
重點不是說PageRank是什麼,而是怎麼用代碼實現 什麼是PageRank? PageRank,網頁排名,又稱網頁級別、Google左側排名或佩奇排名,是一種由[1] 根據網頁之間相互的超鏈接計算的技術,而作為網頁排名的要素之一,以Google公司創辦人拉里·佩奇(Larry Page)之姓來命名 ...
重點不是說PageRank是什麼,而是怎麼用代碼實現
什麼是PageRank?
PageRank,網頁排名,又稱網頁級別、Google左側排名或佩奇排名,是一種由[1] 根據網頁之間相互的超鏈接計算的技術,而作為網頁排名的要素之一,以Google公司創辦人拉里·佩奇(Larry Page)之姓來命名。Google用它來體現網頁的相關性和重要性,在搜索引擎優化操作中是經常被用來評估網頁優化的成效因素之一。Google的創始人拉里·佩奇和謝爾蓋·布林於1998年在斯坦福大學發明瞭這項技術。
PageRank的誕生背景?
早期的搜索引擎經歷了“不評價” 和“基於檢索詞”的評價兩個階段。 “基於檢索詞”的評價演算法很直觀,但是容易受到“Term Spam”的攻擊。其實從搜索引擎出現的那天起,spammer和搜索引擎反作弊的鬥法就沒有停止過。Spammer是這樣一群人——試圖通過搜索引擎演算法的漏洞來提高目標頁面(通常是一些廣告頁面或垃圾頁面)的重要性,使目標頁面在搜索結果中排名靠前。用戶很容易被帶入垃圾網頁,用戶體驗極差。PageRank也應運而生。
怎麼實現PageRank?
簡單的說PageRank讓鏈接來"投票",一個頁面的“得票數”由所有鏈向它的頁面的重要性來決定,到一個頁面的超鏈接相當於對該頁投一票。一個頁面的PageRank是由所有鏈向它的頁面(“鏈入頁面”)的重要性經過遞歸演算法得到的。一個有較多鏈入的頁面會有較高的等級,相反如果一個頁面沒有任何鏈入頁面,那麼它沒有等級。
最簡單pagerank模型
網頁,可以抽象成的圖當中的結點,網頁與網頁當中的鏈接關係可以模型化為數據結構中邏輯結構圖再具體點是有向圖(表示哪個網頁鏈接哪個網頁),我們可以把鏈接關係用作離散數學圖論當中的可達矩陣形象具體的表示,下麵我來給大傢具體的說明,如下麵這個例子:

這個例子中有四個網頁,如果當前在A網頁,那麼上網者將會各有1/3的概率瀏覽到B、C、D網頁,這裡的3表示A有3條出鏈,如果一個網頁有k條出鏈,那麼跳轉任意一個出鏈上的概率是1/k,同理D到B的概率1,而B到C的概率為1。一般用轉移矩陣表示上網者的跳轉概率,如果用n表示網頁的數目,則轉移矩陣M是一個n*n的方陣(可由可達矩陣轉換成轉移矩陣);如果網頁j有k個出鏈,那麼對每一個出鏈指向的網頁i,有M[i][j]=1/k,而其他網頁的M[i][j]=0;上面示例圖對應的可達矩陣如下:
A 0 1 0 0
B 1 0 0 1
C 1 1 0 0
D 1 0 1 0
對應的轉移矩陣為:
A B C D
A 0 0.5 0 0
B 0.33 0 0 1
C 0.33 0.5 0 0
D 0,33 0 1 0
剛開始的時候,假設上網者在每一個網頁的概率都是相等的(這個假設確實存在,假設世界上只有n個網頁,那麼我只能開始的時候進入n個網頁當中的一個,就是1/n),即1/n,於是開始的時候的概率分佈就是一個所有值都為1/n的n維列向量V0(我們以概率分佈向量的結果作為網頁的質量結果,因為質量越高,被上網者瀏覽的概率越大,也稱pr值的大小),在轉移矩陣M去右乘概率分佈向量V0,就得到了第一步之後上網者的概率分佈向量MV0,(nXn)*(nX1)依然得到一個nX1的矩陣。下麵是V1的計算過程:

註意矩陣M中M[i][j]不為0表示用一個鏈接從j指向i,M的第一行乘以V0,表示累加所有網頁到網頁A的概率即得到0.125。得到了V1後,再用V1去右乘M得到V2,一直下去,最終V會收斂,即Vn=MV(n-1),上面的圖示例,不斷的迭代,最終
V=[0.177,0.319,0.225,0.277]’
(演算法的證明這裡我們就不證明瞭,有興趣的朋友可以百度一下)
終止點問題
上述上網者的行為是一個馬爾科夫過程的實例,要滿足收斂性,需要具備一個條件:
圖是強連通的,即從任意網頁可以到達其他任意網頁.
但是在浩瀚的互聯網中,網頁肯定是不滿足強連通特性的,我們設計模型的時候想要達到強連通特性是很簡單的,但是在互聯網上有一些網頁不指向任何網頁,如果按照上面的計算,當瀏覽到這個沒有指向的網頁的時候那是不是就無法出去了呢?,導致前面累計得到的轉移概率被清零,這樣下去,最終的得到的概率分佈向量所有元素幾乎都為0。假設我們把上面圖中B到A的鏈接丟掉,A變成了一個終止點,得到下麵這個圖:
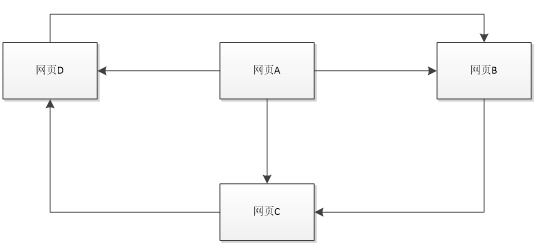
對應的轉移矩陣為:
A B C D
A 0 0 0 0
B 0.33 0 0 1
C 0.33 1 0 0
D 0.33 0 1 0
連續迭代下去,最終所有元素都為0。
陷阱問題
要是有投機取巧這想到用網頁自己鏈接自己,讓我們瀏覽這中了這個無線迴圈的陷阱怎麼辦呢?:
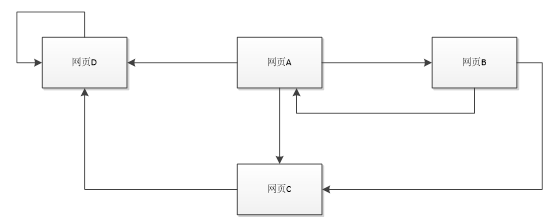
上網者跑到D網頁後,再也不能從D中出來,將最終導致概率分佈值全部轉移到D上來,這使得其他網頁的概率分佈值為0,從而整個網頁排名就失去了意義。如果按照上面圖對應的轉移矩陣為:
A B C D
A 0 0.5 0 0
B 0.33 0 0 0
C 0.33 0.5 0 0
D 0,33 0 1 1
不斷的迭代下去,的結果一定會是[0,0,0,1]的
解決終止點問題和陷阱問題
其實會出現這兩個問題,是因為最開始構建模型的時候我們忽略了一個東西:上網者可以隨時跳出他瀏覽的網頁(瀏覽器上輸入網址就行了),而不需要擔心,要是瀏覽的網頁沒有鏈接那不就是不能出去了嗎?(結果只需要輸入網址就可以跳出去),那瀏覽的網頁連接了自己瀏覽這不就一直在瀏覽這個了嗎?(結果是瀏覽者發現這是陷阱都在重覆瀏覽一個網頁的時候,他可以輕鬆跳過去,只需要輸入網址即可),當然正常情況他也是可以輸入網址跳轉任何他想去的網頁,這個時候我們需要引入一個概念:阻尼繫數(簡單來說就是點擊網頁的概率-實際上就是用戶感到無聊,停止點擊,隨機跳到新URL的概率),這裡我們取α = 0.8,當然也有很多的覺得0.85是好的,這個概念已經給出,數值看我們自己~(覺得能讓你的結果符合預期就ok啦..)。 從而我們得到了更加完善的公式:
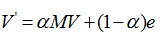
由於這些是數學上的計算,有了公式是比較容易推出結果來的,所以就不在舉例啦~~
如何通過代碼具體的實現?
可以把每個網頁所構成的複雜的關係模型化成數據結構的邏輯結構圖(有向圖),每個網頁就是一個結點,當一個網頁(網頁A)鏈接著另一個網頁(網頁B)的時候可以抽象的看出A->B,即通過出度和入度來描述鏈接和被鏈接數,當你通過創建有向圖的時候其實就相當於模擬了網頁之間的關係(當然浩瀚的互聯網中網頁數不勝數,我這裡只是通過一個小的環境模擬這個演算法的實現),通過PageRank演算法加之迭代,使其每個網頁的pr(衡量網頁質量的參數)值都趨於穩定的時候,由pr值大小排序出來的網頁的先後順序可以相對準確的衡量網頁質量。
我先是通過c語言模型化PageRank的演算法 算出每個結點(網頁)的pr值。
需要構建有向圖來模型化網頁(c語言的結點是手動輸入的,因為為了測試方便嘛~)
#include <stdio.h> #include <stdlib.h> #include <math.h> #define OK 1 #define ERROR -1 #define FALSE 0 #define TRUE 1 #define MAXVER 20 //定義最大頂點數 #define MAXQSIZE 100 //#define OVERFLOW -2 typedef char verType; //頂點類型 typedef int Status; typedef int Boolean; typedef struct { verType verx[MAXVER]; int arcs[MAXVER][MAXVER]; //鄰接矩陣 int vernum, arcnum; //定義最大頂點數 和 弧 }MGraph; Boolean visited[MAXVER]; //頂點開始都沒有被訪問過 int locate(MGraph G, verType ch); //查找頂點在數組中的下標 Status CreateDG(MGraph *G,int v); //創建有向圖 void Create_Transfer_matrix(MGraph G, double ***F); //創建轉移矩陣 double** Mat_mul(double **M1, int num); //矩陣相乘 int GetNum(MGraph G, int h, int l); //得到每一行非0項的個數 double *Iteration(double *M1, double **M2, double *M, int num); //迭代法 int main(void) { double **F = NULL; MGraph G; CreateDG(&G, 0); Create_Transfer_matrix(G, &F); Mat_mul(F, G.vernum); return 0; } double *Iteration(double *M1, double **M2, double *M, int num) {//迭代法 double *M3, temp = 0; int i, j; M3 = malloc(num * sizeof(double)); printf("\n"); for(i = 0; i < num; i++) { printf("@ = %0.10lf\n", M[i]); } for (i = 0; i < num; i++) { for (j = 0; j < num; j++) { temp = M1[j] * M2[i][j] + temp; } M3[i] = temp + M[i]; temp = 0; } putchar(10); for (i = 0; i < num; i++) { printf("%.10lf\n", M3[i]); } putchar(10); return M3; } double** Mat_mul(double **M1, int num) { int i,j; double *M2, *M3, temp = 0, *M; M3 = malloc(num *sizeof(double)); M2 = malloc(num * sizeof(double)); for (i = 0; i < num; i++) //初始化概率分佈矩陣 { M2[i] = (1.0 / num * 1.0); } for (i = 0; i < num; i++) { for (j = 0; j < num; j++) { temp = M1[i][j] * M2[j] + temp; } M3[i] = temp + M2[i] * 0.2; temp = 0; } for (i = 0; i < num; i++) { printf("%.10lf\n", M3[i]); } for (j = 0; j < num; j++) { M2[j] = M2[j] * 0.2; } M = Iteration(M3, M1, M2, num); //調用函數實現轉移矩陣和概率向量的相乘 while (fabs(M[0] - M3[0]) > 0.0000000001) //設置迭代結束條件 { M3 = M; M = Iteration(M3, M1, M2, num); } for (i = 0; i < num; i++) { M[i] = M[i] * 0.8 + 0.2 / num; } for (i = 0; i < num; i++) printf(" - %.10lf\n", M3[i] - 0.0000000001); return M1; } void Create_Transfer_matrix(MGraph G, double ***F) {//創建轉移矩陣 int i, j; (*F) = malloc(G.vernum * sizeof(double *)); for (i = 0; i < G.vernum; i++) { (*F)[i] = malloc(G.vernum * sizeof(double)); } for (i = 0; i < G.vernum; i++) { for (j = 0; j < G.vernum; j++) { if (GetNum(G, G.vernum, i) == 0) (*F)[j][i] = 0; else (*F)[j][i] = 0.8 * (G.arcs[j][i] / (GetNum(G, G.vernum, i) * 1.0)); } } putchar(10); printf("\n轉移矩陣為:\n"); for (i = 0; i < G.vernum; i++) { for (j = 0; j < G.vernum; j++) { printf("%.10lf ", (*F)[i][j]); } printf("\n"); } printf("\n"); } int locate(MGraph G, verType ch) { int i; for (i = 0; i < G.vernum && ch != G.verx[i]; i++); return i; } Status CreateDG(MGraph *G,int v) { int i, j, k; verType ch1, ch2; printf("請輸入有向圖的頂點數和弧數,格式如(0 0): "); scanf("%d %d", &G->vernum, &G->arcnum); fflush(stdin); //除緩存 printf("請輸入頂點符號:\n"); for (i = 0; i < G->vernum; i++) { scanf("%c", &G->verx[i]); fflush(stdin); } for (i = 0; i < G->vernum; i++) { for (j = 0; j < G->vernum; j++) { G->arcs[i][j] = 0; //賦初值 } } printf("請輸入有連接的點: 格式(A B)\n"); for (i = 0; i < G->arcnum; i++) { printf("請輸入第%d對值\n", i + 1); scanf("%c %c", &ch1, &ch2); //輸入頂點符號 fflush(stdin); k = locate(*G, ch1); //獲得頂點下標 j = locate(*G, ch2); G->arcs[j][k] = 1; //為鄰接矩陣賦值 } return OK; } int GetNum(MGraph G, int h, int l) //得到每一列非0的個數 { int i, Num = 0; for (i = 0; i < h; i++) { if (G.arcs[i][l] > 0) { Num++; } } return Num; }
雖然實現了PageRank的演算法但是僅僅是實現了而且,想要有趣一點的話可以簡單模擬一下PageRank的應用背景:我在一個文件夾下麵建立的多個HTML的網頁(相互之間有鏈接),通過PageRank演算法把每個網頁的質量進行了排名,由程式給出排名順序反饋給用戶(通過C#實現的)
這個是提前創好的簡單的HTML網頁(我的目的是模擬,所有網頁只有一個標簽,有的連標簽都沒有……)
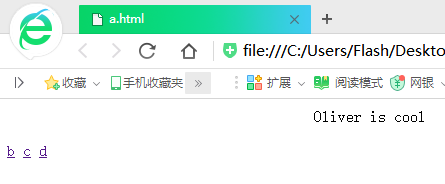

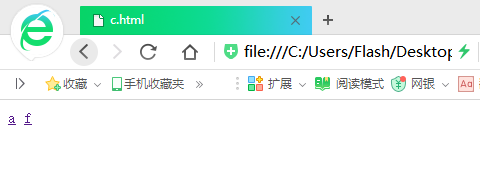
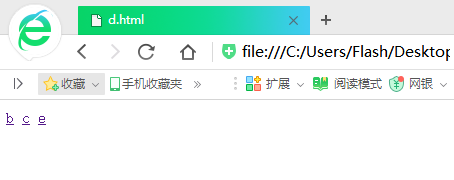
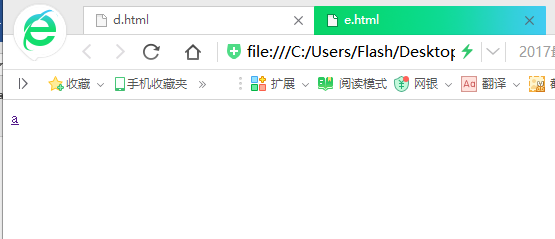
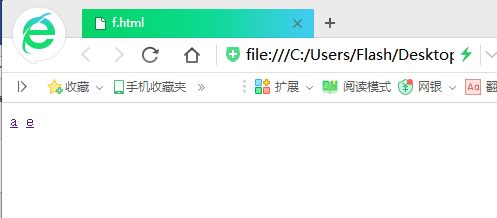
大家可以看出a是被鏈接最多的網頁,其他的被鏈接的先後順序相信大家也可以看出來,下麵開始演示程式:
1.首先輸入網頁所在的文件夾:
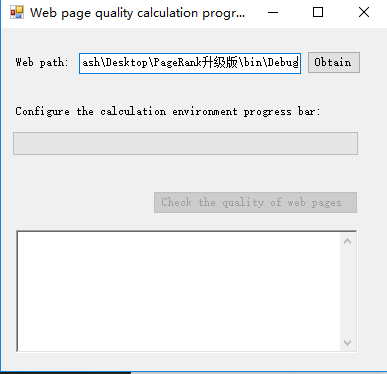
2.通過配置計算環境及其其他的相關事宜:
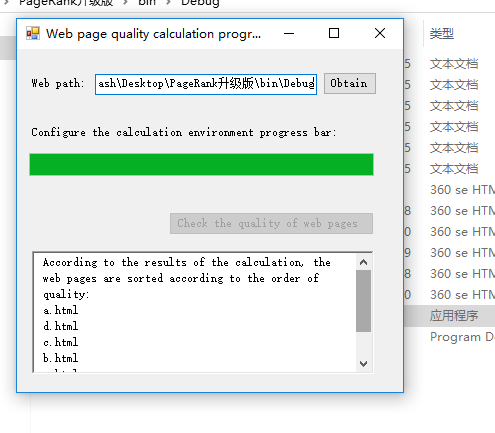
3.獲得網頁質量:

通過程式的排序已經將質量相當大小反饋給用戶,用戶可以選擇性的瀏覽網頁
我們用C語言的來驗證每個網頁的pr值是否真如此程式所言

(註意 – 是一個標誌,表示最終迭代的結果…) 由上到下依次為A~F的pr值,正如C#的程式排序所言,證明這個是合理的
------由於c#的代碼不是一兩張圖片就可以解釋的清楚的,所有有興趣的朋友可以一起探討和分享。
(這個程式是我才學習了C#寫的,如果有什麼不足或者錯誤之處請多多包涵)
需要源碼的朋友可以評論區或者私信我留下你們的郵件,我看到後會儘快發給你們源碼滴,大家一起進步一起學習


