
簡介 #概念:消息中間件(消息系統) //消息系統分類: 點對點 消息隊列(peer-to-peer) 發佈/訂閱 消息隊列 消費者在消費時,是通過pull 主動從broker中拉取數據的 簡介 #概念:消息中間件(消息系統) //消息系統分類: 點對點 消息隊列(peer-to-peer) #作用 ...
- 簡介
-
#概念:消息中間件(消息系統)
//消息系統分類:
點對點 消息隊列(peer-to-peer)
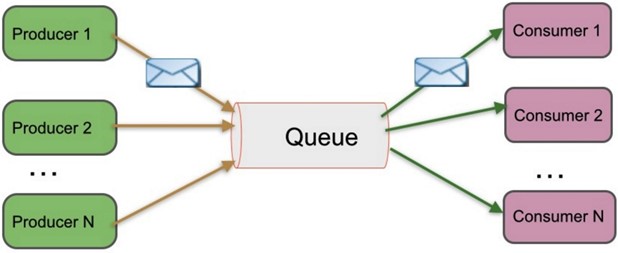
-
- 發佈/訂閱 消息隊列
-
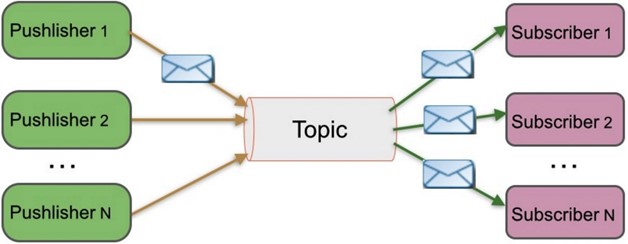
消費者在消費時,是通過pull 主動從broker中拉取數據的
#作用:緩存地帶
#消息系統適用場景
- 解耦 各位系統之間通過消息系統這個統一的介面交換數據,無須瞭解彼此的存在
- 冗餘 部分消息系統具有消息持久化能力,可規避消息處理前丟失的風險
- 擴展 消息系統是統一的數據介面,各系統可獨立擴展
- 峰值處理能力 消息系統可頂住峰值流量,業務系統可根據處理能力從消息系統中獲取並處理對應量的請求
- 可恢復性 系統中部分組件失效並不會影響整個系統,它恢復後仍然可從消息系統中獲取並處理數據
- 非同步通信 在不需要立即處理請求的場景下,可以將請求放入消息系統,合適的時候再處理
#架構
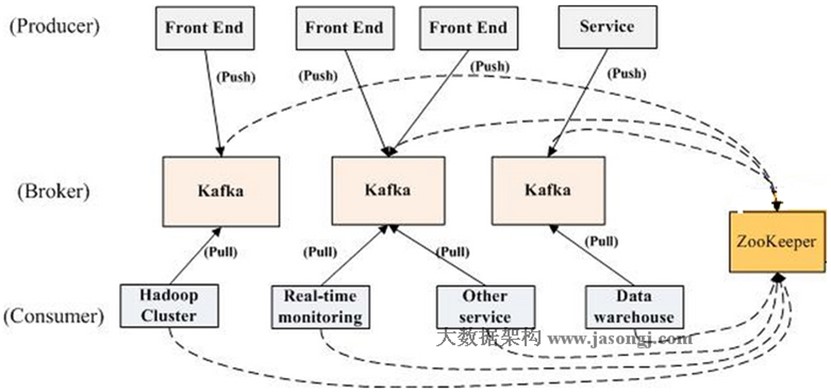
主要分為3部分
生產者(producer),消費者(consumer),kafka(broker)外加一個zookeeper來儲存源數據
Broker 中可以包含多個topic ,topic 是一個邏輯存在的基本運行單元
topic 中可以包含多個partation, partition是真正存儲數據的地方,類似於書架,一個partition是一個強有序的隊列
partition是由segmend組成的
segmend由兩部分組成
一部分是.log結尾的文件,作用存儲kafka的數據
另一部分是.index結尾的文件,作用kafka存儲數據的索引文件
#過程
生產者: 對數據的生產可以使用同步生產也可以使用非同步生產,將生產完成的數據 push到kafka中
kafka: kafka收到生產者生產的數據後,將數據保存到具體的partition中,將該批數據的元數據信息寫到zookeeper上,
消費者: 當消費者要消費數據時,會先從zookeeper中獲取數據偏移量以及元數據,獲取之後,通過主動拉取的形式來消費數據。
#kafka數據生產的格式:
* (key,value)格式的數據:在對數據進行存儲的時候,採用的存儲策略是對key進行hashcode取模來進行具體分配到哪個partiton中進行存儲
* string格式的數據:在對數據進行存儲的時候,採用的策略是輪訓策略。
如果以上的存儲策略都不符合業務生產需求,可以自定義存儲策略 需要集成Partitioner介面
-
目錄結構
註意:演示的所有的命令行操作都在bin目錄下進行
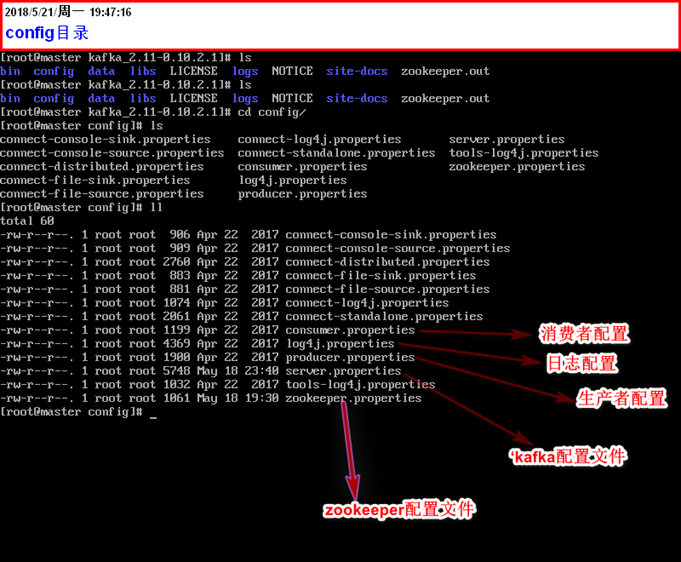
- 配置詳解
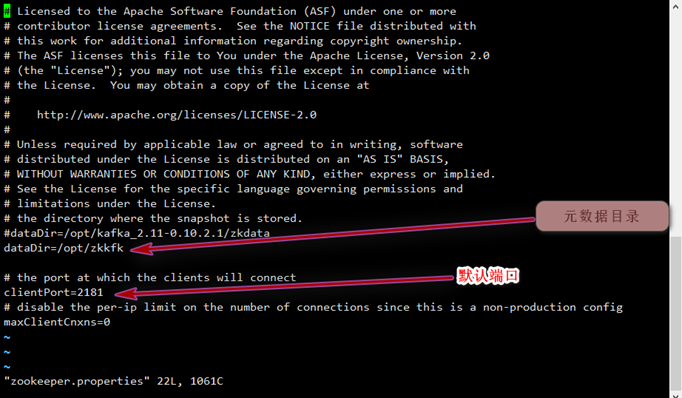
要想啟動,我們只需要修改kafka的配置文件就可以了
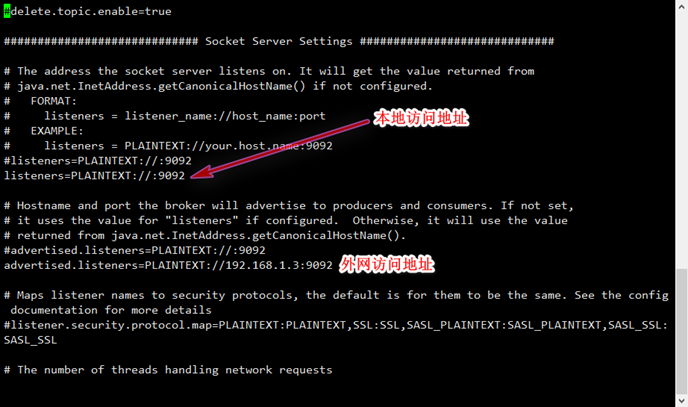
註意
1.外網地址儘量寫ip,別寫主機名,不然可能訪問不到
2.本地地址如果寫ip地址的話,啟動producer,consumer 參數為本地ip
3.本地地址如果寫localhost的話,啟動producer,consumer參數為localhost
預設localhost
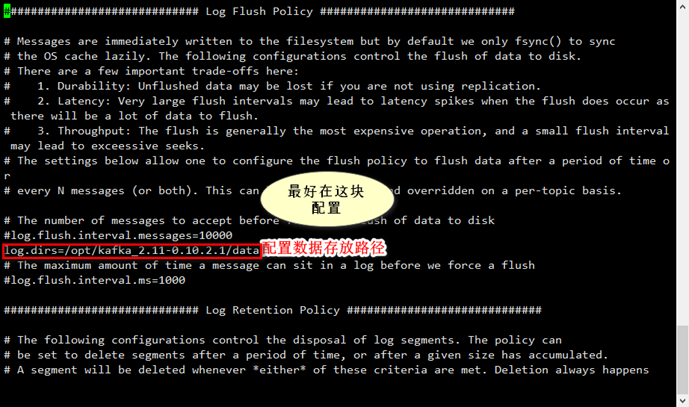
-
服務啟動與查看
由於kafka服務以來與zookeeper所以需要先啟動zookeeper
而zookeeper又需要java 來支持,所以需要大家自行準備jdk
命令
啟動zookeeper服務 ./zookeeper-server-start.sh ../config/zookeeper.properties
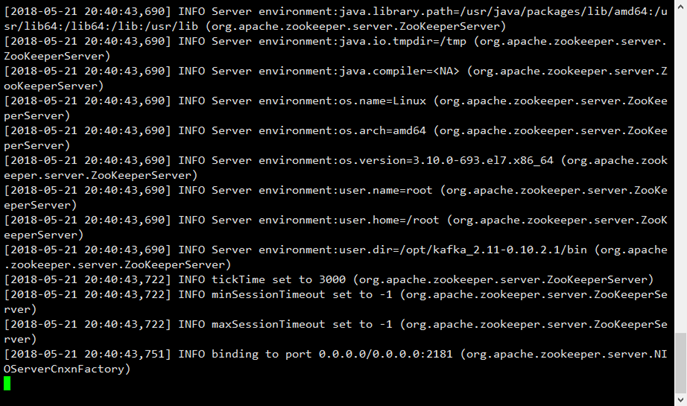
啟動kafka服務./kafka-server-start.sh ../config/server.properties
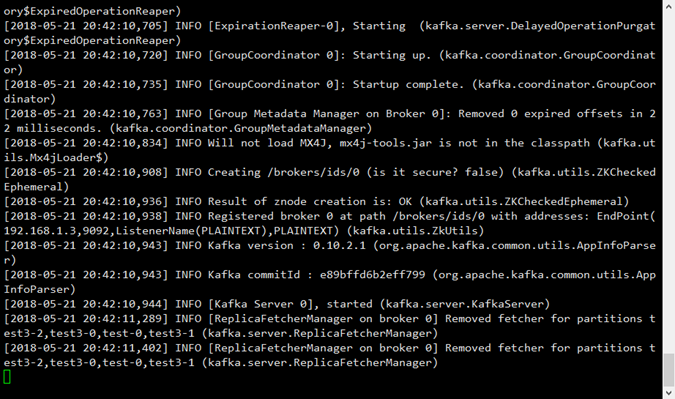
創建topic
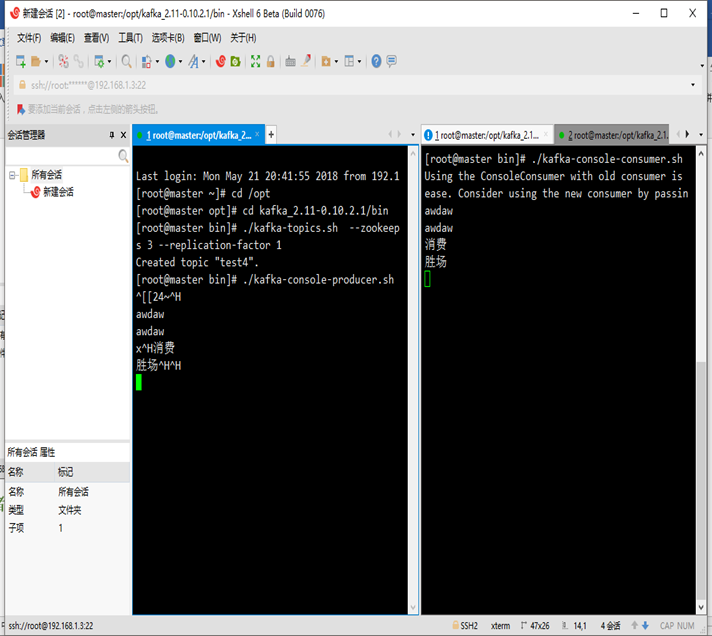
./kafka-topics.sh --zookeeper localhost:2181 --create --topic test4 --partitions 3 --replication-factor 1
--zookeeperzookeepe連接地址:埠
--create 說明要創建
--topic topic名稱
--partitions partitions數量
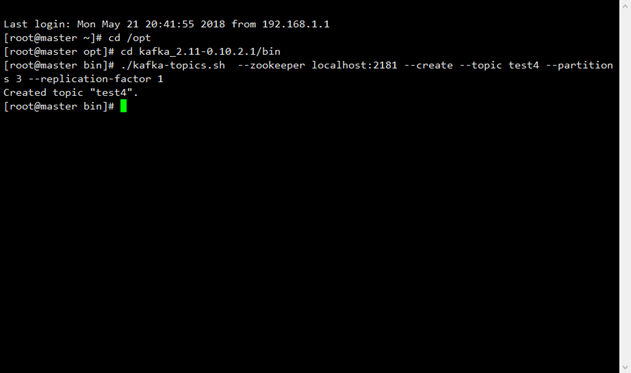
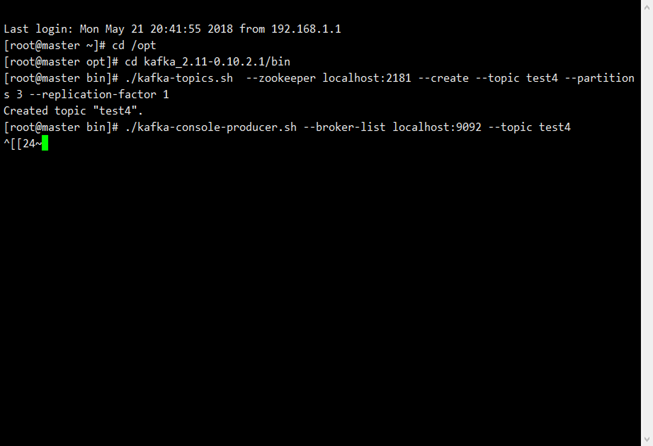
啟動生產者
./kafka-console-producer.sh --broker-list localhost:9092 --topic test3
由於生產者並不依賴於zookeeper,但是生產者需要知道寫入數據到那個broker中的
又因為topic 是運行的基本單元,因此需要指定topic以及broker所在地址
啟動消費者
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test3
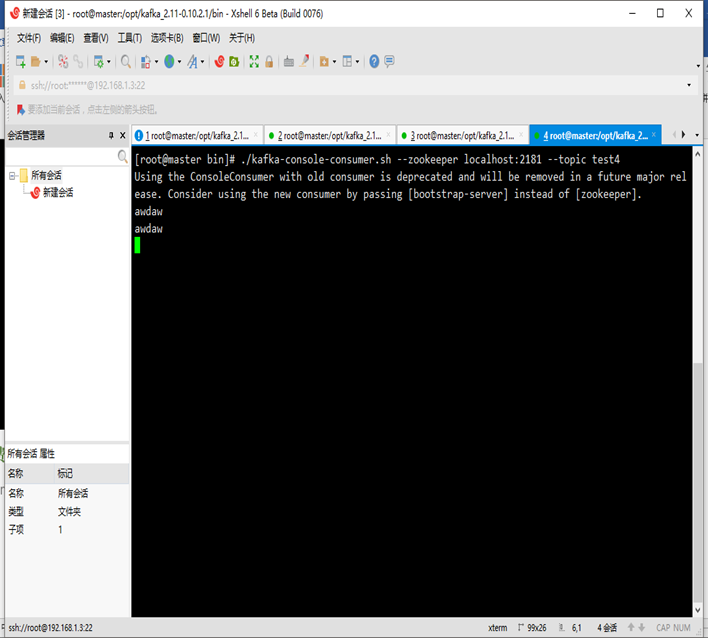
在生產者發送數據 可以看到消費者已經在消費
 :
:


