
一 進程空間分佈概述 對於一個進程,其空間分佈如下圖所示: 程式段(Text):程式代碼在記憶體中的映射,存放函數體的二進位代碼。 初始化過的數據(Data):在程式運行初已經對變數進行初始化的數據。 未初始化過的數據(BSS):在程式運行初未對變數進行初始化的數據。 棧 (Stack):存儲局部、臨 ...
一 進程空間分佈概述
對於一個進程,其空間分佈如下圖所示:
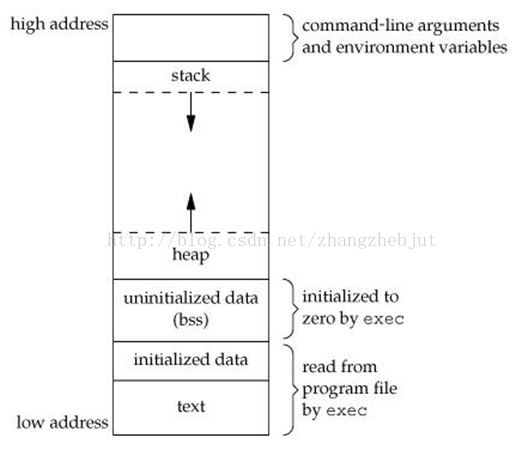
程式段(Text):程式代碼在記憶體中的映射,存放函數體的二進位代碼。
初始化過的數據(Data):在程式運行初已經對變數進行初始化的數據。
未初始化過的數據(BSS):在程式運行初未對變數進行初始化的數據。
棧 (Stack):存儲局部、臨時變數,函數調用時,存儲函數的返回指針,用於控制函數的調用和返回。在程式塊開始時自動分配記憶體,結束時自動釋放記憶體,其操作方式類似於數據結構中的棧。
堆 (Heap):存儲動態記憶體分配,需要程式員手工分配,手工釋放.註意它與數據結構中的堆是兩回事,分配方式類似於鏈表。
註:1.Text, BSS, Data段在編譯時已經決定了進程將占用多少VM 可以通過size,知道這些信息: 2. 正常情況下,Linux進程不能對用來存放程式代碼的記憶體區域執行寫操作,即程式代碼是以只讀的方式載入到記憶體中,但它可以被多個進程安全的共用。 二 內核空間和用戶空間 Linux的虛擬地址空間範圍為0~4G,Linux內核將這4G位元組的空間分為兩部分,將最高的1G位元組(從虛擬地址0xC0000000到0xFFFFFFFF)供內核使用,稱為“內核空間”。而將較低的3G位元組(從虛擬地址0x00000000到0xBFFFFFFF)供各個進程使用,稱為“用戶空間。因為每個進程可以通過系統調用進入內核,因此,Linux內核由系統內的所有進程共用。於是,從具體進程的角度來看,每個進程可以擁有4G位元組的虛擬空間。
Linux使用兩級保護機制:0級供內核使用,3級供用戶程式使用,每個進程有各自的私有用戶空間(0~3G),這個空間對系統中的其他進程是不可見的,最高的1GB位元組虛擬內核空間則為所有進程以及內核所共用。
內核空間中存放的是內核代碼和數據,而進程的用戶空間中存放的是用戶程式的代碼和數據。不管是內核空間還是用戶空間,它們都處於虛擬空間中。 雖然內核空間占據了每個虛擬空間中的最高1GB位元組,但映射到物理記憶體卻總是從最低地址(0x00000000),另外,使用虛擬地址可以很好的保護內核空間被用戶空間破壞,虛擬地址到物理地址轉換過程有操作系統和CPU共同完成(操作系統為CPU設置好頁表,CPU通過MMU單元進行地址轉換)。
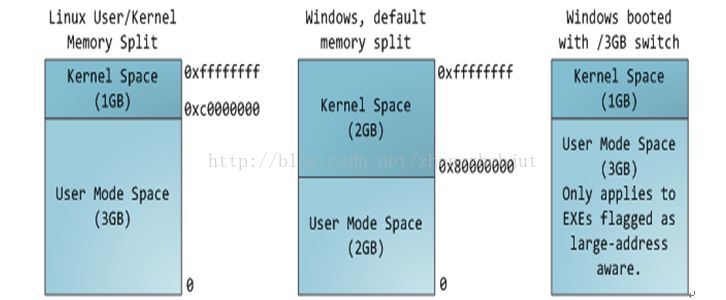
通常32位Linux內核地址空間劃分0~3G為用戶空間,3~4G為內核空間 註: 1.這裡是32位內核地址空間劃分,64位內核地址空間劃分是不同的 2.現代的操作系統都處於32位保護模式下。每個進程一般都能定址4G的物理空間。但是我們的物理記憶體一般都是幾百M,進程怎麼能獲得4G 的物理空間呢?這就是使用了虛擬地址的好處,通常我們使用一種叫做虛擬記憶體的技術來實現,因為可以使用硬碟中的一部分來當作記憶體使用 。
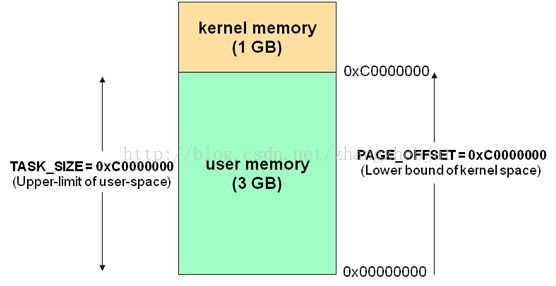 Linux系統對自身進行了劃分,一部分核心軟體獨立於普通應用程式,運行在較高的特權級別上,它們駐留在被保護的記憶體空間上,擁有訪問硬體設備的所有許可權,Linux將此稱為內核空間。
Linux系統對自身進行了劃分,一部分核心軟體獨立於普通應用程式,運行在較高的特權級別上,它們駐留在被保護的記憶體空間上,擁有訪問硬體設備的所有許可權,Linux將此稱為內核空間。相對地,應用程式則是在“用戶空間”中運行。運行在用戶空間的應用程式只能看到允許它們使用的部分系統資源,並且不能使用某些特定的系統功能,也不能直接訪問內核空間和硬體設備,以及其他一些具體的使用限制。
將用戶空間和內核空間置於這種非對稱訪問機制下有很好的安全性,能有效抵禦惡意用戶的窺探,也能防止質量低劣的用戶程式的侵害,從而使系統運行得更穩定可靠。 內核空間在頁表中擁有較高的特權級(ring2或以下),因此只要用戶態的程式試圖訪問這些頁,就會導致一個頁錯誤(page fault)。在Linux中,內核空間是持續存在的,並且在所有進程中都映射到同樣的物理記憶體,內核代碼和數據總是可定址的,隨時準備處理中斷和系統調用。與之相反,用戶模式地址空間的映射隨著進程切換的發生而不斷的變化,如下圖所示:
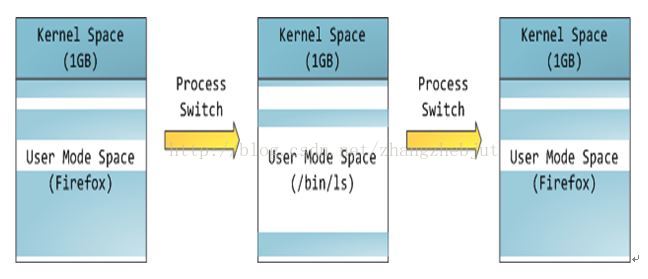
上圖中藍色區域表示映射到物理記憶體的虛擬地址,而白色區域表示未映射的部分。可以看出,Firefox使用了相當多的虛擬地址空間,因為它占用記憶體較多。
三 進程記憶體佈局 Linux進程標準的記憶體段佈局,如下圖所示,地址空間中的各個條帶對應於不同的記憶體段(memory segment),如:堆、棧之類的。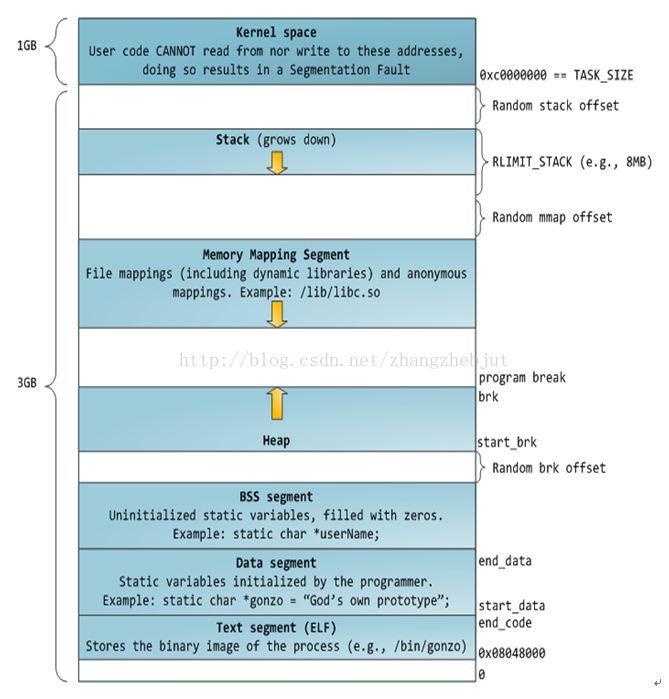 q
q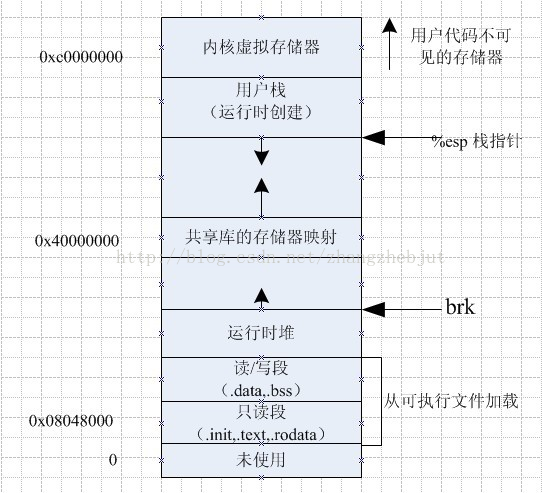 註:這些段只是簡單的虛擬記憶體地址空間範圍,與Intel處理器的段沒有任何關係。
幾乎每個進程的虛擬地址空間中各段的分佈都與上圖完全一致,這就給遠程發掘程式漏洞的人打開了方便之門。一個發掘過程往往需要引用絕對記憶體地址:棧地址,庫函數地址等。遠程攻擊者必須依賴地址空間分佈的一致性,來探索出這些地址。如果讓他們猜個正著,那麼有人就會被整了。因此,地址空間的隨機排布方式便逐漸流行起來,Linux通過對棧、記憶體映射段、堆的起始地址加上隨機的偏移量來打亂佈局。但不幸的是,32位地址空間相當緊湊,這給隨機化所留下的空間不大,削弱了這種技巧的效果。
棧
註:這些段只是簡單的虛擬記憶體地址空間範圍,與Intel處理器的段沒有任何關係。
幾乎每個進程的虛擬地址空間中各段的分佈都與上圖完全一致,這就給遠程發掘程式漏洞的人打開了方便之門。一個發掘過程往往需要引用絕對記憶體地址:棧地址,庫函數地址等。遠程攻擊者必須依賴地址空間分佈的一致性,來探索出這些地址。如果讓他們猜個正著,那麼有人就會被整了。因此,地址空間的隨機排布方式便逐漸流行起來,Linux通過對棧、記憶體映射段、堆的起始地址加上隨機的偏移量來打亂佈局。但不幸的是,32位地址空間相當緊湊,這給隨機化所留下的空間不大,削弱了這種技巧的效果。
棧
進程地址空間中最頂部的段是棧,大多數編程語言將之用於存儲函數參數和局部變數。調用一個方法或函數會將一個新的棧幀(stack frame)壓入到棧中,這個棧幀會在函數返回時被清理掉。由於棧中數據嚴格的遵守FIFO的順序,這個簡單的設計意味著不必使用複雜的數據結構來追蹤棧中的內容,只需要一個簡單的指針指向棧的頂端即可,因此壓棧(pushing)和退棧(popping)過程非常迅速、準確。進程中的每一個線程都有屬於自己的棧。
通過不斷向棧中壓入數據,超出其容量就會耗盡棧所對應的記憶體區域,這將觸發一個頁故障(page fault),而被Linux的expand_stack()處理,它會調用acct_stack_growth()來檢查是否還有合適的地方用於棧的增長。如果棧的大小低於RLIMIT_STACK(通常為8MB),那麼一般情況下棧會被加長,程式繼續執行,感覺不到發生了什麼事情。這是一種將棧擴展到所需大小的常規機制。然而,如果達到了最大棧空間的大小,就會棧溢出(stack overflow),程式收到一個段錯誤(segmentation fault)。
註:動態棧增長是唯一一種訪問未映射記憶體區域而被允許的情形,其他任何對未映射記憶體區域的訪問都會觸發頁錯誤,從而導致段錯誤。一些被映射的區域是只讀的,因此企圖寫這些區域也會導致段錯誤。 記憶體映射段 在棧的下方是記憶體映射段,內核將文件的內容直接映射到記憶體。任何應用程式都可以通過Linux的mmap()系統調用或者Windows的CreateFileMapping()/MapViewOfFile()請求這種映射。記憶體映射是一種方便高效的文件I/O方式,所以它被用來載入動態庫。創建一個不對應於任何文件的匿名記憶體映射也是可能的,此方法用於存放程式的數據。在Linux中,如果你通過malloc()請求一大塊記憶體,C運行庫將會創建這樣一個匿名映射而不是使用堆記憶體。“大塊”意味著比MMAP_THRESHOLD還大,預設128KB,可以通過mallocp()調整。 堆 與棧一樣,堆用於運行時記憶體分配;但不同的是,堆用於存儲那些生存期與函數調用無關的數據。大部分語言都提供了堆管理功能。在C語言中,堆分配的介面是malloc()函數。如果堆中有足夠的空間來滿足記憶體請求,它就可以被語言運行時庫處理而不需要內核參與,否則,堆會被擴大,通過brk()系統調用來分配請求所需的記憶體塊。堆管理是很複雜的,需要精細的演算法來應付我們程式中雜亂的分配模式,優化速度和記憶體使用效率。處理一個堆請求所需的時間會大幅度的變動。實時系統通過特殊目的分配器來解決這個問題。堆在分配過程中可能會變得零零碎碎,如下圖所示:
一般由程式員分配釋放, 若程式員不釋放,程式結束時可能由OS回收 。註意它與數據結構中的堆是兩回事,分配方式類似於鏈表。 BBS和數據段 在C語言中,BSS和數據段保存的都是靜態(全局)變數的內容。區別在於BSS保存的是未被初始化的靜態變數內容,他們的值不是直接在程式的源碼中設定的。BSS記憶體區域是匿名的,它不映射到任何文件。如果你寫static intcntActiveUsers,則cntActiveUsers的內容就會保存到BSS中去。 數據段保存在源代碼中已經初始化的靜態變數的內容。數據段不是匿名的,它映射了一部分的程式二進位鏡像,也就是源代碼中指定了初始值的靜態變數。所以,如果你寫static int cntActiveUsers=10,則cntActiveUsers的內容就保存在了數據段中,而且初始值是10。儘管數據段映射了一個文件,但它是一個私有記憶體映射,這意味著更改此處的記憶體不會影響被映射的文件。
你可以通過閱讀文件/proc/pid_of_process/maps來檢驗一個Linux進程中的記憶體區域。記住:一個段可能包含許多區域。比如,每個記憶體映射文件在mmap段中都有屬於自己的區域,動態庫擁有類似BSS和數據段的額外區域。有時人們提到“數據段”,指的是全部的數據段+BSS+堆。
你還可以通過nm和objdump命令來察看二進位鏡像,列印其中的符號,它們的地址,段等信息。最後需要指出的是,前文描述的虛擬地址佈局在linux中是一種“靈活佈局”,而且作為預設方式已經有些年頭了,它假設我們有值RLIMT_STACK。但是,當沒有該值得限制時,Linux退回到“經典佈局”,如下圖所示:
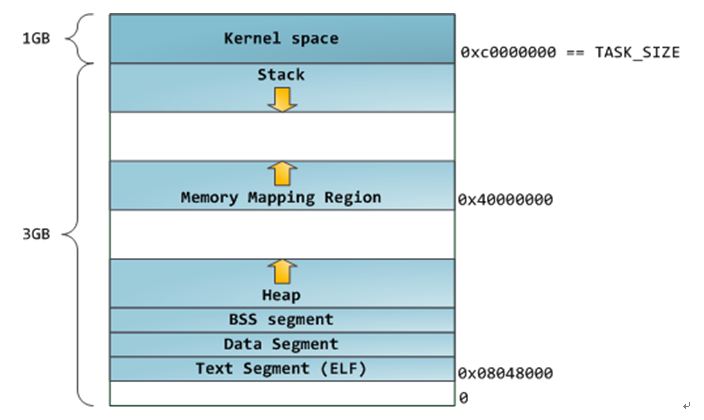
進程記憶體分佈
之前一直在分析棧,棧這個東西的作用也介紹得差不多了,但是棧在哪兒還沒有搞清楚,以及堆、代碼、全局變數它們在哪兒,這都牽涉到進程的記憶體分佈。
linux 0.01 的進程記憶體分佈
記憶體分佈隨著操作系統的更新換代,越來越科學合理,也越來越複雜,所以我們還是先瞭解一下早期操作系統的典型 linux 0.01 的進程的記憶體分佈:
linux 0.01 的一個進程固定擁有64MB的線性記憶體空間(ACM競賽中單個程式的最大記憶體占用限製為64MB,這肯定有貓膩O(∩_∩)O~),各個進程挨個放置在一張頁目錄表中,一個頁目錄表可管理4G的線性空間,因此 linux0.01 最多有 64個進程。每個進程的記憶體分佈如下:

- .text 里存的是機器碼序列
- .rodata 里存的是源字元串等只讀內容
- .data 里存的是初始化的全局變數
- .bss 上一篇介紹過了,存的是未初始化的全局變數
- 堆、棧就不用介紹了吧!
- 【註意】static 變數未初始化預設賦值為0或者空格。未初始化變數和初始化為0,都分配在.bss段。
.text .rodata .data .bss 是常駐記憶體的,也就是說進程從開始運行到進程僵死它們一直蹲在那裡,所以訪問它們用的是常量地址;而棧是不斷的加幀(函數調用)、減幀(函數返回)的,幀內的局部變數只能用相對於當前 esp(指向棧頂)或 ebp(指向當前幀)的相對地址來訪問。
棧被放置在高地址也是有原因的: 調用函數(加幀)是減 esp 的,函數返回(減幀)是加 esp 的,調用在前,所以棧是向低地址擴展的,放在高地址再合適不過了。
現代操作系統的進程記憶體分佈
認識了 linux 0.01 的記憶體分佈後,再看看現代操作系統的記憶體分佈發生了什麼變化:
首先,linux 0.01 進程的64MB記憶體限制太過時了,現在的程式都有潛力使用到 2GB、3GB 的記憶體空間(每個進程一張頁目錄表),當然,機器有硬傷的話也沒辦法,我的電腦就只有 2GB 的記憶體,想用 3GB 的記憶體是沒指望了。但也不是有4GB記憶體就可以用4GB(32位),因為操作系統還要占個坑呢!現代 linux 中 0xC0000000 以上的 1GB 空間是操作系統專用的,而 linux 0.01 中第1個 64MB 是操作系統的坑,所以別的進程完全占有它們的 64MB,也不用跟操作系統客氣。
其次,linux 0.01只有進程沒有線程,但是現代 linux 有多線程了(linux 的線程其實是個輕量級的進程),一個進程的多個線程之間共用全局變數、堆、打開的文件…… 但棧是不能共用的:棧中各層函數幀代表著一條執行線索,一個線程是一條執行線索,所以每個線程獨占一個棧,而這些棧又都必須在所屬進程的記憶體空間中。
根據以上兩點,進程的記憶體分佈就變成了下麵這個樣子:

再者,如果把動態裝載的動態鏈接庫也考慮進去的話,上面的分佈圖將會更加"破碎"。
如果我們的程式沒有採用多線程的話,一般可以簡單地認為它的記憶體分佈模型是 linux 0.01 的那種。


