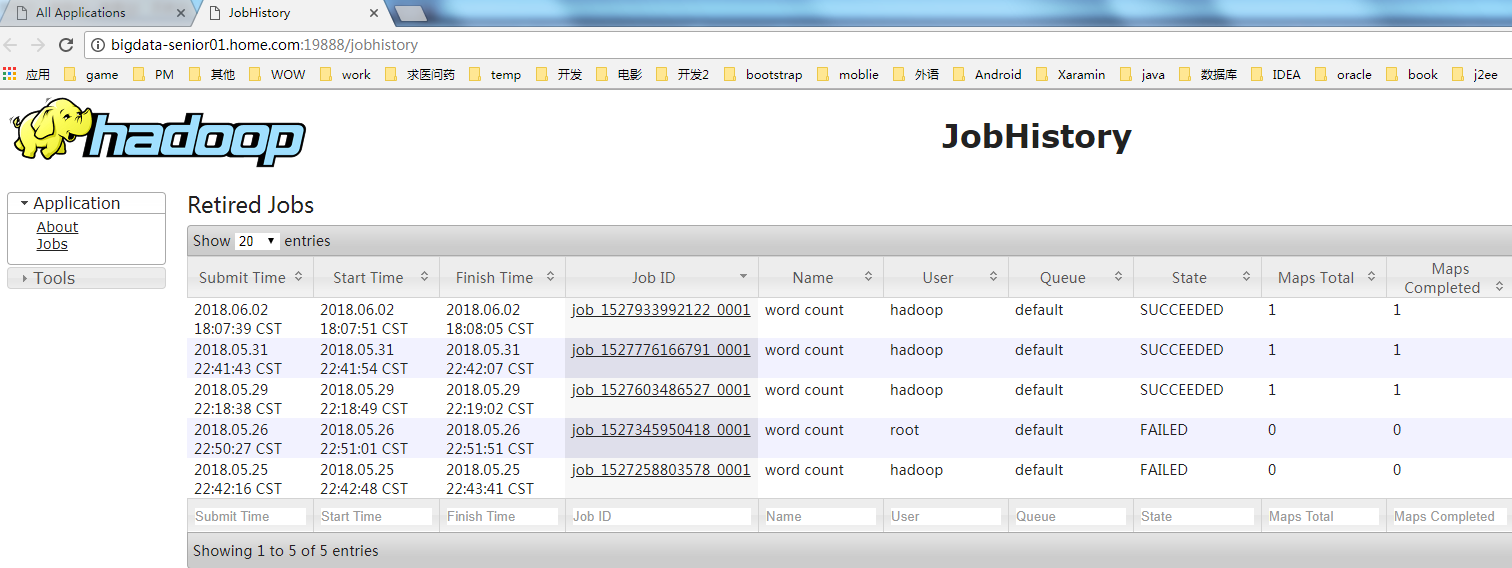
十二、節點免密登錄
是指通過證書認證的方式登陸,使用一種被稱為"公私鑰"認證的方式來進行ssh登錄
如果我們需要使用hadoop目錄sbin/下的便捷腳本運行hadoop,就需要配置免密登錄
root用戶下:
ssh-keygen -t rsa 一路回車下去
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #.ssh這個隱藏目錄的許可權要求是700。
chmod 600 ~/.ssh/authorized_keys #這個文件需要特殊的許可權要求。
這樣就可以運行諸如:start-all.sh,start-dfs.sh這些腳本。
最後,說說hadoop3.0後埠的變化:
Namenode 埠:
50470 --> 9871
50070 --> 9870
8020 --> 9820
Secondary NN 埠:
50091 --> 9869
50090 --> 9868
Datanode 埠:
50020 --> 9867
50010 --> 9866
50475 --> 9865
50075 --> 9864
https://www.cnblogs.com/asker009/p/9126354.html


