
三範式定義 1NF:每個數據項都是最小單元,不可分割,其實就是確定行列之後只能對應一個數據。 2NF:每一個非主屬性完全依賴於候選碼(屬性組的值能唯一的標識一個元組,但是其子集不可以)。 3NF:每一個非主屬性既不傳遞依賴於主碼,也不部分依賴於主碼。 BCNF:主屬性(候選碼中的某一個屬性)內部也 ...
三範式定義
1NF:每個數據項都是最小單元,不可分割,其實就是確定行列之後只能對應一個數據。 2NF:每一個非主屬性完全依賴於候選碼(屬性組的值能唯一的標識一個元組,但是其子集不可以)。 3NF:每一個非主屬性既不傳遞依賴於主碼,也不部分依賴於主碼。 BCNF:主屬性(候選碼中的某一個屬性)內部也不能部分或傳遞依賴於碼。 4NF :沒有多值依賴。 事實上完全的範式化和完全的反範式化都是實驗室才有的東西,在實際應用中經常混合使用。存儲引擎
資料庫存儲引擎
MySQL中的數據用各種不同的技術存儲在文件(或者記憶體)中。這些技術中的每一種技術都使用不同的存儲機制、索引技巧、鎖定水平並且最終提供廣泛的不同的功能和能力。存儲引擎說白了就是如何存儲數據、如何為存儲的數據建立索引和如何更新、查詢數據等技術的實現方法。
MySQL中MyISAM與InnoDB的區別,面試題:至少五點
- InnoDB支持事務,MyISAM不支持事務。
- InnoDB支持行級鎖,MyISAM支持表級鎖。
- InnoDB支持MVCC, MyISAM不支持。
- InnoDB支持外鍵,MyISAM不支持。
- InnoDB不支持全文索引,MyISAM支持。
資料庫ACID+事務+隔離級別
(1)原子性:事務中的操作是一個不可分割的整體單元,要麼全部都做,要麼全部不做。
(2)一致性:事務執行前後資料庫都必須處於一致性狀態。
(3)隔離性:通常來說,一個事物所做的修改在最終提交之前對其餘事務是不可見的。這裡就涉及到事務的隔離級別的問題了。
(4)持久性:一旦事務提交完成,修改就是永久的,即使伺服器宕機也不會影響到。
事務
我們可以通過設置 AUTOCOMMIT 變數來啟動或則禁用自動提交模式。 設置1表示啟用AUTOCOMMIT,0表示禁用AUTOCOMMIT。
MySQL中預設的是採取自動提交模式(AutoCommit),
- 只要不是顯示的開啟一個事務,每個查詢操作都被當做一個事務執行提交的操作。
- 顯示的開啟一個事務開啟,當用戶執行commit命令時當前事務提交。從用戶執行start transaction命令到用戶執行commit命令之間的一系列操作為一個完整的事務周期。若不執行commit命令,系統則預設事務回滾。
事務併發帶來的數據問題
- 臟讀:事務A讀取了事務B更新的數據,然後B回滾操作,那麼A讀取到的數據是臟數據
- 不可重覆讀:事務 A 多次讀取同一數據,事務 B 在事務A多次讀取的過程中,對數據作了更新並提交,導致事務A多次讀取同一數據時,結果 不一致。
- 幻讀:系統管理員A將資料庫中所有學生的成績從具體分數改為ABCDE等級,但是系統管理員B就在這個時候插入了一條具體分數的記錄,當系統管理員A改結束後發現還有一條記錄沒有改過來,就好像發生了幻覺一樣,這就叫幻讀。
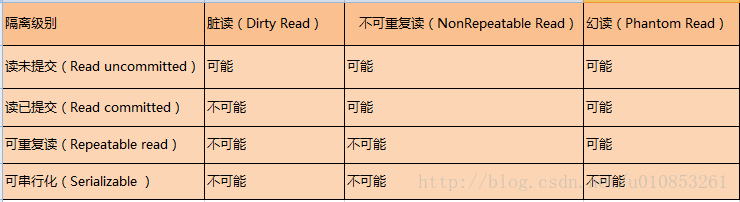
隔離級別
隔離級別(isolation level),是指事務與事務之間的隔離程度。
Read Uncommitted(未提交讀):在該隔離級別,所有事務都可以看到其他未提交事務的執行結果。讀取未提交的數據,也被稱之為臟讀(Dirty Read)。該級別用的很少。
Read Committed(提交讀):一個事務只能看見已經提交事務所做的改變。這種隔離級別也支持不可重覆讀(Nonrepeatable Read),同一事務的其他實例在該實例處理其間可能會有新的commit,所以同一select查詢可能返回不同結果。
Repeatable Read(可重覆讀)MySQL的預設事務隔離級別,它確保同一事務的多個實例在併發讀取數據時,會看到同樣的數據行。導致另一個棘手的問題:幻讀 (Phantom Read)。InnoDB和Falcon存儲引擎通過多版本併發控制(MVCC)機制解決了該問題。
Serializable(可串列化)這是最高的隔離級別,它強制事務都是串列執行的,使之不可能相互衝突,從而解決幻讀問題。換言之,它是在每個讀的數據行上加上共用鎖。在這個級別,可能導致大量的超時現象和鎖競爭。
MySQL索引
在mysql中索引是在存儲引擎層實現的,不同的存儲引擎索引的實現方式不同。
常用的有兩類BTree和哈希索引Hash、全文索引、空間數據索引RTree
Btree索引:支持全值索引、匹配最左首碼(搜索時註意條件的順序,否則不適用索引)、匹配列首碼、精確匹配列等。
哈希索引:只有精確匹配所有列的查詢才有效。只要Memory支持哈希索引(非唯一哈希索引,相同的索引會以鏈表的形式存儲在索引中)
空間數據索引(R-Tree):無需首碼查詢,從所有維度查詢數據。
全文檢索: 查找文本中的關鍵詞,類似於搜索引擎做的事情。
日誌
錯誤日誌:記錄了當 mysqld 啟動和停止時,以及伺服器在運行過程中發生任何嚴重錯誤時的相關信息。 二進位文件:記錄了所有的 DDL(數據定義語言)語句和 DML(數據操縱語言)語句,不包括數據查詢語句。語句以“事件”的形式保存,它描述了數據的更改過程。(定期刪除日誌是 DBA 維護 MySQL 數據 庫的一個重要工作內容。) 查詢日誌:記錄了客戶端的所有語句,格式為純文本格式,可以直接進行讀取。(log 日誌中記錄了所有資料庫的操作,對於訪問頻繁的系統,此日誌對系統性能的影響較 大,建議關閉)。 慢查詢日誌:慢查詢日誌記錄了包含所有執行時間超過參數long_query_time(單位:秒)所設置值的 SQL 語句的日誌。(純文本格式)MySQL日誌文件之錯誤日誌和慢查詢日誌詳解 日誌文件小結:- 系統故障時,建議首先查看錯誤日誌,以幫助用戶迅速定位故障原因。
- 記錄數據的變更、數據的備份、數據的複製等操作時,打開二進位日誌。預設不記錄此日誌,建議通過--log-bin 選項將此日誌打開。
- 如果希望記錄資料庫發生的任何操作,包括 SELECT,則需要用--log 將查詢日誌打開, 此日誌預設關閉,一般情況下建議不要打開此日誌,以免影響系統整體性能。
- 查看系統的性能問題, 希望找到有性能問題的SQL語 句,需要 用 --log-slow-queries 打開慢查詢日誌。對於大量的慢查詢日誌,建議使用 mysqldumpslow 工具 來進行彙總查看。
視圖
視圖最簡單的實現方法是把select語句的結果存放到臨時表中,
- 視圖是一個虛表,建立在存在的表數據基礎上。
- 在提升性能能力不強,更大的作用是專註於邏輯。
- 在一定情況下不能採用更好的查詢優化查詢性能。
存儲過程
存儲過程類似於代碼中的函數,只能處理特定的任務。
存儲過程的優點:
- 能夠將代碼封裝起來,保存在資料庫中,編程語言可以進行調用。
- 存儲過程是一個預編譯的代碼塊,已經完成瞭解析、預處理、查詢優化過程可以直接執行。
- 一個存儲過程替代大量T_SQL語句 ,可以降低網路通信量,提高通信速率。
存儲過程的缺點:
- 每個資料庫的存儲過程語法幾乎都不一樣,十分難以維護(不通用)。
- 業務邏輯放在資料庫上,難以迭代。


