
《深入理解電腦系統》,這本書,我多次想要好好完整的讀一遍,每次都是沒有堅持下去,但是作為一個開發者,自己想要成為為數不多的大牛之一,所以打算這次把這本書完整的好好讀一遍,並整理為相關的博客! 書的開頭說了一句話:電腦系統是由硬體和系統軟體組成,他們共同工作來運行應用程式。我們通常接觸更多的是應用 ...
《深入理解電腦系統》,這本書,我多次想要好好完整的讀一遍,每次都是沒有堅持下去,但是作為一個開發者,自己想要成為為數不多的大牛之一,所以打算這次把這本書完整的好好讀一遍,並整理為相關的博客!
書的開頭說了一句話:電腦系統是由硬體和系統軟體組成,他們共同工作來運行應用程式。
我們通常接觸更多的是應用程式級別的,很少關註系統以及系統和硬體的交互,但是如果自己能完全理解電腦系統以及它對應用程式的影響,那將會讓我們在軟體開發的路上走的更遠,也同時可以避免很多問題的發生。
拿最簡單的hello.c 程式來說,我們看到的代碼文件內容是:
#include <stdio.h> int main() { printf("hello,world\n"); return 0; }
但是對電腦來說其實就是由0和1組成的位(比特)序列,8個位組成一組,成為位元組。
C程式的編譯過程
通常我們寫完C程式的代碼,都會對程式進行編譯,將代碼文件編譯成可執行程式,也就是我們在windows上通常看到的.exe文件,在Linux系統上我們通常通過gcc 來將c代碼進行編譯,其實當我們通過gcc 編譯的時候,執行了四個階段:預處理階段,編譯階段,彙編階段,鏈接階段
執行這四個階段的程式為:預處理器,編譯器,彙編器,鏈接器,一起構成了編譯系統
如下圖是編譯的過程表示:

預處理階段:其實這個類似python中的import導入,將你要導入的代碼文件放到這個文件中,而在C語言中,這裡還是以hello.c 為例子,第一行的#include <stdio.h> 會告訴預處理器(cpp)讀取系統的頭文件中stdio.h的內容,並把它插入到程式文本中,結果是得到了另外一個C程式,生成的文件是以.i結尾
編譯階段:編譯器(ccl) 將hello.c 翻譯成hello.s ,成為一個彙編語言程式
彙編階段:彙編器(as)將hello.s 翻譯成機器指令,把這些指令打包成一個可重定位目標程式的格式,並將結果保存在hello.o中,hello.o文件其實已經是一個二進位文件。
鏈接階段: 我們通常在代碼中都會調用到標準庫中的一些函數,就像我們hello.c代碼中我們調用了printf函數,其實printf函數存在於一個名為printf.o 的單獨預編譯好的目標文件中,連接器ld 其實就是講這個文件合併到我們的hello.o程式中。最終得到我們編譯好的hello文件中或hello.exe 文件中,這就成了我們通常看到的可執行文件
瞭解這個編譯過程對我們寫代碼來說的好處:
- 優化程式性能
- 理解鏈接時出現的錯誤
- 避免安全漏洞
系統硬體的組成
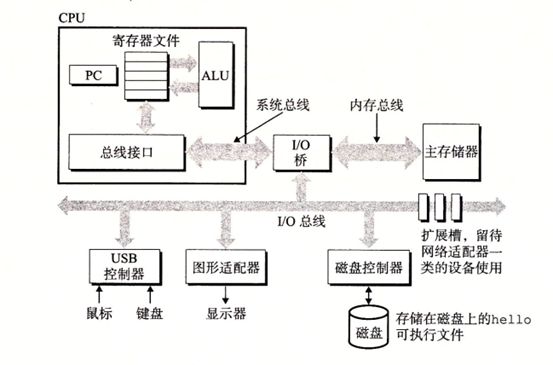
匯流排
我們從上圖可以看出,整個系統是通過各種匯流排在連接,包括了:I/O匯流排,記憶體匯流排,系統匯流排
通常匯流排被設計成傳送定長的位元組塊,也就是字(word),現在大多數及其的字長要麼是4個位元組(32位),要麼是8個位元組(64位),當然64為居多。
I/O設備
這個我們就比較熟悉了,主要就是用於系統和外部進行交互的,入滑鼠鍵盤,顯示器等
每個I/O設備通過一個控制器或適配器與I/O 匯流排相連。
控制器和適配器的區別:就是封裝方式,控制器是主板上的晶元組,而適配器是一個插在主板插槽上的卡,如獨立顯卡和音效卡等
主存
主存是一組動態隨機存儲器DRAM 晶元組成
主存是一個臨時存儲設備,用來存放程式和程式處理的數據
處理器
CPU 是解釋或執行存儲在主存中指令的引擎
處理器的核心是一個大小為一個字的存儲設備或者寄存器,稱為程式計數器(PC)
寄存器文件是一個小的存儲設備,由一些單個字長的寄存器組成,每個寄存器都有唯一的名字,算數/邏輯單元(ALU)計算新的數據和地址。CPU 可能執行的操作:
載入: 從主存複製一個位元組或者一個字到寄存器,以覆蓋寄存器原來的值
存儲: 從寄存器賦值一個位元組或者一個字到主存的某個位置,以覆蓋這個位置原來的內容
操作: 把兩個寄存器的內容複製到ALU,ALU對這兩個字做算數運算,並將結果放到一個寄存器中,覆蓋該寄存器中原來的值
跳轉:從指令本身中抽取一個字,並將這個字複製到程式計數器PC中,以覆蓋PC中原來的值
上面大致理解了系統的各個組成部分,這次在回頭看hello程式運行時在各個組件中傳遞過程
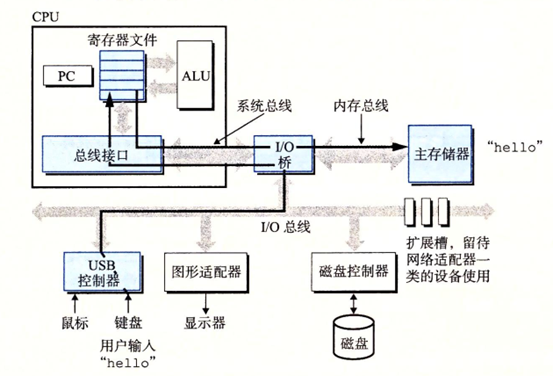
當我們開始通過鍵盤輸入hello命令,程式就字元被逐一讀到寄存器,然後放到記憶體中
回車之後系統將磁碟上我們的程式文件載入到主存中,然後處理器就會開始執行程式中的機器指令,並最終在顯示器顯示hello world
高速緩存的重要性
其實通過上面也看到了系統花費了大量的事件在各個組件之間拷貝來拷貝去,其實這些拷貝也是一種開銷
並且在不同設備上運行的速度也是相差非常大,一般來說較大的存儲設備要比較小的存儲設備運行的慢,但是快速設備的造價會高很多比低速設備,這裡就誕生了告訴緩存存儲器cache memory
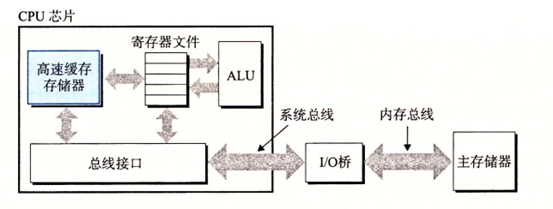
現在的處理器一般有三級高速緩存:L1,L2,L3, 當然可能更多
而這種高速緩存用的是一種叫做靜態隨機訪問存儲器(SRAM)的硬體技術實現的
這樣就有了下麵這個存儲設備的層次結構:

存儲器層次結構的主要思想是上一層的存儲器作為低一層存儲器的緩存
操作系統
當我們這會在回頭來看操作系統,其實操作系統就是應用程式和硬體之間的中間層,應用程式通過操作系統來對硬體進行操作

操作系統的作用:防止硬體被失控的程式濫用;嚮應用程式提供一種機制用於操作硬體
而實現這兩個功能是通過幾個基本的抽象概念來實現:進程,虛擬記憶體和文件
文件是對I/O設備的抽象,虛擬記憶體是對主存和磁碟I/O 設備的抽象,進程則是對處理器、主存和IO設備的抽象
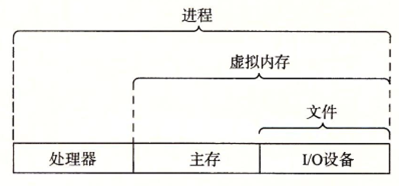
這裡有幾個關鍵詞的概念需要理解:
進程:進程是操作系統對一個正在運行的程式的一種抽象。
併發運行:一個進程的指令和另外一個進程指令是交錯執行
操作系統實現叫做執行的機製成為上下文切換
操作系統保持跟蹤進程運行所需要的所有狀態信息,就是上下文
其實我們在shell命令下執行我們的hello程式就是個併發的場景,這裡有兩個進程:shell進程和hello進程,而執行的過程可以通過如下圖表示:
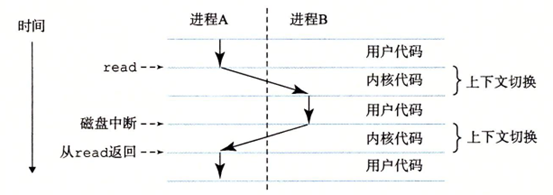
這裡也要知道從一個進程到另外一個進程是有操作系統內核管理的,內核代碼是操作系統代碼常駐主存的部分
註意:內核不是一個獨立的進程。它是系統管理全部進程所用代碼和數據結構的集合
線程:一個進程通常可以由多個線程的執行單元組成,每個線程都運行在進程的上下文中,並共用同樣的代碼和全局數據
虛擬記憶體:虛擬記憶體是一個抽象概念,為每個進程提供了一個假象,好像每個進程都在獨占的使用主存,每個進程看到的記憶體都是一致的,稱為虛擬地址空間。下圖是Linux的虛擬地址空間,地址是從下往上增大
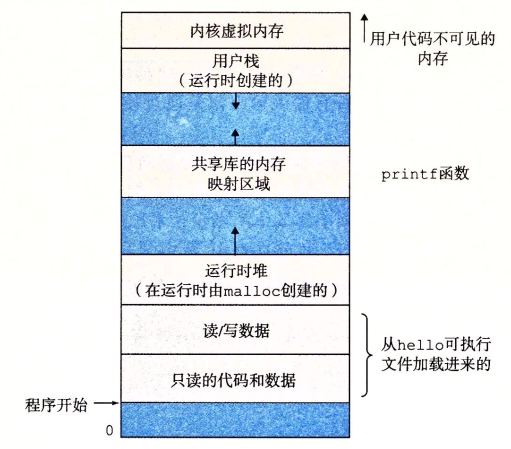
這裡先簡單的對著幾個概念進行理解:
堆:代碼和數據區在進程一開始運行就被指定了大小。同時堆可以在運行時動態的擴展和收縮
共用庫: 在地址空間的中間部分是一塊用來存放C標準庫數學庫這樣的共用庫代碼和數據區域
棧:位於用戶虛擬地址空間頂部的是用戶棧,編譯器用它實現函數的調用,同樣棧在程式執行期間也可以動態的擴展和收縮
如:當我們執行函數時,棧就會增長,一個函數返回時,棧就會收縮
內核虛擬記憶體:地址空間的頂部區域是為內核保留的,不允許程式血禍者調用內核定義的函數,必須由內核來執行這些操作
Amdahl 定律
該定律的主要思想:當我們對系統的某個部分加速時,其對系統整體性能的影響取決於該部分的重要性和加速度
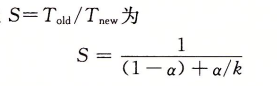
書中有個例子非常貼切,系統的某個部分的耗時比例是60%,也就是a = 0.6 其加速比例因數為3 k=3,我們可以獲得的加速比為:
1/[0.4+0.6/3] = 1.67倍,即使對著一個部分做了重大概念,但獲得系統加速比卻明顯小於這部分的加速比,所以想要顯著加速整個系統,必須提升全系統中相當大的部分的速度


