
最近在做一個人群標簽的項目,也就是根據客戶的一些交易行為自動給客戶打標簽,而這些標簽更有利於我們做商品推薦,目前打上標簽的數據已達5億+, 用戶量大概1億+,項目需求就是根據各種組合條件尋找標簽和人群信息。 舉個例子: 集合A: ( 購買過“牙膏“的人交易金額在10-500元並且交易次數在5次的客戶 ...
最近在做一個人群標簽的項目,也就是根據客戶的一些交易行為自動給客戶打標簽,而這些標簽更有利於我們做商品推薦,目前打上標簽的數據已達5億+,
用戶量大概1億+,項目需求就是根據各種組合條件尋找標簽和人群信息。
舉個例子:
集合A: ( 購買過“牙膏“的人交易金額在10-500元並且交易次數在5次的客戶並且平均訂單價在20 -200元) 。
集合B: (購買過“牙刷”的人交易金額在5-50 並且交易次數在3次的客戶並且平均訂單價在10-30元)。
求:<1> 獲取集合A 交 集合B 客戶數 和 客戶的具體信息,希望時間最好不要超過15s。
上面這種問題如果你用mysql做的話,基本上是算不出來的,時間上更無法滿足項目需求。
一:尋找解決方案
如果你用最小的工作量解決這個問題的話,可以搭建一個分散式的Elasticsearch集群,查詢中相關的Nick,AvgPrice,TradeCount,TradeAmont欄位可以用
keyword模式存儲,避免出現fieldData欄位無法查詢的問題,雖然ES大體上可以解決這個問題,但是熟悉ES的朋友應該知道,它的各種查詢都是我們通過json
的格式去定製,雖然可以使用少量的script腳本,但是靈活度相比spark來說的話太弱基了,用scala函數式語言定製那是多麼的方便,第二個是es在group by的
桶分頁特別不好實現,也很麻煩,社區裡面有一些 sql on elasticsearch 的框架,大家可以看看:https://github.com/NLPchina/elasticsearch-sql,只支持一
些簡單的sql查詢,不過像having這樣的關鍵詞是不支持的,跟sparksql是沒法比的,基於以上原因,決定用spark試試看。
二:環境搭建
搭建spark集群,需要hadoop + spark + java + scala,搭建之前一定要註意各自版本的對應關係,否則遇到各種奇葩的錯誤讓你好受哈!!!不信去官網看
看: https://spark.apache.org/downloads.html 。
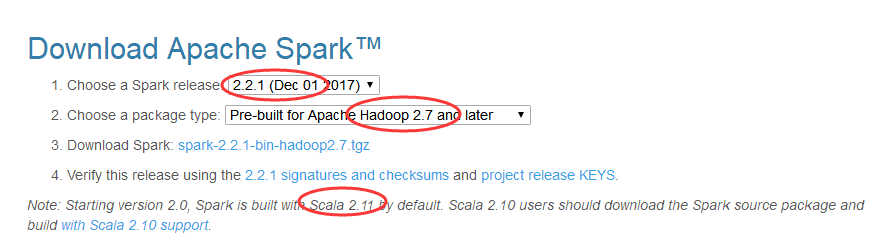
這裡我採用的組合是:
hadoop-2.7.6.tar.gz
jdk-8u144-linux-x64.tar.gz
scala-2.11.0.tgz
spark-2.2.1-bin-hadoop2.7.tgz
jdk-8u144-linux-x64.tar.gz
mysql-connector-java-5.1.46.jar
sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
使用3台虛擬機:一臺【namenode +resourcemanager + spark master node】 + 二台 【datanode + nodemanager + spark work data】
192.168.2.227 hadoop-spark-master
192.168.2.119 hadoop-spark-salve1
192.168.2.232 hadoop-spark-salve2
1. 先配置三台機器的免ssh登錄。
[root@localhost ~]# ssh-keygen -t rsa -P '' Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): /root/.ssh/id_rsa already exists. Overwrite (y/n)? y Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 0f:4e:26:4a:ce:7d:08:b0:7e:13:82:c6:10:77:a2:5d [email protected] The key's randomart image is: +--[ RSA 2048]----+ |. o E | | = + | |o o | |o. o | |.oo + . S | |.. = = * o | | . * o o . | | . . . | | | +-----------------+ [root@localhost ~]# ls /root/.ssh authorized_keys id_rsa id_rsa.pub known_hosts [root@localhost ~]#
2. 然後將公鑰文件 id_rsa.pub copy到另外兩台機器,這樣就可以實現hadoop-spark-master 免密登錄到另外兩台
slave上去了。
scp /root/.ssh/id_rsa.pub root@192.168.2.119:/root/.ssh/authorized_keys scp /root/.ssh/id_rsa.pub root@192.168.2.232:/root/.ssh/authorized_keys cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
3. 在三台機器上增加如下的host映射。
[root@hadoop-spark-master ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.2.227 hadoop-spark-master 192.168.2.119 hadoop-spark-salve1 192.168.2.232 hadoop-spark-salve2
4. 然後就是把我列舉的那些 tar.gz 下載下來之後,在/etc/profile中配置如下,然後copy到另外兩台salves機器上。
[root@hadoop-spark-master ~]# tail -10 /etc/profile export JAVA_HOME=/usr/myapp/jdk8 export NODE_HOME=/usr/myapp/node export SPARK_HOME=/usr/myapp/spark export SCALA_HOME=/usr/myapp/scala export HADOOP_HOME=/usr/myapp/hadoop export HADOOP_CONF_DIR=/usr/myapp/hadoop/etc/hadoop export LD_LIBRARY_PATH=/usr/myapp/hadoop/lib/native:$LD_LIBRARY_PATH export SQOOP=/usr/myapp/sqoop export NODE=/usr/myapp/node export PATH=$NODE/bin:$SQOOP/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP/sbin$SPARK_HOME/bin:$NODE_HOME/bin:$JAVA_HOME/bin:$PATH
5. 最後就是hadoop的幾個配置文件的配置了。
《1》core-site.xml
[root@hadoop-spark-master hadoop]# cat core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/myapp/hadoop/data</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-spark-master:9000</value> </property> </configuration>
《2》 hdfs-site.xml :當然也可以在這裡使用 dfs.datanode.data.dir 掛載多個硬碟:
[root@hadoop-spark-master hadoop]# cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
《3》 mapred-site.xml 這個地方將mapreduce的運作寄存於yarn集群。
[root@hadoop-spark-master hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
《4》 yarn-site.xml 【這裡要配置resoucemanager的相關地址,方便slave進行連接,否則你的集群會跑不起來的】
[root@hadoop-spark-master hadoop]# cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>hadoop-spark-master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop-spark-master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop-spark-master:8031</value> </property> </configuration>
《5》 修改slaves文件,裡面寫入的各自salve的地址。
[root@hadoop-spark-master hadoop]# cat slaves
hadoop-spark-salve1
hadoop-spark-salve2
《6》這些都配置完成之後,可以用scp把整個hadoop文件scp到兩台slave機器上。
scp /usr/myapp/hadoop [email protected]:/usr/myapp/hadoop scp /usr/myapp/hadoop [email protected]:/usr/myapp/hadoop
《7》因為hdfs是分散式文件系統,使用之前先給hdfs格式化一下,因為當前hadoop已經灌了很多數據,就不真的執行format啦!
[root@hadoop-spark-master bin]# ./hdfs namenode -format
[root@hadoop-spark-master bin]# pwd
/usr/myapp/hadoop/bin
《8》 然後分別開啟 start-dfs.sh 和 start-yarn.sh ,或者乾脆點直接執行 start-all.sh 也可以,不然後者已經是官方準備廢棄的方式。
[root@hadoop-spark-master sbin]# ls
distribute-exclude.sh hdfs-config.sh refresh-namenodes.sh start-balancer.sh start-yarn.cmd stop-balancer.sh stop-yarn.cmd
hadoop-daemon.sh httpfs.sh slaves.sh start-dfs.cmd start-yarn.sh stop-dfs.cmd stop-yarn.sh
hadoop-daemons.sh kms.sh start-all.cmd start-dfs.sh stop-all.cmd stop-dfs.sh yarn-daemon.sh
hdfs-config.cmd mr-jobhistory-daemon.sh start-all.sh start-secure-dns.sh stop-all.sh stop-secure-dns.sh yarn-daemons.sh
《9》 記住,只要在hadoop-spark-master 節點開啟 dfs 和yarn就可以了,不需要到其他機器。
[root@hadoop-spark-master sbin]# ./start-dfs.sh
Starting namenodes on [hadoop-spark-master]
hadoop-spark-master: starting namenode, logging to /usr/myapp/hadoop/logs/hadoop-root-namenode-hadoop-spark-master.out
hadoop-spark-salve2: starting datanode, logging to /usr/myapp/hadoop/logs/hadoop-root-datanode-hadoop-spark-salve2.out
hadoop-spark-salve1: starting datanode, logging to /usr/myapp/hadoop/logs/hadoop-root-datanode-hadoop-spark-salve1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/myapp/hadoop/logs/hadoop-root-secondarynamenode-hadoop-spark-master.out
[root@hadoop-spark-master sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/myapp/hadoop/logs/yarn-root-resourcemanager-hadoop-spark-master.out
hadoop-spark-salve1: starting nodemanager, logging to /usr/myapp/hadoop/logs/yarn-root-nodemanager-hadoop-spark-salve1.out
hadoop-spark-salve2: starting nodemanager, logging to /usr/myapp/hadoop/logs/yarn-root-nodemanager-hadoop-spark-salve2.out
[root@hadoop-spark-master sbin]# jps
5671 NameNode
5975 SecondaryNameNode
6231 ResourceManager
6503 Jps
然後到其他兩台slave上可以看到dataNode都開啟了。
[root@hadoop-spark-salve1 ~]# jps 5157 Jps 4728 DataNode 4938 NodeManager
[root@hadoop-spark-salve2 ~]# jps 4899 Jps 4458 DataNode 4669 NodeManager
到此hadoop就搭建完成了。
三:Spark搭建
如果僅僅是搭建spark 的 standalone模式的話,只需要在conf下修改slave文件即可,把兩個work節點塞進去。
[root@hadoop-spark-master conf]# tail -5 slaves # A Spark Worker will be started on each of the machines listed below hadoop-spark-salve1 hadoop-spark-salve2 [root@hadoop-spark-master conf]# pwd /usr/myapp/spark/conf
然後還是通過scp 把整個conf文件copy過去即可,然後在sbin目錄下執行start-all.sh 腳本即可。
[root@hadoop-spark-master sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/myapp/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop-spark-master.out hadoop-spark-salve1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/myapp/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop-spark-salve1.out hadoop-spark-salve2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/myapp/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop-spark-salve2.out [root@hadoop-spark-master sbin]# jps 6930 Master 7013 Jps 5671 NameNode 5975 SecondaryNameNode 6231 ResourceManager [root@hadoop-spark-master sbin]#
然後你會發現slave1 和 slave2 節點上多了一個work節點。
[root@hadoop-spark-salve1 ~]# jps 4728 DataNode 4938 NodeManager 5772 Jps 5646 Worker
[root@hadoop-spark-salve2 ~]# jps 5475 Jps 4458 DataNode 4669 NodeManager 5342 Worker
接下來就可以看下成果啦。
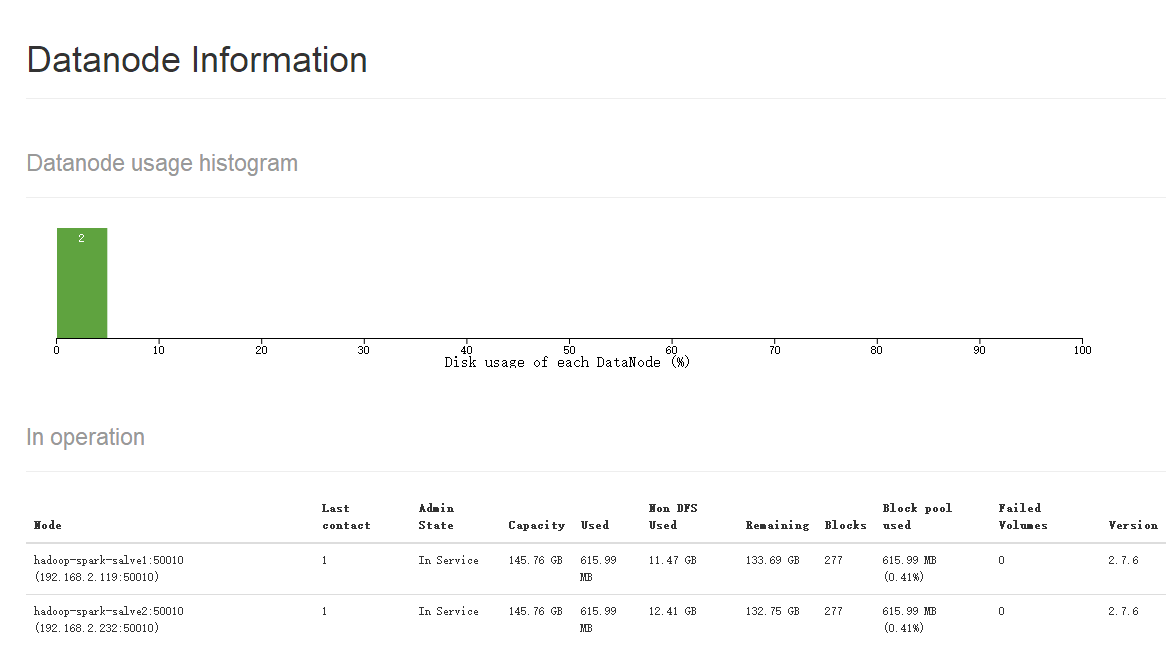
http://hadoop-spark-master:50070/dfshealth.html#tab-datanode 這個是hdfs 的監控視圖,可以清楚的看到有兩個DataNode。
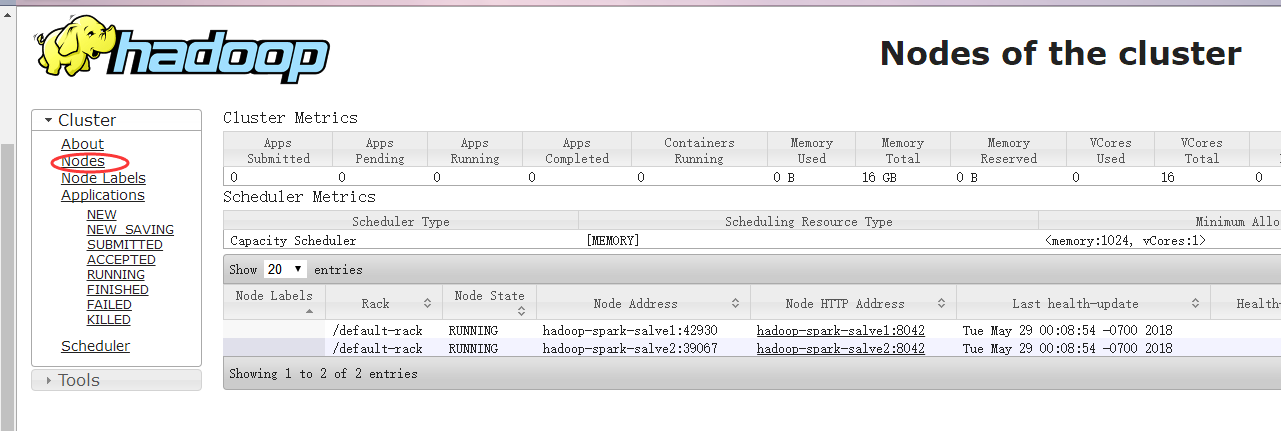
http://hadoop-spark-master:8088/cluster/nodes 這個是yarn的一個節點監控。
http://hadoop-spark-master:8080/ 這個就是spark的計算集群。
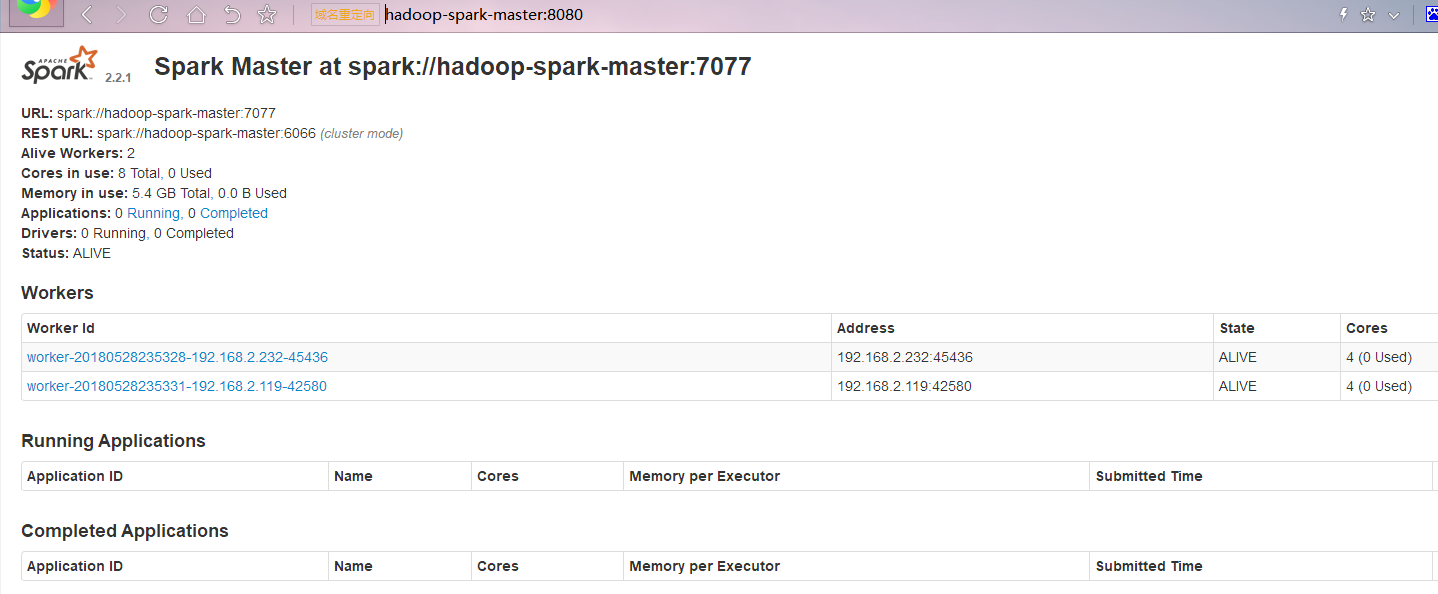
四: 使用sqoop導入數據
基礎架構搭建之後,現在就可以藉助sqoop將mysql的數據導入到hadoop中,導入的格式採用parquet 列式存儲格式,不過這裡要註意的一點就是一定要
把mysql-connector-java-5.1.46.jar 這個驅動包丟到 sqoop的lib目錄下。
[root@hadoop-spark-master lib]# ls ant-contrib-1.0b3.jar commons-logging-1.1.1.jar kite-data-mapreduce-1.1.0.jar parquet-format-2.2.0-rc1.jar ant-eclipse-1.0-jvm1.2.jar hsqldb-1.8.0.10.jar kite-hadoop-compatibility-1.1.0.jar parquet-generator-1.6.0.jar avro-1.8.1.jar jackson-annotations-2.3.1.jar mysql-connector-java-5.1.46.jar parquet-hadoop-1.6.0.jar avro-mapred-1.8.1-hadoop2.jar jackson-core-2.3.1.jar opencsv-2.3.jar parquet-jackson-1.6.0.jar commons-codec-1.4.jar jackson-core-asl-1.9.13.jar paranamer-2.7.jar slf4j-api-1.6.1.jar commons-compress-1.8.1.jar jackson-databind-2.3.1.jar parquet-avro-1.6.0.jar snappy-java-1.1.1.6.jar commons-io-1.4.jar jackson-mapper-asl-1.9.13.jar parquet-column-1.6.0.jar xz-1.5.jar commons-jexl-2.1.1.jar kite-data-core-1.1.0.jar parquet-common-1.6.0.jar commons-lang3-3.4.jar kite-data-hive-1.1.0.jar parquet-encoding-1.6.0.jar [root@hadoop-spark-master lib]# pwd /usr/myapp/sqoop/lib
接下來我們就可以導入數據了,我準備把db=zuanzhan ,table=dsp_customertag的表,大概155w的數據導入到hadoop的test路徑中,因為是測試環
境沒辦法,文件格式為parquet列式存儲。
[root@hadoop-spark-master lib]# [root@hadoop-spark-master bin]# sqoop import --connect jdbc:mysql://192.168.2.166:3306/zuanzhan --username admin --password 123456 --table dsp_customertag --m 1 --target-dir test --as-parquetfile bash: [root@hadoop-spark-master: command not found... [root@hadoop-spark-master lib]# sqoop import --connect jdbc:mysql://192.168.2.166:3306/zuanzhan --username admin --password 123456 --table dsp_customertag --m 1 --target-dir test --as-parquetfile Warning: /usr/myapp/sqoop/bin/../../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /usr/myapp/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /usr/myapp/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /usr/myapp/sqoop/bin/../../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 18/05/29 00:19:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 18/05/29 00:19:40 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 18/05/29 00:19:40 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18/05/29 00:19:40 INFO tool.CodeGenTool: Beginning code generation 18/05/29 00:19:40 INFO tool.CodeGenTool: Will generate java class as codegen_dsp_customertag 18/05/29 00:19:41 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `dsp_customertag` AS t LIMIT 1 18/05/29 00:19:42 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `dsp_customertag` AS t LIMIT 1 18/05/29 00:19:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/myapp/hadoop Note: /tmp/sqoop-root/compile/0020f679e735b365bf96dabecb1611de/codegen_dsp_customertag.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 18/05/29 00:19:48 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/0020f679e735b365bf96dabecb1611de/codegen_dsp_customertag.jar 18/05/29 00:19:48 WARN manager.MySQLManager: It looks like you are importing from mysql. 18/05/29 00:19:48 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 18/05/29 00:19:48 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 18/05/29 00:19:48 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 18/05/29 00:19:48 WARN manager.CatalogQueryManager: The table dsp_customertag contains a multi-column primary key. Sqoop will default to the column CustomerTagId only for this job. 18/05/29 00:19:48 WARN manager.CatalogQueryManager: The table dsp_customertag contains a multi-column primary key. Sqoop will default to the column CustomerTagId only for this job. 18/05/29 00:19:48 INFO mapreduce.ImportJobBase: Beginning import of dsp_customertag 18/05/29 00:19:48 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 18/05/29 00:19:50 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `dsp_customertag` AS t LIMIT 1 18/05/29 00:19:50 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `dsp_customertag` AS t LIMIT 1 18/05/29 00:19:51 WARN spi.Registration: Not loading URI patterns in org.kitesdk.data.spi.hive.Loader 18/05/29 00:19:53 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 18/05/29 00:19:53 INFO client.RMProxy: Connecting to ResourceManager at hadoop-spark-master/192.168.2.227:8032 18/05/29 00:19:57 INFO db.DBInputFormat: Using read commited transaction isolation 18/05/29 00:19:57 INFO mapreduce.JobSubmitter: number of splits:1 18/05/29 00:19:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1527575811851_0001 18/05/29 00:19:57 INFO impl.YarnClientImpl: Submitted application application_1527575811851_0001 18/05/29 00:19:58 INFO mapreduce.Job: The url to track the job: http://hadoop-spark-master:8088/proxy/application_1527575811851_0001/ 18/05/29 00:19:58 INFO mapreduce.Job: Running job: job_1527575811851_0001 18/05/29 00:20:07 INFO mapreduce.Job: Job job_1527575811851_0001 running in uber mode : false 18/05/29 00:20:07 INFO mapreduce.Job: map 0% reduce 0% 18/05/29 00:20:26 INFO mapreduce.Job: map 100% reduce 0% 18/05/29 00:20:26 INFO mapreduce.Job: Job job_1527575811851_0001 completed successfully 18/05/29 00:20:26 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=142261 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=8616 HDFS: Number of bytes written=28954674 HDFS: Number of read operations=50 HDFS: Number of large read operations=0 HDFS: Number of write operations=10 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=16729 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=16729 Total vcore-milliseconds taken by all map tasks=16729 Total megabyte-milliseconds taken by all map tasks=17130496 Map-Reduce Framework Map input records=1556209 Map output records=1556209 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=1147 CPU time spent (ms)=16710 Physical memory (bytes) snapshot=283635712 Virtual memory (bytes) snapshot=2148511744 Total committed heap usage (bytes)=150994944 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 18/05/29 00:20:26 INFO mapreduce.ImportJobBase: Transferred 27.6133 MB in 32.896 seconds (859.5585 KB/sec) 18/05/29 00:20:26 INFO mapreduce.ImportJobBase: Retrieved 1556209 records.
然後可以在UI中看到有這麼一個parquet文件。

五:使用python對spark進行操作
之前使用scala對spark進行操作,使用maven進行打包,用起來不大方便,採用python還是很方便的,大家先要下載一個pyspark的安裝包,一定要和spark
的版本對應起來。 pypy官網:https://pypi.org/project/pyspark/2.2.1/
你可以在master機器和開發機上直接安裝 pyspark 2.2.1 模板,這樣master機上執行就不需要通過pyspark-shell提交給spark集群了,下麵我使用清華大學的
臨時鏡像下載的,畢竟官網的pip install不要太慢。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==2.2.1
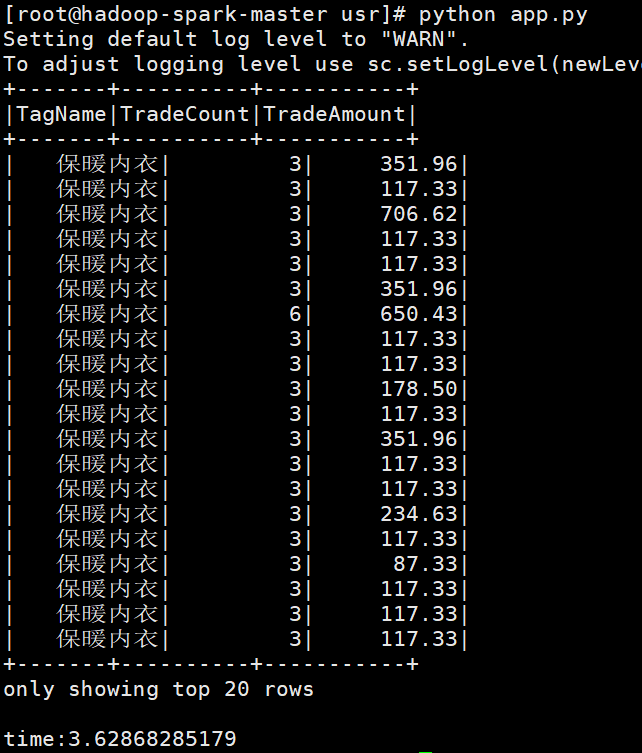
下麵就是app.py腳本,採用spark sql 的模式。
# coding=utf-8 import time; import sys; from pyspark.sql import SparkSession; from pyspark.conf import SparkConf # reload(sys); # sys.setdefaultencoding('utf8'); logFile = "hdfs://hadoop-spark-master:9000/user/root/test/fbd52109-d87a-4f8c-aa4b-26fcc95368eb.parquet"; sparkconf = SparkConf(); # sparkconf.set("spark.cores.max", "2"); # sparkconf.set("spark.executor.memory", "512m"); spark = SparkSession.builder.appName("mysimple").config(conf=sparkconf).master( "spark://hadoop-spark-master:7077").getOrCreate(); df = spark.read.parquet(logFile); df.createOrReplaceTempView("dsp_customertag"); starttime = time.time(); spark.sql("select TagName,TradeCount,TradeAmount from dsp_customertag").show(); endtime = time.time(); print("time:" + str(endtime - starttime)); spark.stop();
然後到shell上執行如下:
好了,本篇就說這麼多了,你可以使用更多的sql腳本,輸入數據量特別大還可以將結果再次寫入到hdfs或者mongodb中給客戶端使用,搭建過程中你可能會踩上
無數的坑,對於不能FQ的同學,你盡可以使用bing國際版 尋找答案吧!!!


