
一. 概述 sql server作為關係型資料庫,需要進行數據存儲, 那在運行中就會不斷的與硬碟進行讀寫交互。如果讀寫不能正確快速的完成,就會出現性能問題以及資料庫損壞問題。下麵講講引起I/O的產生,以及分析優化。 二.sql server 主要磁碟讀寫的行為 2.1 從數據文件(.mdf)里, 讀 ...
一. 概述
sql server作為關係型資料庫,需要進行數據存儲, 那在運行中就會不斷的與硬碟進行讀寫交互。如果讀寫不能正確快速的完成,就會出現性能問題以及資料庫損壞問題。下麵講講引起I/O的產生,以及分析優化。
二.sql server 主要磁碟讀寫的行為
2.1 從數據文件(.mdf)里, 讀入新數據頁到記憶體。前頁講述記憶體時我們知道,如果想要的數據不在記憶體中時,就會從硬碟的數據文件里以頁面為最小單位,讀取到記憶體中,還包括預讀的數據。 當記憶體中存在,就不會去磁碟讀取數據。足夠的記憶體可以最小化磁碟I/O,因為磁碟的速度遠慢於記憶體。
2.2 預寫日誌系統(WAL),嚮日志文件(.ldf)寫入增刪改的日誌記錄。 用來維護數據事務的ACID。
2.3 Checkpoint 檢查點發生時,將臟頁數據寫入到數據文件 ,在sp_configure的recovery interval 控制著sql server多長時間進行一次Checkpoint, 如果經常做Checkpoint,那每次產生的硬碟寫就不會太多,對硬碟衝擊不會太大。如果隔長時間一次Checkpoint,不做Checkpoint時性能可能會比較快,但累積了大量的修改,可能要產生大量的寫,這時性能會受影響。在絕大多數據情況下,預設設置是比較好的,沒必要去修改。
2.4 記憶體不足時,Lazy Write發生,會將緩衝區中修改過的數據頁面同步到硬碟的數據文件中。由於記憶體的空間不足觸發了Lazy Write, 主動將記憶體中很久沒有使用過的數據頁和執行計劃清空。Lazy Write一般不被經常調用。
2.5 CheckDB, 索引維護,全文索引,統計信息,備份數據,高可用同步日誌等。
三. 磁碟讀寫的相關分析
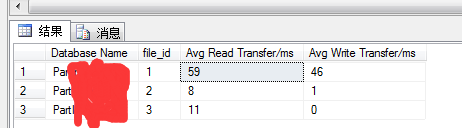
3.1 sys.dm_io_virtual_file_stats 獲取數據文件和日誌文件的I/O 統計信息。該函數從sql server 2008開始,替換動態管理視圖fn_virtualfilestats函數。 哪些文件經常要做讀num_of_reads,哪些經常要做寫num_of_writes,哪些讀寫經常要等待io_stall_*。為了獲取有意義的數據,需要在短時間內對這些數據進行快照,然後將它們同基線數據相比較。
SELECT DB_NAME(database_id) AS 'Database Name', file_id, io_stall_read_ms / num_of_reads AS 'Avg Read Transfer/ms', io_stall_write_ms / num_of_writes AS 'Avg Write Transfer/ms' FROM sys.dm_io_virtual_file_stats(null, null) WHERE num_of_reads > 0 AND num_of_writes > 0
io_stall_read_ms:用戶等待文件,發出讀取所用的總時間(毫秒)。
io_stall_write: 用戶等待在該文件中完成寫入所用的總時間毫秒。
3.2 windows 性能計數器: Avg. Disk Sec/Read 這個計數器是指每秒從磁碟讀取數據的平均值
< 10 ms - 非常好
10 ~ 20 ms 之間- 還可以
20 ~50 ms 之間- 慢,需要關註
> 50 ms –嚴重的 I/O 瓶頸
3.4 I/O 物理記憶體讀取次數最多的前50條
SELECT TOP 50 qs.total_physical_reads,qs.execution_count, qs.total_physical_reads/qs.execution_count AS [avg I/O], qs. creation_time, qs.max_elapsed_time, qs.min_elapsed_time, SUBSTRING(qt.text,qs.statement_start_offset/2, (CASE WHEN qs.statement_end_offset=-1 THEN LEN(CONVERT(NVARCHAR(max),qt.text))*2 ELSE qs.statement_end_offset END -qs.statement_start_offset)/2) AS query_text, qt.dbid,dbname=DB_NAME(qt.dbid), qt.objectid, qs.sql_handle, qs.plan_handle from sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt ORDER BY qs.total_physical_reads DESC
3.5 使用sp_spaceused查看表的磁碟空間
exec sp_spaceused 'table_xx'
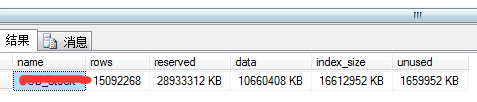
reserved:保留的空間總量
data:數據使用的空間總量
index_size:索引使用空間
Unused: 未用的空間量
3.6 監測I/0運行狀態 STATISTICS IO ON;
四 磁碟讀寫瓶頸的癥狀
4.1 errorlog里報告錯誤 833
4.2 sys.dm_os_wait_stats 視圖裡有大量等待狀態PAGEIOLATCH_* 或 WriteLog。當數據在緩衝區里沒有找到,連接的等待狀態就是PAGEIOLACTH_EX(寫) PAGEIOLATCH_SH(讀),然後發起非同步操作,將頁面讀入緩衝區中。像 waiting_tasks_count和wait_time_ms比較高的時候,經常要等待I/O,除在反映在數據文件上以外,還有writelog的日誌文件上。想要獲得有意義數據,需要做基線數據,查看感興趣的時間間隔。
select wait_type, waiting_tasks_count, wait_time_ms , max_wait_time_ms, signal_wait_time_ms from sys.dm_os_wait_stats where wait_type like 'PAGEIOLATCH%' order by wait_type
wait_type:等待類型
waiting_tasks_count:該等待類型的等待數
wait_time_ms:該等待類型的總等待時間(包括一個進程懸掛狀態(Suspend)和可運行狀態(Runnable)花費的總時間)
max_wait_time_ms:該等待類型的最長等待時間
signal_wait_time_ms:正在等待的線程從收到信號通知到其開始運行之間的時差(一個進程可運行狀態Runnable花費的總時間)
i/o等待時間==wait_time_ms - signal_wait_time_ms
五 優化磁碟I/O
5.1 數據文件里頁面碎片整理。 當表發生增刪改操作時索引都會產生碎片(索引葉級的頁拆分),碎片是指索引上的頁不再具有物理連續性時,就會產生碎片。比如你查詢10條數據,碎片少時,可能只掃描2個頁,但碎片多時可能要掃描更多頁(後面講索引時在細說)。
5.2 表格上的索引。比如:建議每個表都包含聚集索引,這是因為數據存儲分為堆和B-Tree, 按B-Tree空間占用率更高。 充分使用索引減少對I/0的需求。
5.3 數據文件,日誌文件,TempDB文件建議存放不同物理磁碟,日誌文件放寫入速度比較快的磁碟上,例如 RAID 10的分區
5.4 文件空間管理,設置資料庫增長時要按固定大小增長,而不能按比例,這樣避免一次增長太多或太少所帶來的不必要麻煩。建議對比較小的資料庫設置一次增長50MB到100MB。下圖顯示如果按5%來增長近10G, 如果有一個應用程式在嘗試插入一行,但是沒有空間可用。那麼資料庫可能會開始增長一個近10G, 文件的增長可能會耗用太長的時間,以至於客戶端程式插入查詢失敗。

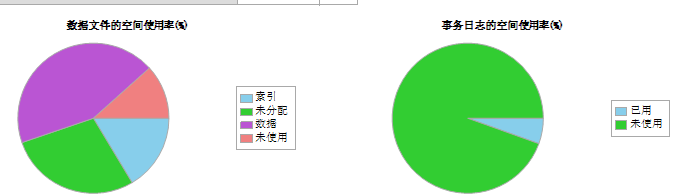
5.5 避免自動收縮文件,如果設置了此功能,sql server會每隔半小時檢查文件的使用,如果空閑空間>25%,會自動運行dbcc shrinkfile 動作。自動收縮線程的會話ID SPID總是6(以後可能有變) 如下顯示自動收縮為False。

5.6 如果資料庫的恢復模式是:完整。 就需要定期做日誌備份,避免日誌文件無限的增長,用於磁碟空間。


