
作業一、多項式的加減運算 1、設計要點與自我分析 我設計的類圖 老師建議類圖 我設計了兩個類來進行多項式的計算,類Polynomial進行多項式的存儲和輸入輸出,第二個類進行多項式加減運算。而加減運算的類裡面只有方法,而且都是靜態方法,沒有存儲變數,感覺這個設計還是有些問題。之後我也參考了一下別人的 ...
作業一、多項式的加減運算
1、設計要點與自我分析
我設計的類圖

複雜度分析圖

老師建議類圖
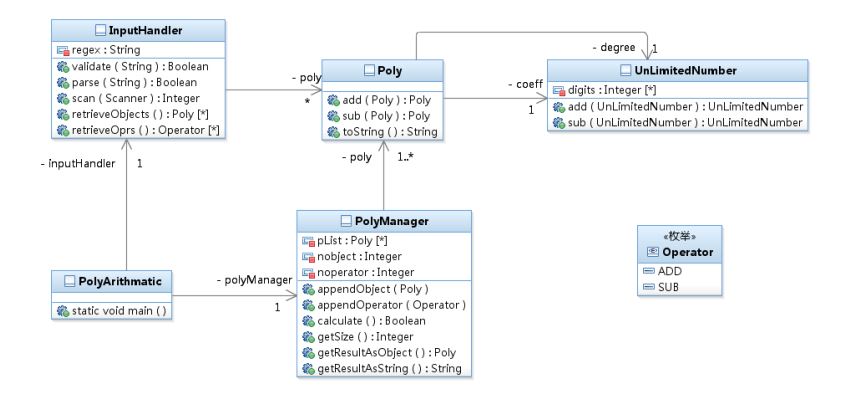
我設計了兩個類來進行多項式的計算,類Polynomial進行多項式的存儲和輸入輸出,第二個類進行多項式加減運算。而加減運算的類裡面只有方法,而且都是靜態方法,沒有存儲變數,感覺這個設計還是有些問題。之後我也參考了一下別人的代碼。
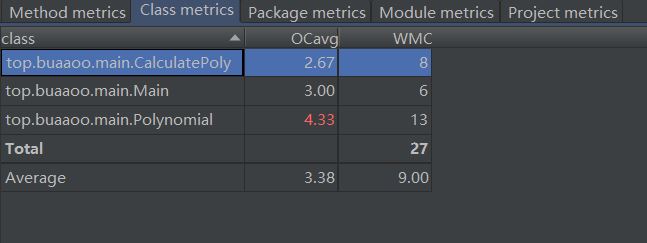
在Method Metrics中可以看到ev, iv, v這三欄,分別代指基本複雜度(Essential Complexity (ev(G))、模塊設計複雜度(Module Design Complexity (iv(G)))、Cyclomatic Complexity (v(G))圈複雜度。
ev(G)基本複雜度是用來衡量程式非結構化程度的,非結構成分降低了程式的質量,增加了代碼的維護難度,使程式難於理解。因此,基本複雜度高意味著非結構化程度高,難以模塊化和維護。實際上,消除了一個錯誤有時會引起其他的錯誤。
Iv(G)模塊設計複雜度是用來衡量模塊判定結構,即模塊和其他模塊的調用關係。軟體模塊設計複雜度高意味模塊耦合度高,這將導致模塊難於隔離、維護和復用。模塊設計複雜度是從模塊流程圖中移去那些不包含調用子模塊的判定和迴圈結構後得出的圈複雜度,因此模塊設計複雜度不能大於圈複雜度,通常是遠小於圈複雜度。
v(G)是用來衡量一個模塊判定結構的複雜程度,數量上表現為獨立路徑的條數,即合理的預防錯誤所需測試的最少路徑條數,圈複雜度大說明程式代碼可能質量低且難於測試和維護,經驗表明,程式的可能錯誤和高的圈複雜度有著很大關係。
Class metrics中兩欄分別為Ocavg(Average Operation Complexity)和WMC(Weighed method complexity)
在main函數中,我的基本複雜度較大較大,我定義了一個output的函數方法用於輸出結果,不過模塊化程度還算可以。
- 多項式的存儲:
我用的是一維數組來存儲多項式,下標代表的是多項式的次數,數組存儲的是多項式的繫數,這種存儲方法對於多項式加減法的操作很方便,但是浪費的空間大,因為很多繫數是0;而且存儲多項式加減式子的時候也開了大數組將所有數據裝進去,一次性進行計算,這樣也浪費了大量的空間。
參考了大佬的代碼,學習了一下如何管理多項式的存儲和加減:
1、專門設出一個類來存多項式的每一項,包括繫數和次數,然後開一個ArrayList<Object>來存儲這個類。
2、加減法操作,將所有項加入到原來的ArrayList裡面,然後在ArrayList裡面對指數相同的項進行合併操作,再進行對指數從小到大的排序,用了sort()函數。
2、所用知識
1. 去除空白字元
s = s.replaceAll("\\s*", "");2. 正則表達式的使用
1、使用group()捕獲組:
捕獲組是把多個字元當一個單獨單元進行處理的方法,它通過對括弧內的字元分組來創建。group(0)代表的是整個匹配的表達式,之後每遇到一個左括弧,group的索引值加一。
- public String group( )
返回上次匹配操作(比方說find( ))的group 0(整個匹配)
- public String group(int i)
返回上次匹配操作的某個group。如果匹配成功,但是沒能找到group,則返回null。
2、非貪婪匹配:
當“ ?”字元緊隨任何其他限定符(*、+、?、{n}、{n,}、{n,m}之後時,匹配模式是"非貪心的"。"非貪心的"模式匹配搜索到的、儘可能短的字元串,而預設的"貪心的"模式匹配搜索到的、儘可能長的字元串。
*、+限定符都是貪婪的,因為它們會儘可能多的匹配文字,只有在它們的後面加上一個?就可以實現非貪婪或最小匹配。
3、判斷兩個字元串內容是否相等
需要用str.equals()的方法判斷,而不能使用“==”號。
4、錯誤的捕捉,使用try-catch和throw
try{
... ...
}catch(IOException e){
//處理IO異常的代碼
}catch(NumberFormatException e){
//處理parseInt不能轉換時的異常代碼
}catch(StringIndexOutOfBoundsException e){
//處理數組越界的異常代碼
}catch(Exception e) {
//總異常(父類)
} 也可以自定義異常,如果不滿足某項條件則拋出異常
if(!m.find()){
throw new PolynomialError();
}5、結束進程
System.exit(0);
6、可以重寫toString()的方法返回多項式的值。
3、遇見BUG以及改正方法
1、正則表達式太長,在數據壓力大的時候可能會爆棧
我將整個多項式加減法的式子用正則表達式一次性匹配檢查格式是否正確,但由於表達式太長,數據壓力大而爆棧。應該逐個多項式進行匹配,逐個向後查找。
2、繫數相加的時候容易超出範圍
使用java異常處理語句進行異常的捕捉
3、輸出多項式的時候沒有判斷是否是輸出第一個大括弧,導致前面出現逗號。
加入第一次進入輸出迴圈的判斷。
4、在本題目的多項式匹配當中,可使用 **(^|\\+|-)(\\{.*?\\})**來匹配其中加減的操作項。
但是如果兩個加減項之間出現了非法字元,正則表達式會自動跳過非法字元去匹配下一項,要怎麼解決這個問題呢?我想到三種方法:
(1)將匹配成功的字元串刪除以後,用^從頭開始匹配。代碼如下:
String pattern = "^(^|\\+|-)(\\{.*?\\})";
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(line);
while (m.find()) {
System.out.println("Found value: " + m.group());
line = line.replace(m.group(),"");
m = r.matcher(line);
}(2)每次記錄匹配字元串的長度,然後依次累加,如果發現累加得到的字元串長度和讀到的m.start(0)索引值不一致,則中間有非法字元。
(3)用region(start,end)重設m的範圍。
4、Eclipse的使用總結
1. 導入工程
設置工作空間(Workspace)有明顯的層次結構。 項目在最頂級,項目裡頭可以有文件和文件夾。插件可以通過資源插件提供的API來管理工作空間的資源。
首先打開eclipse軟體,找到左上角File然後點擊,然後我們選擇Import,點擊Import
點擊Import後,會彈出Import視窗,然後找到General,點擊General左邊小三角,然後選擇Existing Projects into Workspace
有時候點導入文件會出現提示
Project is not a Java project.
有幾種情況:
package名字不相符:右鍵項目->Build Path來更改source folder的設置
eclipse 工程沒有build path,則在項目.project文件中添加
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>- JDK版本不對: 項目右鍵 -->properties-->Java Build Path-->Libraries 然後將JDK換成你當前的JDK版本
2、修改字元集
預設情況下 Eclipse 字元集為 GBK,但現在很多項目採用的是 UTF-8,這是我們就需要設置我們的 Eclipse 開發環境字元集為 UTF-8, 設置步驟如下:
在菜單欄選擇Window -> Preferences -> General -> Workspace -> Text file encoding ,在 Text file encoding 中點擊 Other,選擇 UTF-8。
3、調試快捷鍵
F11――進入DEBUG視圖
F5——進入:移動到下一個步驟,如果當前行有一個方法調用,該控制項將會跳轉到被調用方法的第一行執行。
F6——跳出:移動到下一行。如果在當前行有方法調用,那麼會直接移動到下一行執行。不會進入被調用方法體裡面。
F7——返回:從當前方法中跳出,繼續往下執行。
F8——移動到下一個斷點處執行。
作業二、電梯的簡單調度
1、設計要點與自我分析
邏輯結構圖: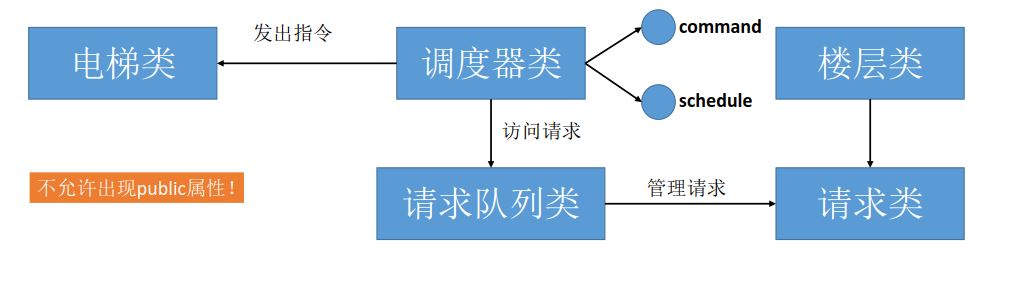
類圖: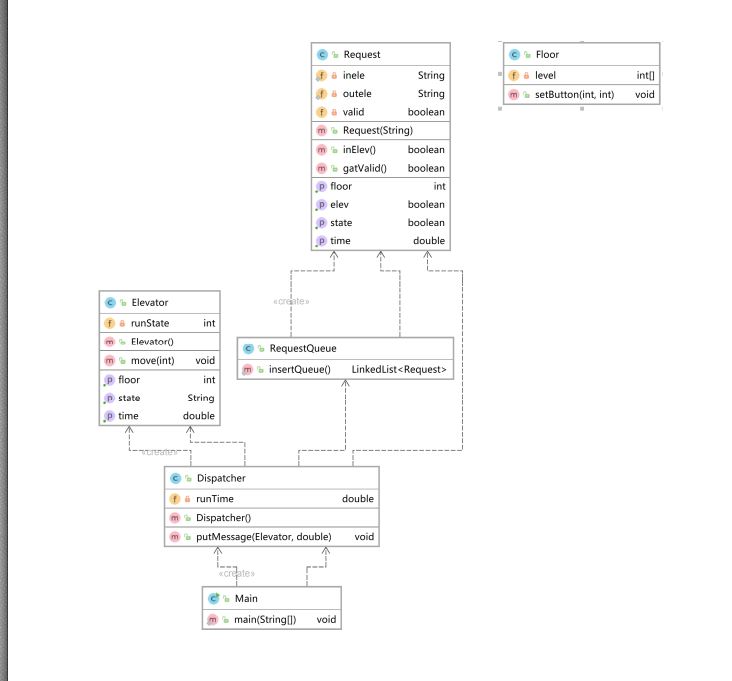
設計建議類圖: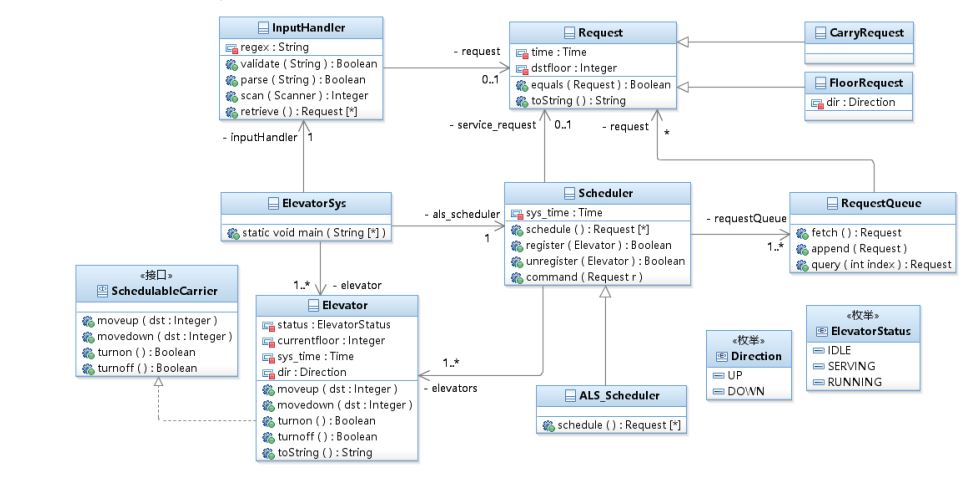
複雜度分析圖:
本次作業的設計要點是多個類進行協同,同時使用隊列進行調度。我將請求加入到請求隊列當中,由調度器從請求隊列中讀取請求對電梯類進行調度和操作,樓層類我沒有實際用上,這也是設計上的不均衡。其他幾個類職責比較分明,調度邏輯清晰。
可以看到我的RequestQueue類的複雜度較高,因為我在裡面大量用if語句來判斷出現的不同格式錯誤來輸出錯誤提示,導致複雜度升高。
2、所用知識
LinkedList的使用,由於本電梯使用的是隊列的結構,使用瞭如下幾種方法:
(1)q.offer(e) 在鏈表尾部插入元素
(2)q.peek() 獲取第一個元素
(3)q.remove(e) 刪除一個元素
(4)q.poll(e) 查詢並移除第一個元素
(5)遍歷鏈表:
//for迴圈遍歷
for(int i = 0; i < linkedList.size(); i++){
linkedList.get(i);
}//Foreach遍歷
for(Integer i : linkedList);//迭代器遍歷
Iterator<Integer> iterator = linkedList.iterator();
while(iterator.hasNext()){
iterator.next();
}但是迭代器遍歷和foreach遍歷的時候因為是動態刪除鏈表會發生線程錯誤,所以我用了for迴圈遍歷。
3、遇見BUG以及改正方法
我使用了LinkedList()來存儲請求,每次執行一次請求會遍歷鏈表看看有沒有同質請求,有的話進行刪除。但是刪除以後鏈表的總長度會改變,所以刪除以後要將索引值減一。在debug的過程中找出了這個錯誤,後來在公測的時候順利通過了。
我測試的同學沒有用正則表達式,全部用if-else判斷,程式容錯能力過差,導致公測全部沒有過。
作業三、具有捎帶功能的電梯調度
1、設計要點與自我分析
- 提高資源利用率是調度演算法設計的核心目標
- “順路捎帶”:在去響應一個請求的路途中可以把資源共用給順路可完成的請求
類圖:
複雜度分析:
老師推薦設計:
在第二次作業的基礎上,我用Scheduler類繼承了Dispatcher類,創建了電梯移動的介面。
我順路捎帶的思路是找到主請求,然後遍歷隊列後面可以被捎帶的請求,找到離主請求最近的請求執行,若超出主請求的執行時間,便執行主請求,然後選擇捎帶的第一條消息作為主請求。但是這個設計思路遇到了很多問題,後來參考了別人的思路。可以將每次所能找到捎帶方向上的最高樓層作為目標樓層,然後停靠中間的樓層,這樣的思路簡潔清晰,也省去了很多判斷的步驟。
可以看到我的Scheduler類複雜度十分高,因為我思路的問題,導致在這個類裡面有很多判斷條件的語句,整個程式十分冗雜。
2、所用知識
(1)類的繼承
使用繼承機制,增加一個子類來重寫第二次作業中的schedule方法,需要註意子類不能繼承父類的構造器,但是父類的構造器帶有參數的,則必須在子類的構造器中顯式地通過super關鍵字調用父類的構造器並配以適當的參數列表。 如果父類有無參構造器,則在子類的構造器中用super調用父類構造器不是必須的,如果沒有使用super關鍵字,系統會自動調用父類的無參構造器。
(2)使用interface來歸納電梯的運動方法。
(3)重寫toString()方法來獲得電梯運行狀態和時刻的觀察。
3、遇見BUG以及改正方法
在這次的作業中,由於我每次都是找到可捎帶請求的最小請求,但是在主請求更換的時候,我將主請求設為了可捎帶的最小請求,而可捎帶的最小請求在前一條捎帶請求的後面發出,這就造成了後發出的指令先執行了。參考了其他同學的捎帶思路,即找到當前方向上可捎帶的最高樓層進行停靠,可以簡化此問題。
其次就是輸出錯誤格式的問題,INVALID的輸出的是原請求,而我將請求的括弧換掉了,導致很多bug。
測試策略
一開始我是根據錯誤分支樹來構造測試用例,後來的作業中,我根據別人的代碼結構來構造測試用例,發現代碼中的邏輯錯誤和bug。
心得體會
作為剛接觸面向對象的小白,第一次作業佈置下來,就開始兩天速成Java,正則表達式,很多資料看得一臉懵逼,期間總是去打擾大佬,問一些十分基礎的問題。但在後面兩次作業中,對整個編寫流程開始熟練起來,也開始理解面向對象的編程思想。每次作業做完以後,也會參考一下別人的代碼,和自己的做一下對比,看看那些地方能更加簡潔的表達,更高效的處理,同時也感謝能將代碼分享給我的同學~
還有就是一定要仔細閱讀指導書,我就是因為指導書沒有好好看,導致程式出了很多bug,第一次作業由於輸出提示沒有#提示,掛滿了錯誤分支樹,可以說還是很絕望的。第三次的指導書和第二次的差不多,我又很粗淺地看了,差點漏掉了重要信息,第一條指令有限制。後來是在看討論區的討論才發現了這個問題。
前期的邏輯結構設計一定要清晰,否則無腦開始寫代碼真的會遇到特別多問題。
轉系之後感覺自己真的特別菜,改bug經常改到絕望,但還是真心感謝一些能夠和我交流的小伙伴。


