
在序言中,我們提到函數式編程的兩大特征:無副作用、函數是第一公民。現在,我們先來深入第一個特征:無副作用。 無副作用是通過引用透明(Referential transparency)來定義的。如果一個表達式滿足將它替換成它的值,而程式的行為不變,則稱這個表達式是引用透明的。 現在,我們不妨進行一個嘗 ...
在序言中,我們提到函數式編程的兩大特征:無副作用、函數是第一公民。現在,我們先來深入第一個特征:無副作用。
無副作用是通過引用透明(Referential transparency)來定義的。如果一個表達式滿足將它替換成它的值,而程式的行為不變,則稱這個表達式是引用透明的。
現在,我們不妨進行一個嘗試:我們來實現一些函數,但是這次有一個限制:只能用無副作用的表達式。
先以素數判定為例子,我們要寫一個函數bool IsPrime(int n),它返回這個整數是不是素數。簡單起見,我們採用最朴素的方法:依次檢查2~n-1的整數,如果存在n的因數,則返回false,否則返回true.
這種問題的原始做法是使用迴圈,但是使用迴圈需要修改迴圈變數的值,從而產生副作用。
那怎麼辦了?有一個和迴圈關係緊密的概念——遞歸。遞歸不會改變變數的值,我們嘗試用遞歸實現。
直接對IsPrime遞歸似乎不太可行,我們需要寫一個輔助方法IsPrimeLoop。這個方法的參數除了n以外還有一個輔助參數acc,這個輔助參數起到類似迴圈變數的作用,它表示當前我們正在嘗試的因數。
那這個函數要怎麼實現呢?我們約定從小到大枚舉整數,那麼當acc == n時,迴圈就結束了,返回true。若acc != n,則迴圈繼續。接著我們需要判斷acc是不是n的因數,如果是,則n不是素數,返回false,否則繼續遞歸迴圈。
藉助這個輔助函數,我們只要調用IsPrimeLoop(n, 2)就可以判斷了。代碼如下:
private static bool IsPrimeLoop(int n, int acc) => (acc == n) || (n % acc != 0 && IsPrimeLoop(n, acc + 1)); public static bool IsPrime(int n) => n >= 2 && IsPrimeLoop(n, 2);
註意到,這裡的輔助函數IsPrimeLoop是私有的,因為這個函數是專門供IsPrime調用的,它的訪問範圍應該限制在IsPrime內。在C#6及以前,這是做不到的,只能把它設定為類私有儘可能減小訪問範圍。在C#7,我們可以利用內部函數進一步完善。
public static bool IsPrime(int n) { bool Loop(int acc) => (acc == n) || (n % acc != 0 && Loop(acc + 1)); return n >= 2 && Loop(2); }
這時我們的Loop函數可以省略掉參數n,而且Loop的訪問範圍被限制在了IsPrime內。這樣,我們就能在無副作用的前提下,實現素數的判定函數。
註意到,由於我們的IsPrime函數沒有用到任何有副作用的表達式,所以,我們可以保證調用IsPrime也不會產生任何副作用。一般的,如果一個函數滿足對它的調用一定是引用透明的,我們稱這個函數為純函數。
下麵我們來做一個練習,這裡我需要你用遞歸實現階乘函數int Fact(int n),當n>0時返回1*2*3*...*n的值,當n<=0時返回1,不考慮結果溢出的情況。你的實現不應該包含有副作用的表達式。
如果你完成了,請往下看。
下麵我給出兩個你可能的實現
public static int Fact(int n) => n <= 0 ? 1 : n * Fact(n - 1);
public static int Fact(int n) { int Loop(int acc, int result) => acc > n ? result : Loop(acc + 1, result * acc); return Loop(1, 1); }
當然,你的具體寫法可能有所不同,但基本上可以歸為兩類。一類是像第一個那樣,利用Fact(n)=n * Fact(n-1)進行遞歸;還有就是就像第二個那樣,通過遞歸來讓參數acc從1到n迴圈,並乘進一個結果變數result.
直觀來看,第一個函數會更“遞歸”一點,而第二個函數則更像用遞歸實現的迴圈。為了進一步揭析這兩個實現的區別,我們來手動展開一下兩個版本的Fact(5)的遞歸過程:
版本一:
Fact(5) = 5 * Fact(4)
= 5 * 4 * Fact(3)
= 5 * 4 * 3 * Fact(2)
= 5 * 4 * 3 * 2 * Fact(1)
= 5 * 4 * 3 * 2 * 1 * Fact(0)
= 5 * 4 * 3 * 2 * 1 * 1
= 120
版本二:
Fact(5) = Loop(1, 1)
= Loop(2, 1)
= Loop(3, 2)
= Loop(4, 6)
= Loop(5, 24)
= Loop(6, 120)
= 120
發現沒有?版本一的式子會逐漸變長,而版本二的式子長度則保持不變。這是因為,後者是尾遞歸。尾遞歸的定義為遞歸調用被立刻返回的遞歸。尾遞歸的特點是它理論上不需要額外的空間存儲遞歸信息,就像我們展開式子那樣,尾遞歸占用的空間是恆定的,而非尾遞歸調用則需額外的空間儲存信息。事實上,尾遞歸和迴圈是等價的,因為尾遞歸可以想象成跳轉到函數開頭,只不過這個“跳轉”是無副作用的。因此,我們可以用尾遞歸去實現迴圈,從而去除副作用。由於尾遞歸具有這種好處,我們通常儘可能的使用尾遞歸,只有在無法轉換成尾遞歸,或者遞歸層數不大時,才使用非尾遞歸。
註意到我前面提到尾遞歸理論上不需要額外空間,但是很多語言在實現尾遞歸的時候會消耗棧空間的。比如JVM的尾遞歸會消耗棧空間,一些諸如Scala等編譯到JVM的語言會將尾遞歸轉換成迴圈從而防止棧溢出。但是C#編譯器沒有這個操作,那.NET在進行尾遞歸時會消耗棧空間嗎?我們不妨來試一下。我的測試環境是.NET Core,使用之前定義的IsPrime函數,然後給它傳入int.MaxValue,運行。
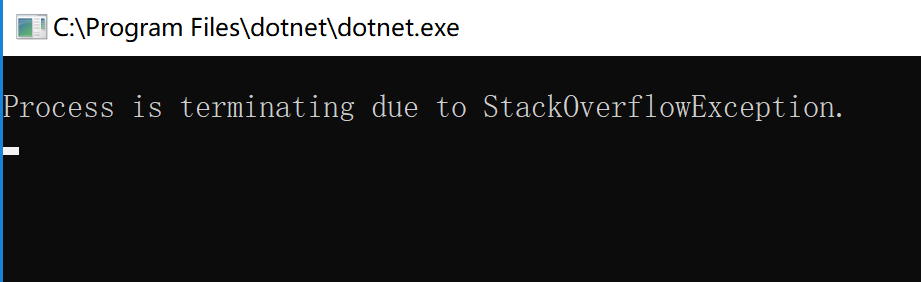
嗯,棧溢出了。
根據目前的實驗結果,.NET在實現尾遞歸時會消耗棧空間。但是我用的是Debug模式,那切換到Release模式會怎樣呢?
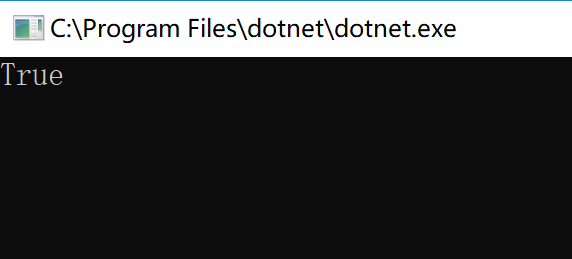
哈!沒有溢出!
從上面實驗可以看出,.NET Core在Debug模式下尾遞歸會消耗棧空間,Release模式不會。
因此,我們可以通過打開Release模式來避免尾遞歸產生棧溢出錯誤。
現在,遞歸相關的知識已經介紹完了。現在我們來講講遞歸的價值。
有的人覺得既然迴圈可以解決問題,那就沒必要花時間去學什麼遞歸;而有的人則覺得迴圈是魔鬼的,都應該改成遞歸。事實上,這兩種極端的想法都是錯誤的。
遞歸的價值在於它能保證你寫的函數是純函數,從而降低一些意外的副作用產生的可能性。還記得序言的那個例子嗎?那個程式就可以用尾遞歸實現來避免bug的產生。
當然,如果你要我寫一個階乘演算法,或者寫一個素數判斷演算法,我肯定用for迴圈。因為這個函數足夠簡單,我有自信做到,即使我的函數產生了副作用,但是這個副作用只是局部的,整個函數還是純的函數。
但是,當程式複雜時,尤其是產生閉包時,這些副作用會比較隱晦,此時,使用尾遞歸能降低代碼出錯的幾率。
尾遞歸還有一種好處:它能減少代碼邏輯上的複雜性。我見過有一些好幾重迴圈嵌套的程式,迴圈變數之間還相互依賴,邏輯非常複雜。但是,如果你把它改成尾遞歸,你就需要將迴圈轉為一個或多個遞歸函數,從而使得邏輯結構更加的清晰。
最後,用一句話總結,遞歸應該減少你的負擔,而不是成為你的負擔。
習題:
一、用尾遞歸改寫序言中提到的副作用產生bug的例子。
二、對於斐波那契數列數列fib(n)定義為:當n<=2時,fib(n)=1;當n>2時,fib(n)=fib(n-1)+fib(n-2)。分別用尾遞歸和非尾遞歸實現fib,並比較兩個實現的效率差異。你能解釋其中的原因嗎?


