目的 確定Oracle DB中可能發生的故障類型 說明優化實例恢復的方法 說明檢查點,重做日誌文件和歸檔日誌文件的重要性 配置快速恢復區 配置ARCHIVEDLOG模式 資料庫管理員的部分職責 儘量避免資料庫出現故障 延長平均故障間隔時間(MTBF) 通過冗餘方式保護關鍵組件 -Real Appli ...
目的
確定Oracle DB中可能發生的故障類型
說明優化實例恢復的方法
說明檢查點,重做日誌文件和歸檔日誌文件的重要性
配置快速恢復區
配置ARCHIVEDLOG模式
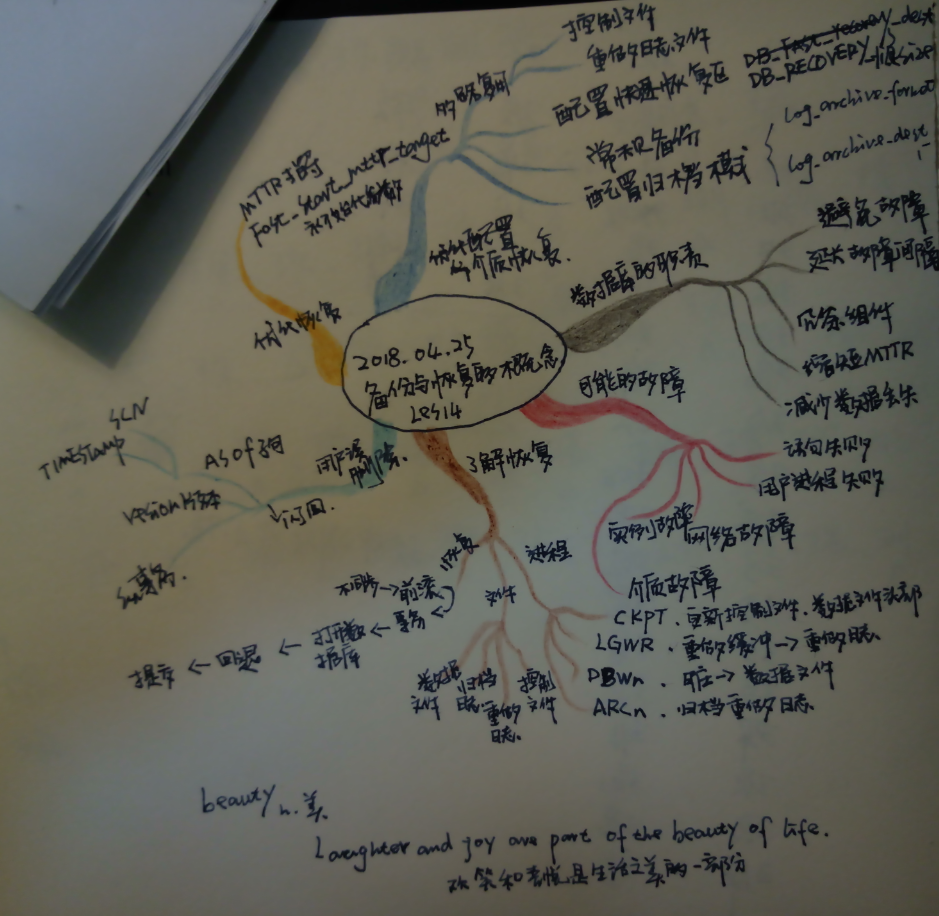
資料庫管理員的部分職責
儘量避免資料庫出現故障
延長平均故障間隔時間(MTBF)
通過冗餘方式保護關鍵組件
-Real Application Cluster
-Oracle Streams
-Oracle Data Guard
縮短平均恢復時間(MTTR)
最大程度地減少數據丟失
-歸檔日誌文件
-閃回技術
-備用資料庫和Oracle Data Guard
故障類別
語句失敗:單個資料庫操作(選擇,插入,更新或刪除)失敗
用戶進程失敗:單個資料庫會話失敗
網路故障:與資料庫的連接斷開
用戶錯誤:用戶成功完成了操作,但是操作不正確(刪除了表,或輸入了錯誤數據)
實例故障:資料庫實例意外關閉
介質故障:丟失了資料庫操作所需的任何文件(文件已刪除或磁碟出現故障)
許多情況下,語句失敗是由設計決定的,且是想要的結果。如安全策略和限額規則通常是提前制定的。
用戶進程失敗中進行恢復時不需要DBA進行干預,進程監視器(PMON)後臺進程定期輪詢伺服器進程。如果PMON發現某個伺服器進程的用戶異常,PMON會對此事務進行恢復,回退未提交的更改和解除失敗會話持有的任何鎖。資料庫管理員需觀察變化趨勢,如有多個或大量用戶進程失敗,則可能對用戶進行培訓(學習如何註銷程式,而不是僅僅終止程式),還有可能存儲網路或應用程式問題。
網路故障
網路故障的最佳解決方法是為網路連接提供冗餘路徑。通過備份監聽程式,網路連接和網路介面卡可降低出現網路故障的機率,從而避免影響系統可用性。
![]() 用戶可能會無意中刪除或修改了數據。
-如果尚未提交或退出其程式,則只需回退即可。
-如果配置了對重做信息進行歸檔,則在刪除歸檔文件之前會一直保留重做信息。Oracle LogMiner工具進行恢復
-通過將表閃回到刪除前的狀態,用戶刪除表後可從回收站中恢復表。
-如果清除了回收站,或者用戶使用PURGE選項刪除了表,那麼在資料庫配置正確的情況下,仍然可通過使用時間恢復(PITR)來恢復刪除的表。
用戶可能會無意中刪除或修改了數據。
-如果尚未提交或退出其程式,則只需回退即可。
-如果配置了對重做信息進行歸檔,則在刪除歸檔文件之前會一直保留重做信息。Oracle LogMiner工具進行恢復
-通過將表閃回到刪除前的狀態,用戶刪除表後可從回收站中恢復表。
-如果清除了回收站,或者用戶使用PURGE選項刪除了表,那麼在資料庫配置正確的情況下,仍然可通過使用時間恢復(PITR)來恢復刪除的表。
![]() 該技術由一組功能組成,支持查看數據的以前狀態和來回讀取數據,而無需從備份還原資料庫。可以協助用戶執行錯誤分析和恢復。
功能分析錯誤:
該技術由一組功能組成,支持查看數據的以前狀態和來回讀取數據,而無需從備份還原資料庫。可以協助用戶執行錯誤分析和恢復。
功能分析錯誤:
-閃回查詢,查看在過去某個時間點存在的已提交的歷史數據。帶有AS OF子句的SELECT 命令通過時間戳或SCN引用過去的某一個時間。
SELECT ... FROM <tab> AS OF SCN SCN號;
SELECT ... FROM <tab> AS OF TIMESTAMP TO_TIMESTAMP('','YYYY-MM-DD HH24:MI:SS');
11:46:45 SQL> select to_char(current_scn) from v$database;
TO_CHAR(CURRENT_SCN)
--------------------------------------------------------------------------------
6533021729470
11:47:25 SQL> select to_char(sysdate,'YYYY-MM-DD HH24:MI:SS') from dual;
TO_CHAR(SYSDATE,'YYYY-MM-DDHH24:MI:SS'
--------------------------------------
2018-04-16 11:48:04
11:48:04 SQL> select min(salary) from emp;
MIN(SALARY)
-----------
2090
11:48:57 SQL> update emp set salary=salary+1 where salary=2090;
已更新 2 個資料列.
11:49:35 SQL> commit;
確認完成.
11:49:38 SQL> select min(salary) from emp;
MIN(SALARY)
-----------
2091
11:50:06 SQL> select min(salary) from emp as of scn 6533021729470;
MIN(SALARY)
-----------
2090
11:50:13 SQL> select min(salary) from emp as of timestamp to_timestamp('2018-04-16 11:00:00','YYYY-MM-DD HH24:MI:SS');
MIN(SALARY)
-----------
2090
-閃回版本查詢,查看在特定時間間隔內提交的歷史數據。使用SELECT命令的VERSIONS BETWEEN子句(出於性能方面的考慮,使用了現有索引)。
VERSIONS {BETWEEN {SCN | TIMESTAMP} start AND end}
SELECT versions_startscn,
versions_starttime,
versions_endscn,
versions_endtime,
versions_xid,
versions_operation
FROM emp
VERSIONS BETWEEN TIMESTAMP TO_TIMESTAMP ('2018-04-16 14:10:08', 'YYYY-MM-DD HH24:MI:SS') AND TO_TIMESTAMP ('2018-04-16 14:26:08', 'YYYY-MM-DD HH24:MI:SS');
SELECT versions_xid XID,
versions_startscn START_SCN,
versions_endscn END_SCN,
versions_operation OPERATION,
salary
FROM emp VERSIONS BETWEEN SCN MINVALUE AND MAXVALUE;
-閃回事務處理查詢,查看在事務處理級進行的所有資料庫更改。
SELECT xid,
start_scn,
commit_scn,
operation,
table_name,
table_owner
FROM flashback_transaction_query
WHERE table_owner = 'HR'
AND start_timestamp >=
TO_TIMESTAMP ('2018-04-16 11:00:00', 'YYYY-MM-DD HH:MI:SS');
從用戶錯誤中進行恢復的可能的解決方法包括:
-閃回事務處理恢復,回退特定的事務處理及其從屬事務處理。
-閃回表,將一個或多個表讀回到其以前某一時間的內容,而不影響其他資料庫對象。
-閃回刪除,通過將已刪除的表及其從屬對象(如索引和觸發器)從回收站返回到資料庫,撤銷刪除該表的操作。
-閃回資料庫,將資料庫返回到某個過去時間或系統更改號(SCN)。
![]() 瞭解實例恢復:檢查點(CKPT)進程
CKPT負責以下事項:
-使用檢查點信息更新數據文件頭
-使用檢查點信息更新控制文件
-在完全檢查點向DBWn發出信號
瞭解實例恢復:檢查點(CKPT)進程
CKPT負責以下事項:
-使用檢查點信息更新數據文件頭
-使用檢查點信息更新控制文件
-在完全檢查點向DBWn發出信號
![]() 每隔三秒(或更加頻繁),CKPT進程就會在控制文件中存儲一次數據,以記錄DBWn已將那些修改的數據塊從SGA寫到磁碟。這稱為“增量檢查點”。檢查點的用途是標識聯機重做日誌文件進行實例恢復的位置(這個位置稱為“檢查點位置”)。如果發生日誌切換,則CKPT進程還會將此檢查點信息寫入數據文件頭。
存在檢查點是由於下列原因:
-確保記憶體中已修改的數據塊能夠定期寫入到磁碟,這樣在系統或資料庫出現故障時就不會丟失數據
-減少實例恢復所需的時間(只需要處理上一個檢查點之後的聯機重做日誌文件條目,即可進行恢復)
-確保所有已提交的數據在關閉期間會被寫入數據文件
CKPT進程寫入的檢查點信息包括檢查點位置,系統更改號SCN,聯機重做日誌文件中恢復開始的位置,有關日誌的信息等等。
註:CKPT進程不會將數據塊寫入磁碟或重做數據塊寫入聯機重做日誌文件。
瞭解實例恢復:重做日誌文件和日誌寫進程
每隔三秒(或更加頻繁),CKPT進程就會在控制文件中存儲一次數據,以記錄DBWn已將那些修改的數據塊從SGA寫到磁碟。這稱為“增量檢查點”。檢查點的用途是標識聯機重做日誌文件進行實例恢復的位置(這個位置稱為“檢查點位置”)。如果發生日誌切換,則CKPT進程還會將此檢查點信息寫入數據文件頭。
存在檢查點是由於下列原因:
-確保記憶體中已修改的數據塊能夠定期寫入到磁碟,這樣在系統或資料庫出現故障時就不會丟失數據
-減少實例恢復所需的時間(只需要處理上一個檢查點之後的聯機重做日誌文件條目,即可進行恢復)
-確保所有已提交的數據在關閉期間會被寫入數據文件
CKPT進程寫入的檢查點信息包括檢查點位置,系統更改號SCN,聯機重做日誌文件中恢復開始的位置,有關日誌的信息等等。
註:CKPT進程不會將數據塊寫入磁碟或重做數據塊寫入聯機重做日誌文件。
瞭解實例恢復:重做日誌文件和日誌寫進程
![]() 重做日誌文件
-記錄對資料庫進行的更改
-應多路復用以避免文件丟失
日誌寫入進程在下列時間進行寫入
-提交時
-三分之一已滿時
-每隔3秒
-在DBWn寫入之前
-正常關閉之前
重做日誌文件記錄了由於事務處理和Oracle伺服器內部操作而對資料庫所做的更改。(事務處理是邏輯工作單元,由用戶運行的一個或多個SQL語句組成。)重做日誌文件會保護資料庫,避免因斷電,磁碟故障等引起的系統故障導致數據不完整。重做日誌文件應該多路復用,才能確保在出現磁碟故障事件時不丟失其中存儲的信息。
重做日誌由重做日誌文件組成,而重做日誌文件組由重做日誌文件及其多路復用的副本組成。每個相同的副本均稱作該組的一個成員,每個組按數字標識。日誌寫進程(LGWR)將重做記錄從重做日誌緩衝區寫入重做日誌組的所有成員,直至填滿文件或日誌切換操作。然後,切換至下一組文件並執行寫入操作。將以迴圈方式使用重做日誌組。
最佳實踐提示:如果可能,多路復用的重做日誌文件應駐留在不同的磁碟上。
瞭解實例恢復
自動實例恢復或崩潰恢復
-原因是嘗試打開的資料庫中的文件在關閉時不同步
-使用重做日誌組中存儲的信息來同步文件
-涉及到兩個不同的操作
-前滾,將重做日誌更改(已提交的和未提交的)應用到數據文件
-回退,已執行但尚未提交的更改會放回到初始狀態
Oracle DB會自動從實例故障中進行恢復。實例所需要的就是正常啟動。如果Oracle Restart已啟用並且配置為監視該資料庫,則該啟動操作會自動進行。實例會裝載控制文件,然後嘗試打開數據文件。如果實例發現數據文件在關閉期間尚未同步,則會使用重做日誌組中包含的信息將資料庫前滾到關閉時的狀態。然後,將打開資料庫,並回退所有未提交的事務處理。
實例恢復的階段
1.啟動實例(數據文件不同步)
2.前滾(重做)
3.文件中有已提交和未提交的數據
4.打開資料庫
5.回退(還原)
6.文件中只有已提交的數據
重做日誌文件
-記錄對資料庫進行的更改
-應多路復用以避免文件丟失
日誌寫入進程在下列時間進行寫入
-提交時
-三分之一已滿時
-每隔3秒
-在DBWn寫入之前
-正常關閉之前
重做日誌文件記錄了由於事務處理和Oracle伺服器內部操作而對資料庫所做的更改。(事務處理是邏輯工作單元,由用戶運行的一個或多個SQL語句組成。)重做日誌文件會保護資料庫,避免因斷電,磁碟故障等引起的系統故障導致數據不完整。重做日誌文件應該多路復用,才能確保在出現磁碟故障事件時不丟失其中存儲的信息。
重做日誌由重做日誌文件組成,而重做日誌文件組由重做日誌文件及其多路復用的副本組成。每個相同的副本均稱作該組的一個成員,每個組按數字標識。日誌寫進程(LGWR)將重做記錄從重做日誌緩衝區寫入重做日誌組的所有成員,直至填滿文件或日誌切換操作。然後,切換至下一組文件並執行寫入操作。將以迴圈方式使用重做日誌組。
最佳實踐提示:如果可能,多路復用的重做日誌文件應駐留在不同的磁碟上。
瞭解實例恢復
自動實例恢復或崩潰恢復
-原因是嘗試打開的資料庫中的文件在關閉時不同步
-使用重做日誌組中存儲的信息來同步文件
-涉及到兩個不同的操作
-前滾,將重做日誌更改(已提交的和未提交的)應用到數據文件
-回退,已執行但尚未提交的更改會放回到初始狀態
Oracle DB會自動從實例故障中進行恢復。實例所需要的就是正常啟動。如果Oracle Restart已啟用並且配置為監視該資料庫,則該啟動操作會自動進行。實例會裝載控制文件,然後嘗試打開數據文件。如果實例發現數據文件在關閉期間尚未同步,則會使用重做日誌組中包含的信息將資料庫前滾到關閉時的狀態。然後,將打開資料庫,並回退所有未提交的事務處理。
實例恢復的階段
1.啟動實例(數據文件不同步)
2.前滾(重做)
3.文件中有已提交和未提交的數據
4.打開資料庫
5.回退(還原)
6.文件中只有已提交的數據
![]() 要使實例打開一個數據文件,數據文件頭中包含的系統更改號(SCN)必須與資料庫控制文件中存儲的當前SCN匹配。
如果編號不匹配,實例會應用聯機重做日誌中的重做數據,並按順序“重做”事務處理,直到數據文件處於最新狀態。所有數據文件都與控制文件同步後,就會打開資料庫,此時用戶可以進行登錄。
應用重做日誌後,會應用所有事務處理,使資料庫返回到出現錯誤時的狀態。這通常包括正在進行但尚未提交的事務處理。打開資料庫之後,會回退那些提交的事務處理。在實例恢復的回退階段結束時,數據文件只包含提交的數據。
優化實例恢復
-在實例恢復期間,必須將檢查點位置與重做日誌末尾之間的事務處理應用到數據文件
-通過控制檢查點位置與重做日誌末尾之間的差異可優化實例恢復
要使實例打開一個數據文件,數據文件頭中包含的系統更改號(SCN)必須與資料庫控制文件中存儲的當前SCN匹配。
如果編號不匹配,實例會應用聯機重做日誌中的重做數據,並按順序“重做”事務處理,直到數據文件處於最新狀態。所有數據文件都與控制文件同步後,就會打開資料庫,此時用戶可以進行登錄。
應用重做日誌後,會應用所有事務處理,使資料庫返回到出現錯誤時的狀態。這通常包括正在進行但尚未提交的事務處理。打開資料庫之後,會回退那些提交的事務處理。在實例恢復的回退階段結束時,數據文件只包含提交的數據。
優化實例恢復
-在實例恢復期間,必須將檢查點位置與重做日誌末尾之間的事務處理應用到數據文件
-通過控制檢查點位置與重做日誌末尾之間的差異可優化實例恢復
![]() 在實例對事務處理返回commit complete之前,在重做日誌組中會記錄事務處理信息。重做日誌組中的信息可確保在出現錯誤時可恢復事務處理。另外,事務處理信息還需要寫入數據文件。由於數據文件寫進程比重做寫進程要慢很多,因此,通常在重做日誌組中記錄了信息之後,才會執行數據文件寫操作。(數據文件隨機寫進程比重做日誌文件連續寫進程要慢。)
每隔三秒,檢查點進程就會在控制文件中記錄關於重做日誌中檢查點位置的信息。因此,Oracle DB認為此時間點之前記錄的所有重做日誌項對資料庫恢復來說都不需要的。
實例恢復所需的時間指的是將數據文件的最後一個檢查點推進到控制文件中記錄的最新SCN所需的時間。管理員通過設置MTTR目標(以秒為單位)以及調整重做日誌組的大小來控制該時間。例如,對於兩個重做組,檢查點位置與重做日誌組末尾之間的距離不能大於最小重做日誌組的90%。
使用MTTR指導
-以秒或分鐘為單位指定所需的時間
-預設值為0(禁用)
-最大值為3600秒(1個小時)
在實例對事務處理返回commit complete之前,在重做日誌組中會記錄事務處理信息。重做日誌組中的信息可確保在出現錯誤時可恢復事務處理。另外,事務處理信息還需要寫入數據文件。由於數據文件寫進程比重做寫進程要慢很多,因此,通常在重做日誌組中記錄了信息之後,才會執行數據文件寫操作。(數據文件隨機寫進程比重做日誌文件連續寫進程要慢。)
每隔三秒,檢查點進程就會在控制文件中記錄關於重做日誌中檢查點位置的信息。因此,Oracle DB認為此時間點之前記錄的所有重做日誌項對資料庫恢復來說都不需要的。
實例恢復所需的時間指的是將數據文件的最後一個檢查點推進到控制文件中記錄的最新SCN所需的時間。管理員通過設置MTTR目標(以秒為單位)以及調整重做日誌組的大小來控制該時間。例如,對於兩個重做組,檢查點位置與重做日誌組末尾之間的距離不能大於最小重做日誌組的90%。
使用MTTR指導
-以秒或分鐘為單位指定所需的時間
-預設值為0(禁用)
-最大值為3600秒(1個小時)
![]() FAST_START_MTTR_TARGET初始化參數可以簡化實例或系統故障的恢復時間配置。
MTTR指導可將FAST_START_MTTR_TARGET值轉換為多個參數,以便在所需時間內(或者在儘量接近此時間的範圍內)啟用實例恢復。請註意,將FAST_START_MTTR_TARGET參數顯式設置為0會禁用MTTR指導。
FAST_START_MTTR_TARGET參數的設置值必須支持系統的服務級協議。如果MTTR目標的值較小,則會增加了數據文件寫入次數而增加I/O開銷(這會影響性能)。但是,如果MTTR目標設置得過大,則實例在崩潰後需要花費較長的時間才會恢復。
介質故障
FAST_START_MTTR_TARGET初始化參數可以簡化實例或系統故障的恢復時間配置。
MTTR指導可將FAST_START_MTTR_TARGET值轉換為多個參數,以便在所需時間內(或者在儘量接近此時間的範圍內)啟用實例恢復。請註意,將FAST_START_MTTR_TARGET參數顯式設置為0會禁用MTTR指導。
FAST_START_MTTR_TARGET參數的設置值必須支持系統的服務級協議。如果MTTR目標的值較小,則會增加了數據文件寫入次數而增加I/O開銷(這會影響性能)。但是,如果MTTR目標設置得過大,則實例在崩潰後需要花費較長的時間才會恢復。
介質故障
![]() Oracle Corporation將介質故障定義為導致一個或多個資料庫文件(數據文件,控制文件或重做日誌文件)丟失或損壞的任何故障。要從介質故障中進行恢復,需要還原並恢復缺失的文件。為確保可從介質故障中恢複數據庫,請遵循後面的最佳實踐。
配置可恢復性
要配置資料庫的最大可恢復性,必須執行以下操作:
-計劃常規備份
修複介質故障時通常需要從備份中還原丟失或損壞的文件
-多路復用控制文件
與資料庫關聯的所有控制文件都是相同的。如果丟失一個控制文件,則並不難恢復;但如果丟失了所有控制文件,則很難恢復。為了避免丟失所有控制文件,至少要有兩個副本。
-多路復用重做日誌組
要從實例故障或介質故障中進行恢復,可使用重做日誌信息將數據文件前滾到上次提交的事務處理。如果重做日誌組依賴於一個重做日誌文件,那麼丟失這個文件意味著很可能會丟失數據。至少要確保每個重做日誌組有兩個副本;如果可能的話,每個副本都應在不同的磁碟控制器中。
-保留重做日誌的歸檔副本
如果丟失了某個文件從備份中進行還原,則實例必須應用重做信息,以便將該文件推進到控制文件中包含的最新SCN。使用預設設置時,重做信息寫入數據文件後,資料庫會覆蓋這些信息。資料庫可配置為在重做日誌的歸檔副本中保留重做信息。這稱為將資料庫置於archivelog模式下。
配置快速恢復區
-強烈建議使用,可簡化備份存儲管理
-使用存儲空間(與工作資料庫文件分開)
-位置由DB_RECOVERY_FILE_DEST參數指定
-大小由DB_RECOVERY_FILE_DEST_SIZE參數指定
-足夠大,可存放備份,歸檔日誌,閃回日誌,多路復用控制文件和多路復用重做日誌
-根據保留策略自動進行管理
配置快速恢復區意味著確定了位置,大小和保留策略。
快速恢復區是磁碟上為包含歸檔日誌,備份,閃回日誌,多路復用控制文件和多路復用重做日誌而專門留出的空間。快速恢復區可簡化備份存儲管理,因此強烈建議使用該功能。放置快速恢復區的存儲位置應該與資料庫的數據文件以及主要聯機日誌文件和控制文件的位置不同。
分配給快速恢復區的磁碟空間量取決於資料庫的大小和活動級別。通常情況下,快速恢復區越大,就越有用。理想情況下,快速恢復區應足夠大,可存放數據文件和控制文件副本,以及基於保留策略從保留的備份恢複數據庫所需的閃回日誌,聯機重做日誌和歸檔日誌。(簡而言之,快速恢復區至少應為資料庫大小的兩倍,以便可保留一個備份和若幹歸檔日誌。)
快速恢復區的空間管理由備份保留策略控制。保留策略確定文件何時過時,即何時這些文件對達到數據恢複目標已不再有用。Oracle DB通過刪除不再需要的文件自動管理該存儲。
多路復用控制文件
為了防範資料庫故障,資料庫控制文件應保存多個副本。
Oracle Corporation將介質故障定義為導致一個或多個資料庫文件(數據文件,控制文件或重做日誌文件)丟失或損壞的任何故障。要從介質故障中進行恢復,需要還原並恢復缺失的文件。為確保可從介質故障中恢複數據庫,請遵循後面的最佳實踐。
配置可恢復性
要配置資料庫的最大可恢復性,必須執行以下操作:
-計劃常規備份
修複介質故障時通常需要從備份中還原丟失或損壞的文件
-多路復用控制文件
與資料庫關聯的所有控制文件都是相同的。如果丟失一個控制文件,則並不難恢復;但如果丟失了所有控制文件,則很難恢復。為了避免丟失所有控制文件,至少要有兩個副本。
-多路復用重做日誌組
要從實例故障或介質故障中進行恢復,可使用重做日誌信息將數據文件前滾到上次提交的事務處理。如果重做日誌組依賴於一個重做日誌文件,那麼丟失這個文件意味著很可能會丟失數據。至少要確保每個重做日誌組有兩個副本;如果可能的話,每個副本都應在不同的磁碟控制器中。
-保留重做日誌的歸檔副本
如果丟失了某個文件從備份中進行還原,則實例必須應用重做信息,以便將該文件推進到控制文件中包含的最新SCN。使用預設設置時,重做信息寫入數據文件後,資料庫會覆蓋這些信息。資料庫可配置為在重做日誌的歸檔副本中保留重做信息。這稱為將資料庫置於archivelog模式下。
配置快速恢復區
-強烈建議使用,可簡化備份存儲管理
-使用存儲空間(與工作資料庫文件分開)
-位置由DB_RECOVERY_FILE_DEST參數指定
-大小由DB_RECOVERY_FILE_DEST_SIZE參數指定
-足夠大,可存放備份,歸檔日誌,閃回日誌,多路復用控制文件和多路復用重做日誌
-根據保留策略自動進行管理
配置快速恢復區意味著確定了位置,大小和保留策略。
快速恢復區是磁碟上為包含歸檔日誌,備份,閃回日誌,多路復用控制文件和多路復用重做日誌而專門留出的空間。快速恢復區可簡化備份存儲管理,因此強烈建議使用該功能。放置快速恢復區的存儲位置應該與資料庫的數據文件以及主要聯機日誌文件和控制文件的位置不同。
分配給快速恢復區的磁碟空間量取決於資料庫的大小和活動級別。通常情況下,快速恢復區越大,就越有用。理想情況下,快速恢復區應足夠大,可存放數據文件和控制文件副本,以及基於保留策略從保留的備份恢複數據庫所需的閃回日誌,聯機重做日誌和歸檔日誌。(簡而言之,快速恢復區至少應為資料庫大小的兩倍,以便可保留一個備份和若幹歸檔日誌。)
快速恢復區的空間管理由備份保留策略控制。保留策略確定文件何時過時,即何時這些文件對達到數據恢複目標已不再有用。Oracle DB通過刪除不再需要的文件自動管理該存儲。
多路復用控制文件
為了防範資料庫故障,資料庫控制文件應保存多個副本。
![]() 控制文件是一個二進位小文件,用於說明資料庫的結構。只要裝載或打開資料庫,oracle伺服器必須能夠寫入這個文件。如果這個文件不存在,就不能裝載資料庫,因此需要恢復或重新創建控制文件。資料庫應該至少有兩個控制文件,且這些文件應位於不同的磁碟,這樣才能將由於丟失某個控制文件造成的影響降至最低。
因為所有控制文件必須是隨時可用的,所以丟失一個控制文件就會導致實例出錯。但在這中情況下進行恢復並不難,只需複製其中一個控制文件即可。如果丟失了所有控制文件,則進行恢復要難一些,但這種故障通常也不是災難性故障。
添加控制文件
如果使用ASM作為存儲技術,則只要有兩個控制文件且每個磁碟組(例如+DATA和+FRA)上有一個控制文件,則不需要進行進一步的多路復用。對於使用OMF的資料庫(例如使用ASM存儲的資料庫),在使用RMAN(或通過Oracle Enterprise Manager)的恢復過程中,必須創建所有附加控制文件。在使用常規系統存儲的資料庫中,添加控制文件是一個手動操作:
1.使用命令變更SPFILE
ALTER SYSTEM SET CONTROL_FILES='/u01/app/oracle/oradata/orcl/control01.ctl','/u01/app/oracle/fast_recover_size/orcl/control02.ctl','/u03/app/oracle/oradata/orcl/control03.ctl' scope=spfile;
2.關閉資料庫
3.使用操作系統將現有控制文件複製到新文件選擇的位置
4.打開資料庫
重做日誌文件
多路復用重做日誌組可避免介質故障和數據丟失。這會增加資料庫I/O。建議重做日誌組滿足以下條件:
-每個組至少有兩個成員(文件)
-每個成員
-如果使用文件系統存儲,則位於單獨的磁碟或控制器上
-如果使用ASM,則位於單獨的磁碟組上(例如+DATA和+FRA)
註:多路復用重做日誌可能會影響資料庫整體性能。
控制文件是一個二進位小文件,用於說明資料庫的結構。只要裝載或打開資料庫,oracle伺服器必須能夠寫入這個文件。如果這個文件不存在,就不能裝載資料庫,因此需要恢復或重新創建控制文件。資料庫應該至少有兩個控制文件,且這些文件應位於不同的磁碟,這樣才能將由於丟失某個控制文件造成的影響降至最低。
因為所有控制文件必須是隨時可用的,所以丟失一個控制文件就會導致實例出錯。但在這中情況下進行恢復並不難,只需複製其中一個控制文件即可。如果丟失了所有控制文件,則進行恢復要難一些,但這種故障通常也不是災難性故障。
添加控制文件
如果使用ASM作為存儲技術,則只要有兩個控制文件且每個磁碟組(例如+DATA和+FRA)上有一個控制文件,則不需要進行進一步的多路復用。對於使用OMF的資料庫(例如使用ASM存儲的資料庫),在使用RMAN(或通過Oracle Enterprise Manager)的恢復過程中,必須創建所有附加控制文件。在使用常規系統存儲的資料庫中,添加控制文件是一個手動操作:
1.使用命令變更SPFILE
ALTER SYSTEM SET CONTROL_FILES='/u01/app/oracle/oradata/orcl/control01.ctl','/u01/app/oracle/fast_recover_size/orcl/control02.ctl','/u03/app/oracle/oradata/orcl/control03.ctl' scope=spfile;
2.關閉資料庫
3.使用操作系統將現有控制文件複製到新文件選擇的位置
4.打開資料庫
重做日誌文件
多路復用重做日誌組可避免介質故障和數據丟失。這會增加資料庫I/O。建議重做日誌組滿足以下條件:
-每個組至少有兩個成員(文件)
-每個成員
-如果使用文件系統存儲,則位於單獨的磁碟或控制器上
-如果使用ASM,則位於單獨的磁碟組上(例如+DATA和+FRA)
註:多路復用重做日誌可能會影響資料庫整體性能。
![]() 重做日誌組由一個或多個重做日誌文件組成。組中的每個日誌文件都是相同的。Oracle Corporation建議每個重做日誌組至少包含兩個文件。如果使用文件系統存儲,則每個成員應該分佈在單獨的磁碟或控制器上,這樣在單個設備出現故障時就不會破壞整個日誌組。如果使用ASM存儲,則每個成員應該位於單獨的磁碟組中,例如+DATA和+FRA。丟失了整個當前日誌組是一種最嚴重的介質故障,因為這會導致數據丟失。但丟失了包括多個成員的日誌組中的一個成員是微不足道的,這並不會影響資料庫操作(只會導致在預警日誌中發佈預警)。
請記住,由於不能在事務處理信息寫入日誌之前完成提交,因此多路復用重做日誌可能會嚴重影響到資料庫的性能。必須將重做日誌文件置於速度最快的控制器服務的速度最快的磁碟中。請儘量不要將其它任何資料庫文件與重做日誌文件保存在同一磁碟上(除非使用自動存儲管理ASM)。由於給定時間只能寫入一個組,因此,同一磁碟中包含多個組的成員不會有什麼性能影響。
重做日誌組由一個或多個重做日誌文件組成。組中的每個日誌文件都是相同的。Oracle Corporation建議每個重做日誌組至少包含兩個文件。如果使用文件系統存儲,則每個成員應該分佈在單獨的磁碟或控制器上,這樣在單個設備出現故障時就不會破壞整個日誌組。如果使用ASM存儲,則每個成員應該位於單獨的磁碟組中,例如+DATA和+FRA。丟失了整個當前日誌組是一種最嚴重的介質故障,因為這會導致數據丟失。但丟失了包括多個成員的日誌組中的一個成員是微不足道的,這並不會影響資料庫操作(只會導致在預警日誌中發佈預警)。
請記住,由於不能在事務處理信息寫入日誌之前完成提交,因此多路復用重做日誌可能會嚴重影響到資料庫的性能。必須將重做日誌文件置於速度最快的控制器服務的速度最快的磁碟中。請儘量不要將其它任何資料庫文件與重做日誌文件保存在同一磁碟上(除非使用自動存儲管理ASM)。由於給定時間只能寫入一個組,因此,同一磁碟中包含多個組的成員不會有什麼性能影響。
alter database add logfile group 1 ('/u01/app/oracle/oradata/orcl/p_redo01_01.log','/u02/app/oracle/oradata/orcl/p_redo01_02.log') size 512M;
alter database add logfile group 2 ('/u01/app/oracle/oradata/orcl/p_redo02_01.log','/u02/app/oracle/oradata/orcl/p_redo02_02.log') size 512M;
alter database add logfile group 3 ('/u01/app/oracle/oradata/orcl/p_redo03_01.log','/u02/app/oracle/oradata/orcl/p_redo03_02.log') size 512M;
歸檔日誌文件
要保留重做信息,請通過執行以下步驟,創建重做日誌文件的歸檔副本
1.指定歸檔日誌文件命名慣例
2.指定一個或多個歸檔日誌文件的位置
3.將資料庫切換為ARCHIVIELOG模式
![]() Oracle 歸檔日誌生成格式[(%r重做日誌id %t線程號rac節點 %s日誌序列號)->必須存在 (%d 資料庫id)->可選]
Oracle 歸檔日誌生成格式[(%r重做日誌id %t線程號rac節點 %s日誌序列號)->必須存在 (%d 資料庫id)->可選]
alter system set log_archive_format='arch_%r_%t_%s.arc' scope=spfile;
alter system set log_archive_dest='location=/u01/archive' scope=spfile;
shutdown immediate
startup mount
alter database archivelog;
alter database open;
歸檔(ARCn)進程
-是可選的後臺進程
-為資料庫設置了ARCHIVELOG模式後會自動歸檔聯機重做日誌文件
-保留對資料庫所做的所有更改的記錄
![]() ARCn是可選的後臺進程。但是,該進程對於在磁碟損壞後恢複數據庫非常重要。聯機重做日誌組填滿後,Oracle實例將開始對下一個聯機重做日誌組進行寫入。從一個聯機重做日誌組切換到另一個聯機重做日誌組的過程稱為“日誌切換”。ARCn進程在每次日誌切換時都會對已填滿的日誌啟動歸檔。該進程先自動歸檔聯機重做日誌組,然後在重用該日誌組,從而保留對資料庫所做的所有更改。這樣即使磁碟驅動器損壞,也可以將資料庫恢復故障點。
DBA必須做出的一個重要決策是將資料庫配置為ARCHIVELOG模式下運行還是將其配置在NOARCHIVELOG模式下運行。
-在NOARCHIVELOG模式下,每次進行日誌切換時都會覆蓋聯機重做日誌文件。
-在ARCHIVELOG模式下,必須先歸檔不活動的已填滿聯機重做日誌文件組,然後才能再次使用這些聯機重做日誌文件。
-ARCHIVELOG模式對大多數備份策略而言是必不可少的,並且這種模式很容易進行配置。
-如果歸檔日誌文件目標位置填滿或者無法寫入,資料庫最終將停止。從歸檔日誌文件目標位置刪除歸檔文件,資料庫將繼續操作。
總結:
DBA部分職責(避免故障,延長故障間隔時間,組件冗餘,減少MTTR恢復時間,減少數據丟失)
資料庫可能發生的故障:
語句失敗
用戶進程失敗
網路故障
用戶誤操作
實例故障
介質故障
資料誤刪除後的閃回操作,AS OF閃回查詢,閃回版本查詢,閃回事務查詢
瞭解實例恢復:CKPT檢查點進程,DBWn資料庫寫入進程,LGWR日誌寫入進程,ARCn歸檔進程。重做日誌和歸檔日誌作用。恢復步驟(不同步->前滾->應用->打開資料庫->回退->提交數據)
優化實例恢復,合理配置MTTR指定
介質恢復:多路復用(控制文件,重做日誌文件),配置快速恢復區,歸檔模式和常規備份
ARCn是可選的後臺進程。但是,該進程對於在磁碟損壞後恢複數據庫非常重要。聯機重做日誌組填滿後,Oracle實例將開始對下一個聯機重做日誌組進行寫入。從一個聯機重做日誌組切換到另一個聯機重做日誌組的過程稱為“日誌切換”。ARCn進程在每次日誌切換時都會對已填滿的日誌啟動歸檔。該進程先自動歸檔聯機重做日誌組,然後在重用該日誌組,從而保留對資料庫所做的所有更改。這樣即使磁碟驅動器損壞,也可以將資料庫恢復故障點。
DBA必須做出的一個重要決策是將資料庫配置為ARCHIVELOG模式下運行還是將其配置在NOARCHIVELOG模式下運行。
-在NOARCHIVELOG模式下,每次進行日誌切換時都會覆蓋聯機重做日誌文件。
-在ARCHIVELOG模式下,必須先歸檔不活動的已填滿聯機重做日誌文件組,然後才能再次使用這些聯機重做日誌文件。
-ARCHIVELOG模式對大多數備份策略而言是必不可少的,並且這種模式很容易進行配置。
-如果歸檔日誌文件目標位置填滿或者無法寫入,資料庫最終將停止。從歸檔日誌文件目標位置刪除歸檔文件,資料庫將繼續操作。
總結:
DBA部分職責(避免故障,延長故障間隔時間,組件冗餘,減少MTTR恢復時間,減少數據丟失)
資料庫可能發生的故障:
語句失敗
用戶進程失敗
網路故障
用戶誤操作
實例故障
介質故障
資料誤刪除後的閃回操作,AS OF閃回查詢,閃回版本查詢,閃回事務查詢
瞭解實例恢復:CKPT檢查點進程,DBWn資料庫寫入進程,LGWR日誌寫入進程,ARCn歸檔進程。重做日誌和歸檔日誌作用。恢復步驟(不同步->前滾->應用->打開資料庫->回退->提交數據)
優化實例恢復,合理配置MTTR指定
介質恢復:多路復用(控制文件,重做日誌文件),配置快速恢復區,歸檔模式和常規備份



