
上周公司對所有員工封閉培訓了一個星期,期間沒收手機,基本上博客的更新都停止了,儘管培訓時間不長,但還是有些收穫,不僅來自於培訓講師的,更多的是發現自己與別人的不足,一個優秀的人不僅僅是自己專業那塊的精通,自己還有很多內功和外功需要修煉,人生很長,拼的是堅持。培訓回來了就開始馬不停蹄的複習自己之前學的 ...
上周公司對所有員工封閉培訓了一個星期,期間沒收手機,基本上博客的更新都停止了,儘管培訓時間不長,但還是有些收穫,不僅來自於培訓講師的,更多的是發現自己與別人的不足,一個優秀的人不僅僅是自己專業那塊的精通,自己還有很多內功和外功需要修煉,人生很長,拼的是堅持。培訓回來了就開始馬不停蹄的複習自己之前學的東西,業精於勤荒於嬉是非常有道理的,不希望自己中間的斷檔就將博客給徹底荒廢了。上一篇復盤的是選擇行和列,這是利用python操作數據的基礎和根本。本文將總結基本的算術運算規則。
算術運算
對於兩個對象進行加減乘除的算數運算時,如果兩個對象有不同的索引對,那麼運算結果的索引就是該索引對的並集。而結果集索引對應的值是兩個對象相同索引對應的值相加減乘除,不同的索引對應的值統一為NaN。比方說張三有梨子3個,蘋果2個;李四有橘子1個,獼猴桃3個,蘋果1個,梨子5個。那麼張三和李四加起來的結果就是梨子8個,蘋果3個,橘子未知,獼猴桃未知。這裡的水果名即為索引,兩者相同索引對應的值會相加,而不同索引對應的值將為NaN。
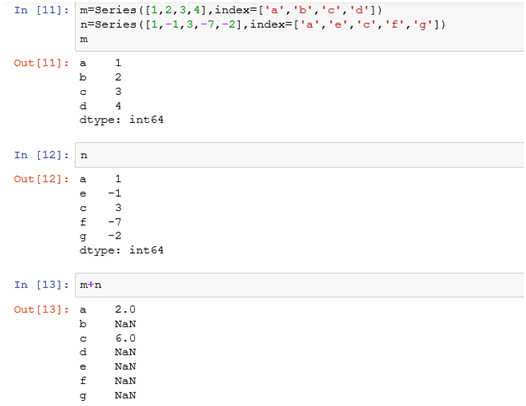
1.1 Series之間的運算
示例:
1.2 DataFrame之間的運算
示例:
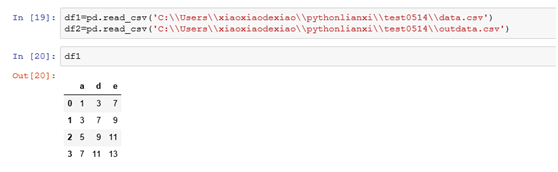

從上述例子上看可以發現DataFrame之間運算時,是行索引和列索引一起進行對齊操作,運算後的結果集的行索引是兩者行索引的並集,結果集的列索引是兩者列索引的並集。而行列對應的數值是df1和df2中相同行索引和相同列索引定位到的那個數值相加,如果兩者的行索引或者列索引不相同數值將填充為NaN.
1.3 DataFrame與Series之間的運算
示例:


從以上示例可以看出兩個相減時是從df1中匹配m中的列索引,匹配上了的就將df1的每一行都減去對應m的值。比如m中a,d是與df1相同的,那麼df1的a,d兩列的每一行都要減去m的a,d兩個值。df1其他沒匹配上的填充為NaN。
如果是按照行匹配,每列來運算,則利用軸標記來指定。
示例:
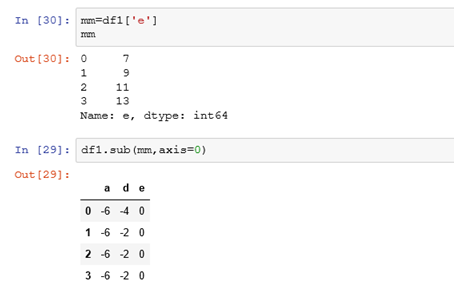
axis=0表示希望匹配的軸是行,按照行來匹配,減去每列的數值。


