
一、storm何許人也?Storm 是Twitter的一個開源框架。Storm一個分散式的、容錯的實時計算系統,它被托管在GitHub上,遵循 Eclipse Public License 1.0。Storm是由BackType開發的實時處理系統,BackType現在已在Twitter麾下。GitH ...
一、storm何許人也?
Storm 是Twitter的一個開源框架。Storm一個分散式的、容錯的實時計算系統,它被托管在GitHub上,遵循 Eclipse Public License 1.0。Storm是由BackType開發的實時處理系統,BackType現在已在Twitter麾下。GitHub上的最新版本是Storm 0.9.0.1,基本是用Clojure寫的。
Twitter Storm集群錶面上類似於Hadoop集群,Hadoop上運行的是MapReduce Jobs,而Storm運行topologies;但是其本身有很大的區別,最主要的區別在於,Hadoop MapReduce Job運行最終會完結,而Storm topologies處理數據進程理論上是永久存活的,除非你將其Kill掉。
Storm集群中包含兩類節點:主控節點(Master Node)和工作節點(Work Node)。
二、其分別對應的角色如下:
1. 主控節點(Master Node)上運行一個被稱為Nimbus的後臺程式,它負責在Storm集群內分發代碼,分配任務給工作機器,並且負責監控集群運行狀態。Nimbus的作用類似於Hadoop中JobTracker的角色。
2. 每個工作節點(Work Node)上運行一個被稱為Supervisor的後臺程式。Supervisor負責監聽從Nimbus分配給它執行的任務,據此啟動或停止執行任務的工作進程。每一個工作進程執行一個Topology的子集;一個運行中的Topology由分佈在不同工作節點上的多個工作進程組成。
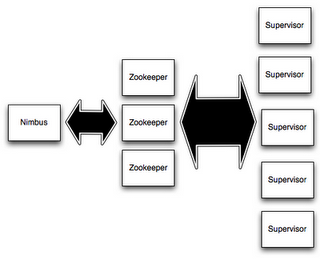
Nimbus和Supervisor節點之間所有的協調工作是通過Zookeeper集群來實現的。此外,Nimbus和Supervisor進程都是快速失敗(fail-fast)和無狀態(stateless)的;Storm集群所有的狀態要麼在Zookeeper集群中,要麼存儲在本地磁碟上。這意味著你可以用kill -9來殺死Nimbus和Supervisor進程,它們在重啟後可以繼續工作。這個設計使得Storm集群擁有不可思議的穩定性。
在Storm集群上要實現實時計算,需要創建Topologies。一個Topology是一個計算的曲線圖。Topology中的每個節點包含處理邏輯,並且節點之間的鏈路表示數據如何應圍繞節點之間傳遞。
運行一個Topology比較簡單,首先,你打包所有的代碼和依賴關係的包打成一個jar包。然後,您運行如下命令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2
這裡運行一個包含arg1和arg2兩個參數的backtype.storm.MyTopology類。main方法定義Topology以及提交到Nimbus,storm jar部分連接Nimbus以及上傳jar包到集群。
由於Topology的定義是Thirf結構,並且Nimbus是一個Thirf 服務,所以你可以使用任何語言創建以及提交Topology。
Storm是一個實時流處理框架,那麼它的抽象核心當然就是流。 Storm也可被用於“連續計算”(continuous computation),對數據流做連續查詢,在計算時就將結果以流的形式輸出給用戶。它還可被用於“分散式RPC”,以並行的方式運行昂貴的運算。 Storm的主工程師Nathan Marz表示:
Storm可以方便地在一個電腦集群中編寫與擴展複雜的實時計算,Storm之於實時處理,就好比 Hadoop之於批處理。Storm保證每個消息都會得到處理,而且它很快——在一個小集群中,每秒可以處理數以百萬計的消息。更棒的是你可以使用任意編程語言來做開發。
三、Storm的主要特點如下:
1)簡單的編程模型:類似於Mapreduce降低了並行批處理複雜性,Storm降低了進行實時處理的複雜性。
2)可以使用各種編程語言:你可以在Storm之上使用各種編程語言。預設支持Clojure、Java、Ruby和Python。要增加對其他語言的支持,只需實現一個簡單的Storm通信協議即可。
3)容錯性:Storm會管理工作進程和節點的故障。
4)水平擴展:計算是在多個線程、進程和伺服器之間並行進行的。
5)可靠的消息處理:Storm保證每個消息至少能得到一次完整處理。任務失敗時,它會負責從消息源重試消息。
6)快速:系統的設計保證了消息能得到快速的處理,使用ZeroMQ作為其用底層消息隊列。
7)本地模式:Storm有一個“本地模式”,可以在處理過程中完全模擬Storm集群。這讓你可以快速進行開發和單元測試。
四、Storm集群架構
Storm集群採用主從架構方式,主節點是Nimbus,從節點是Supervisor,有關調度相關的信息存儲到ZooKeeper集群中,架構如下圖所示:
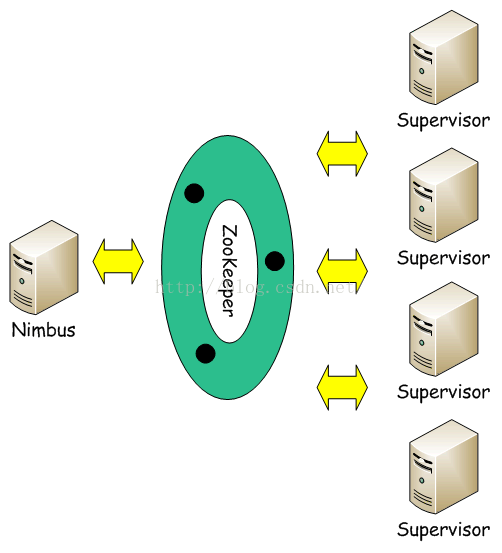
具體描述,如下所示:
Nimbus
Storm集群的Master節點,負責分發用戶代碼,指派給具體的Supervisor節點上的Worker節點,去運行Topology對應的組件(Spout/Bolt)的Task。
Supervisor
Storm集群的從節點,負責管理運行在Supervisor節點上的每一個Worker進程的啟動和終止。通過Storm的配置文件中的supervisor.slots.ports配置項,可以指定在一個Supervisor上最大允許多少個Slot,每個Slot通過埠號來唯一標識,一個埠號對應一個Worker進程(如果該Worker進程被啟動)。
ZooKeeper
用來協調Nimbus和Supervisor,如果Supervisor因故障出現問題而無法運行Topology,Nimbus會第一時間感知到,並重新分配Topology到其它可用的Supervisor上運行。
Stream Groupings
Storm中最重要的抽象,應該就是Stream grouping了,它能夠控制Spot/Bolt對應的Task以什麼樣的方式來分發Tuple,將Tuple發射到目的Spot/Bolt對應的Task,如下圖所示:
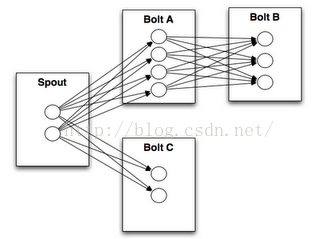
目前,Storm Streaming Grouping支持如下幾種類型:
Shuffle Grouping:隨機分組,跨多個Bolt的Task,能夠隨機使得每個Bolt的Task接收到大致相同數目的Tuple,但是Tuple不重覆
Fields Grouping:根據指定的Field進行分組 ,同一個Field的值一定會被髮射到同一個Task上
Partial Key Grouping:與Fields grouping 類似,根據指定的Field的一部分進行分組分發,能夠很好地實現Load balance,將Tuple發送給下游的Bolt對應的Task,特別是在存在數據傾斜的場景,使用 Partial Key grouping能夠更好地提高資源利用率
All Grouping:所有Bolt的Task都接收同一個Tuple(這裡有複製的含義)
Global Grouping:所有的流都指向一個Bolt的同一個Task(也就是Task ID最小的)
None Grouping:不需要關心Stream如何分組,等價於Shuffle grouping
Direct Grouping:由Tupe的生產者來決定發送給下游的哪一個Bolt的Task ,這個要在實際開發編寫Bolt代碼的邏輯中進行精確控制
Local or Shuffle Grouping:如果目標Bolt有1個或多個Task都在同一個Worker進程對應的JVM實例中,則Tuple只發送給這些Task
另外,Storm還提供了用戶自定義Streaming Grouping介面,如果上述Streaming Grouping都無法滿足實際業務需求,也可以自己實現,只需要實現backtype.storm.grouping.CustomStreamGrouping介面,該介面定義瞭如下方法:
List<Integer> chooseTasks(int taskId, List<Object> values)
上面幾種Streaming Group的內置實現中,最常用的應該是Shuffle Grouping、Fields Grouping、Direct Grouping這三種,使用其它的也能滿足特定的應用需求。
感謝您閱讀本文章,更多內容或支持推薦您點擊 上海大數據培訓
轉載請說明出處!


