
關於C基礎開發框架零件寫的差不多了,這裡再添加一個csv文件解析庫. 後面有機會 再融進去跨平臺的網路開發庫.和更加方便的圖形庫.
引言
最經關於基礎C開發框架基本都搭建好了. 在研究githup,準備傳上去. 可惜的是兩會連githup 都登陸不進去.
三觀很正的我也覺得, 這樣不好. 雙向標準, 共x黨不是一個代表窮苦大眾的黨.當然我也恆感謝黨國, 給我選舉權,每次都是
人大代表幫我投了,好人. 謝謝了!
後面可能沒辦法, 繼續上傳到 csdn 上. 會把使用手冊,註意事項寫清楚.這個框架,適合新手參考吧.大多庫還是很複雜的
內力不足看多了容易走火入魔.我這裡提供都比較淺顯易懂. 適合使用. 感受簡單,高效,能用,實在的設計.
殺死那個石家莊人 http://music.163.com/#/song?id=386844
前言
同樣先介紹一寫,這節要將的精華.首先說一下大白文,將讀取文件的內容直到全部.
/* * 簡單的文件幫助類,會讀取完畢這個文件內容返回,失敗返回NULL. * 需要事後使用 tstring_destroy(&ret); 銷毀這個字元串對象 * path : 文件路徑 * ret : 返回創建好的字元串內容,返回NULL表示讀取失敗 */ tstring file_malloc_readend(const char* path) { int c; tstring tstr; FILE* txt = fopen(path, "r"); if (NULL == txt) { SL_NOTICE("fopen r path = '%s' error!", path); return NULL; } //這裡創建文件對象,創建失敗直接返回 if ((tstr = tstring_create(NULL)) == NULL) { fclose(txt); return NULL; } //這裡讀取文本內容 while ((c = fgetc(txt))!=EOF) if (_RT_OK != tstring_append(tstr, c)){ //出錯了就直接銷毀已經存在的內容 tstring_destroy(&tstr); break; } fclose(txt);//很重要創建了就要釋放,否則會出現隱藏的句柄bug return tstr; }
一個細節是 加了字元串數據 返回判斷,如果記憶體分配失敗直接返回.
還有一個值得學習的細節是 只能在堆上分配的記憶體結構
/* * 這裡是一個解析 csv 文件的 簡單解析器. * 它能夠幫助我們切分文件內容,保存在數組中. */ struct sccsv { //記憶體只能在堆上 int rlen; //數據行數,索引[0, rlen) int clen; //數據列數,索引[0, clen) const char* data[]; //保存數據一維數組,希望他是二維的 rlen*clen }; typedef struct sccsv* sccsv_t;
上面是新語法, 以前的做法是data[0], data[1]等. 在結構體中聲明可變數組.這種結構是不完全結構無法 直接 struct sccsv 在堆上聲明.
這裡基本上就是我們說的. 再扯一點當你使用inline語法在C中的時候. 一種是static inline 內聯.一種如下內聯聲明
/* * 獲取某個位置的對象內容,這個函數 推薦聲明為內聯的, window上不支持 * csv : sccsv_t 對象, new返回的 * ri : 查找的行索引 [0, csv->rlen) * ci : 查找的列索引 [0, csv->clen) * : 返回這一項中內容,後面可以用 atoi, atof, str_dup 等處理了... */ extern inline const char* sccsv_get(sccsv_t csv, int ri, int ci);
到這裡基本C基礎普及就這樣了,等一下分析正文.
正文
那就開始正題描述吧.首先什麼是csv文件. 對比顯差異.預覽圖
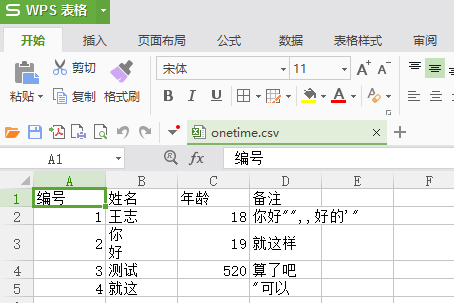
再看看實際的編碼圖
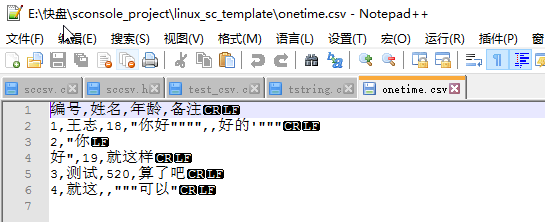
通過這個看應該就知道csv文件的編碼規則了吧. 總結如下
1.用 , 分割
2.如果出現 , " 這種特殊字元, 會被用 "" 包裹起來, 並且 "" 表示一個 " 號
3.每行用\r\n結束
這樣語法問題都已經解決了.
再分析我們今天的 介面內容 sccsv.h
#ifndef _H_SCCSV #define _H_SCCSV /* * 這裡是一個解析 csv 文件的 簡單解析器. * 它能夠幫助我們切分文件內容,保存在數組中. */ struct sccsv { //記憶體只能在堆上 int rlen; //數據行數,索引[0, rlen) int clen; //數據列數,索引[0, clen) const char* data[]; //保存數據一維數組,希望他是二維的 rlen*clen }; typedef struct sccsv* sccsv_t; /* * 從文件中構建csv對象, 最後需要調用 sccsv_die 釋放 * path : csv文件內容 * : 返回構建好的 sccsv_t 對象 */ extern sccsv_t sccsv_new(const char* path); /* * 釋放由sccsv_new構建的對象 * pcsv : 由sccsv_new 返回對象 */ extern void sccsv_die(sccsv_t* pcsv); /* * 獲取某個位置的對象內容,這個函數 推薦聲明為內聯的, window上不支持 * csv : sccsv_t 對象, new返回的 * ri : 查找的行索引 [0, csv->rlen) * ci : 查找的列索引 [0, csv->clen) * : 返回這一項中內容,後面可以用 atoi, atof, str_dup 等處理了... */ extern inline const char* sccsv_get(sccsv_t csv, int ri, int ci); #endif // !_H_SCCSV
構建銷毀獲得指定內容. 很容易理解.
現在我們展示一下運行的結果, 測試代碼是
#include <schead.h> #include <sclog.h> #include <sccsv.h> #define _STR_PATH "onetime.csv" // 解析 csv文件內容 int main(int argc, char* argv[]) { sccsv_t csv; int i, j; int rlen, clen; INIT_PAUSE(); sl_start(); // 這裡得到 csv 對象 csv = sccsv_new(_STR_PATH); if (NULL == csv) CERR_EXIT("open " _STR_PATH " is error!"); //這裡列印數據 rlen = csv->rlen; clen = csv->clen; for (i = 0; i < rlen; ++i) { for (j = 0; j < clen; ++j) { printf("<%d, %d> => [%s]\n", i, j, sccsv_get(csv, i, j)); } } //開心 測試圓滿成功 sccsv_die(&csv); return 0; }
最後運行的預覽圖

運行起來可能複雜一點點, 這裡摘錄一下編譯圖,還是看代碼吧,你自己找其中關於 test_csv.c 文件的編譯過程吧


C = gcc DEBUG = -g -Wall -D_DEBUG #指定pthread線程庫 LIB = -lpthread -lm #指定一些目錄 DIR = -I./module/schead/include -I./module/struct/include #具體運行函數 RUN = $(CC) $(DEBUG) -o $@ $^ $(LIB) $(DIR) RUNO = $(CC) $(DEBUG) -c -o $@ $^ $(DIR) # 主要生成的產品 all:test_cjson_write.out test_csjon.out test_csv.out test_json_read.out test_log.out\ test_scconf.out test_tstring.out #挨個生產的產品 test_cjson_write.out:test_cjson_write.o schead.o sclog.o tstring.o cjson.o $(RUN) test_csjon.out:test_csjon.o schead.o sclog.o tstring.o cjson.o $(RUN) test_csv.out:test_csv.o schead.o sclog.o sccsv.o tstring.o $(RUN) test_json_read.out:test_json_read.o schead.o sclog.o sccsv.o tstring.o cjson.o $(RUN) test_log.out:test_log.o schead.o sclog.o $(RUN) test_scconf.out:test_scconf.o schead.o scconf.o tree.o tstring.o sclog.o $(RUN) test_tstring.out:test_tstring.o tstring.o sclog.o schead.o $(RUN) #產品主要的待鏈接文件 test_cjson_write.o:./main/test_cjson_write.c $(RUNO) test_csjon.o:./main/test_csjon.c $(RUNO) test_csv.o:./main/test_csv.c $(RUNO) test_json_read.o:./main/test_json_read.c $(RUNO) test_log.o:./main/test_log.c $(RUNO) -std=c99 test_scconf.o:./main/test_scconf.c $(RUNO) test_tstring.o:./main/test_tstring.c $(RUNO) #工具集機械碼,待別人鏈接 schead.o:./module/schead/schead.c $(RUNO) sclog.o:./module/schead/sclog.c $(RUNO) sccsv.o:./module/schead/sccsv.c $(RUNO) tstring.o:./module/struct/tstring.c $(RUNO) cjson.o:./module/schead/cjson.c $(RUNO) scconf.o:./module/schead/scconf.c $(RUNO) tree.o:./module/struct/tree.c $(RUNO) #刪除命令 clean: rm -rf *.i *.s *.o *.out __* log ; ls -hl .PHONY:cleanView Code
最後展示 實現的代碼
#include <schead.h> #include <sccsv.h> #include <sclog.h> #include <tstring.h> //從文件中讀取 csv文件內容 char* __get_csv(FILE* txt, int* prl, int* pcl) { int c, n; int cl = 0, rl = 0; TSTRING_CREATE(ts); while((c=fgetc(txt))!=EOF){ if('"' == c){ //處理這裡數據 while((c=fgetc(txt))!=EOF){ if('"' == c) { if((n=fgetc(txt)) == EOF) { //判斷下一個字元 SL_WARNING("The CSV file is invalid one!"); free(ts.str); return NULL; } if(n != '"'){ //有效字元再次壓入棧 ungetc(n, txt); break; } } //都是合法字元 保存起來 if (_RT_OK != tstring_append(&ts, c)) { free(ts.str); return NULL; } } //繼續判斷,只有是c == '"' 才會下來,否則都是錯的 if('"' != c){ SL_WARNING("The CSV file is invalid two!"); free(ts.str); return NULL; } } else if(',' == c){ if (_RT_OK != tstring_append(&ts, '\0')) { free(ts.str); return NULL; } ++cl; } else if('\r' == c) continue; else if('\n' == c){ if (_RT_OK != tstring_append(&ts, '\0')) { free(ts.str); return NULL; } ++cl; ++rl; } else {//其它所有情況只添加數據就可以了 if (_RT_OK != tstring_append(&ts, c)) { free(ts.str); return NULL; } } } if(cl % rl){ //檢測 , 號是個數是否正常 SL_WARNING("now csv file is illegal! need check!"); return NULL; } // 返回最終內容 *prl = rl; *pcl = cl; return ts.str; } // 將 __get_csv 得到的數據重新構建返回, 執行這個函數認為語法檢測都正確了 sccsv_t __get_csv_new(const char* cstr, int rl, int cl) { int i = 0; sccsv_t csv = malloc(sizeof(struct sccsv) + sizeof(char*)*cl); if(NULL == csv){ SL_FATAL("malloc is error one !"); return NULL; } // 這裡開始構建內容了 csv->rlen = rl; csv->clen = cl / rl; do { csv->data[i] = cstr; while(*cstr++) //找到下一個位置處 ; }while(++i<cl); return csv; } /* * 從文件中構建csv對象, 最後需要調用 sccsv_die 釋放 * path : csv文件內容 * : 返回構建好的 sccsv_t 對象 */ sccsv_t sccsv_new(const char* path) { FILE* txt; char* cstr; int rl, cl; DEBUG_CODE({ if(!path || !*path){ SL_WARNING("params is check !path || !*path ."); return NULL; } }); // 打開文件內容 if((txt=fopen(path, "r")) == NULL){ SL_WARNING("fopen %s r is error!", path); return NULL; } // 如果解析 csv 文件內容失敗直接返回 cstr = __get_csv(txt, &rl, &cl); fclose(txt); // 返回最終結果 return cstr ? __get_csv_new(cstr, rl, cl) : NULL; } /* * 釋放由sccsv_new構建的對象 * pcsv : 由sccsv_new 返回對象 */ void sccsv_die(sccsv_t* pcsv) { if (pcsv && *pcsv) { // 這裡 開始釋放 free(*pcsv); *pcsv = NULL; } } /* * 獲取某個位置的對象內容 * csv : sccsv_t 對象, new返回的 * ri : 查找的行索引 [0, csv->rlen) * ci : 查找的列索引 [0, csv->clen) * : 返回這一項中內容,後面可以用 atoi, atof, str_dup 等處理了... */ inline const char* sccsv_get(sccsv_t csv, int ri, int ci) { DEBUG_CODE({ if(!csv || ri<0 || ri>=csv->rlen || ci<0 || ci >= csv->clen){ SL_WARNING("params is csv:%p, ri:%d, ci:%d.", csv, ri, ci); return NULL; } }); // 返回最終結果 return csv->data[ri*csv->clen + ci]; }
到這裡原本要結束了,但是再扯一點,上面採用的記憶體模型是整體記憶體模型, 一共分配兩次,一次為了所有字元.一次
為了保存分割串內容. 可以細細品味上面 new那段代碼,還是很有意思的.
到這裡簡單的基礎庫的各個細節都已經實現完畢. 下一次會詳細介紹怎麼使用這個框架.再試試githup. 實在
不行再採用菜一點的做法.
後記
錯誤是難免的,歡迎吐槽.... 以科幻的圖結束吧 -------------------------------未來是不可知的---------------------------------



