
項目背景 每個系統都有日誌,當系統出現問題時,需要通過日誌解決問題 當系統機器比較少時,登陸到伺服器上查看即可滿足 當系統機器規模巨大,登陸到機器上查看幾乎不現實 當然即使是機器規模不大,一個系統通常也會涉及到多種語言的開發,拿我們公司來說,底層是通過c++開發的,而也業務應用層是通過Python開 ...
項目背景
- 每個系統都有日誌,當系統出現問題時,需要通過日誌解決問題
- 當系統機器比較少時,登陸到伺服器上查看即可滿足
- 當系統機器規模巨大,登陸到機器上查看幾乎不現實
當然即使是機器規模不大,一個系統通常也會涉及到多種語言的開發,拿我們公司來說,底層是通過c++開發的,而也業務應用層是通過Python開發的,並且即使是C++也分了很多級別應用,python這邊同樣也是有多個應用,那麼問題來了,每次系統出問題了,如何能夠迅速查問題? 好一點的情況可能是python應用層查日誌發現是系統底層處理異常了,於是又叫C++同事來查,如果C++這邊能夠迅速定位出錯誤告知python層這邊還好,如果錯誤好排查,可能就是各個開發層的都在一起查到底是哪裡引起的。當然可能這樣說比較籠統,但是卻引發了一個問題:
- 當系統出現問題後,如何根據日誌迅速的定位問題出在一個應用層?
- 在平常的工作中如何根據日誌分析出一個請求到系統主要在那個應用層耗時較大?
- 在平常的工作中如何獲取一個請求到達系統後在各個層測日誌彙總?
針對以上問題,我們想要實現的一個解決方案是:
- 把機器上的日誌實時收集,統一的存儲到中心系統
- 然後再對這些日誌建立索引,通過搜索即可以找到對應日誌
- 通過提供界面友好的web界面,通過web即可以完成日誌搜索
關於實現這個系統時可能會面臨的問題:
- 實時日誌量非常大,每天幾十億條(雖然現在我們公司的系統還沒達到這個級別)
- 日誌準實時收集,延遲控制在分鐘級別
- 能夠水平可擴展
關於日誌收集系統,業界的解決方案是ELK

ELK的解決方案是通用的一套解決方案,所以不免就會產生以下的幾個問題:
- 運維成本高,每增加一個日誌收集,都需要手動修改配置
- 監控缺失,無法準確獲取logstash的狀態
- 無法做定製化開發以及維護
針對這種情況,其實我們想要的系統是agent可以動態的獲取某個伺服器我們需要監控哪些日誌
以及那些日誌我們需要收集,並且當我們需要收集日誌的伺服器下線了,我們可以動態的停止收集
當然這些實現的效果最終也是通過web界面呈現。
日誌收集系統設計
主要的架構圖為
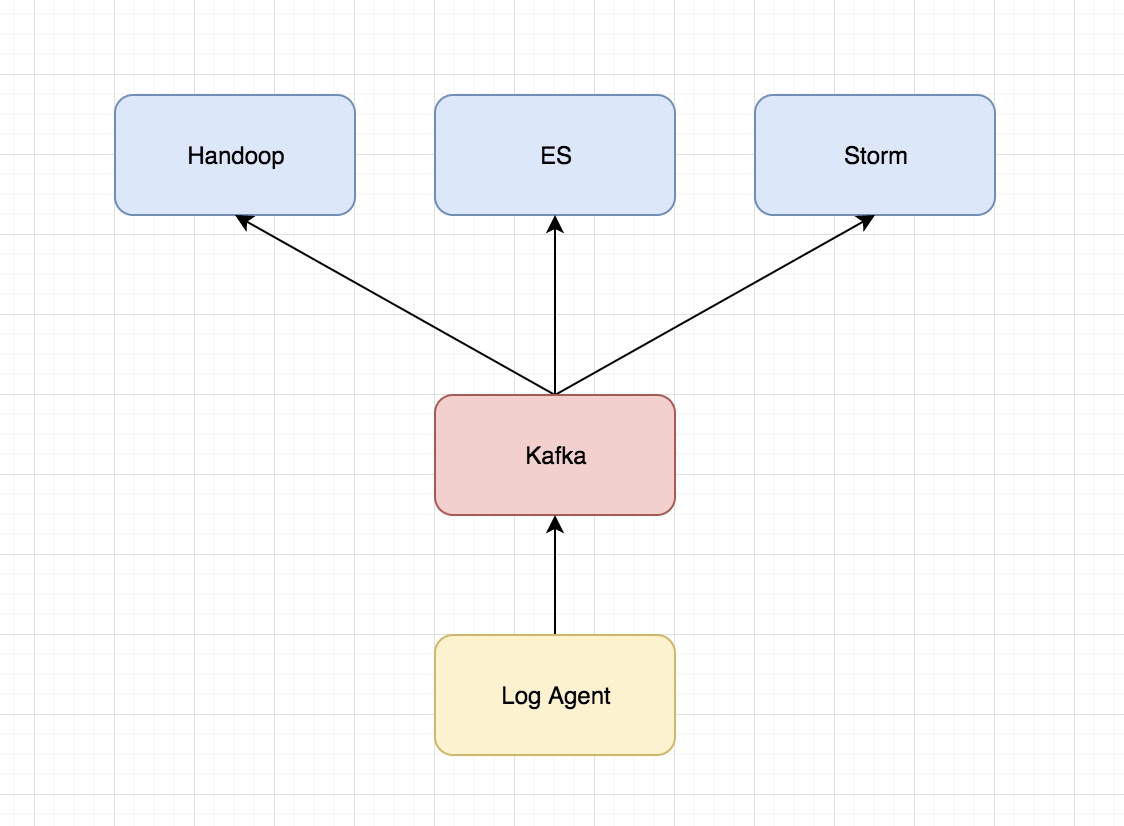
關於各個組件的說明:
- Log Agent,日誌收集客戶端,用來收集伺服器上的日誌
- Kafka,高吞吐量的分散式隊列,linkin開發,apache頂級開源項目
- ES,elasticsearch,開源的搜索引擎,提供基於http restful的web介面
- Hadoop,分散式計算框架,能夠對大量數據進行分散式處理的平臺
關於Kakfa的介紹
Apache Kafka是一個分散式發佈 - 訂閱消息系統和一個強大的隊列,可以處理大量的數據,並使您能夠將消息從一個端點傳遞到另一個端點。 Kafka適合離線和線上消息消費。 Kafka消息保留在磁碟上,併在群集內複製以防止數據丟失。 Kafka構建在ZooKeeper同步服務之上。 它與Apache Storm和Spark非常好地集成,用於實時流式數據分析。
註:這裡關於Kafka並不會介紹太多,只是對基本的內容和應用場景的說明,畢竟展開來說,這裡的知識也是費非常多的
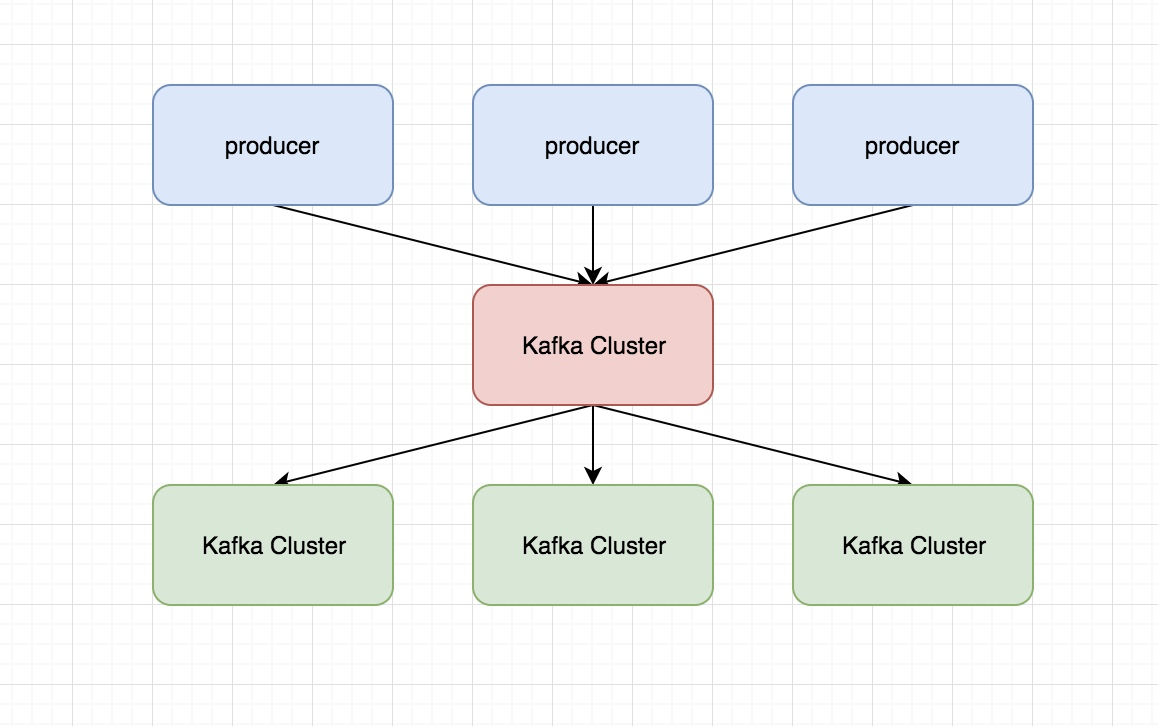
Kafka中有幾個基本的消息術語需要瞭解:
- Kafka將消息以topic為單位進行歸納。
- 將向Kafka topic發佈消息的程式成為producers.
- 將預訂topics並消費消息的程式成為consumer.
- Kafka以集群的方式運行,可以由一個或多個服務組成,每個服務叫做一個broker.
Kafka的優點:
- 可靠性 - Kafka是分散式,分區,複製和容錯的。
- 可擴展性 - Kafka消息傳遞系統輕鬆縮放,無需停機。
- 耐用性 - Kafka使用分散式提交日誌,這意味著消息會儘可能快地保留在磁碟上,因此它是持久的。
- 性能 - Kafka對於發佈和訂閱消息都具有高吞吐量。 即使存儲了許多TB的消息,它也保持穩定的性能。
Kafka非常快,並保證零停機和零數據丟失。
Kafka的應用場景:
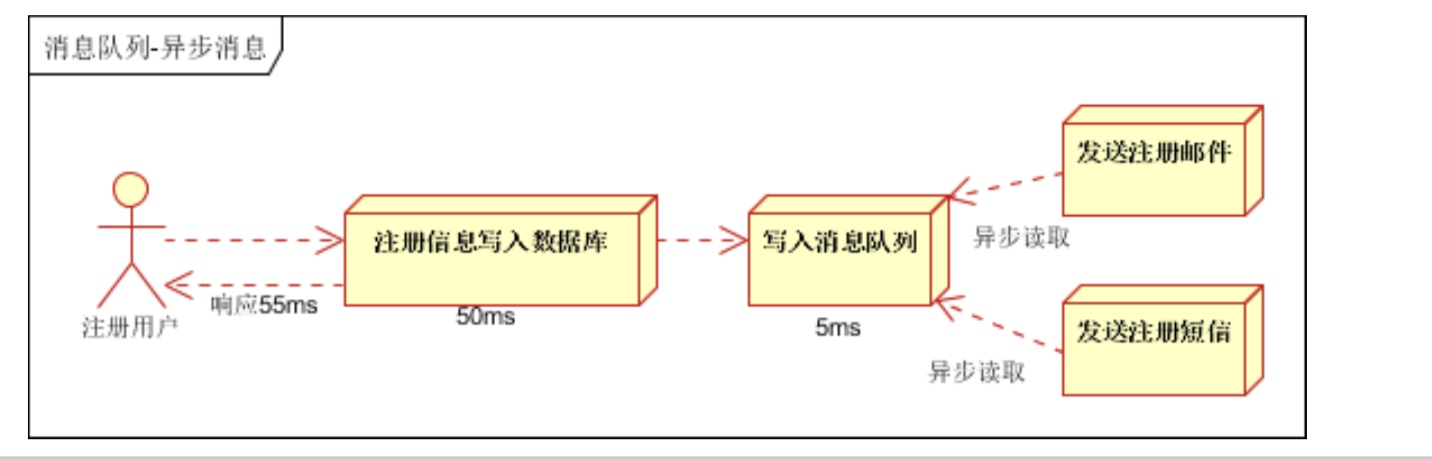
- 非同步處理, 把非關鍵流程非同步化,提高系統的響應時間和健壯性

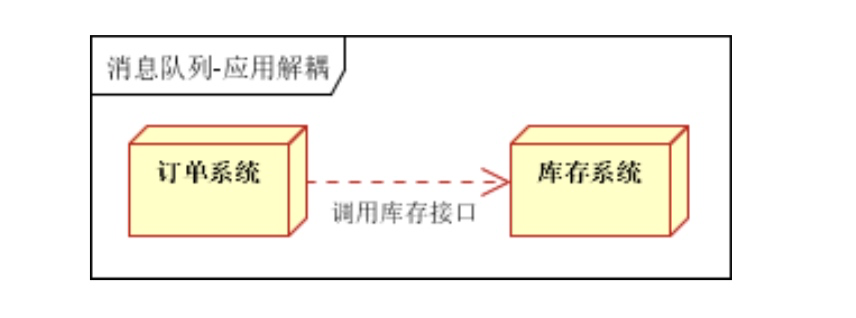
- 應用解耦,通過消息隊列

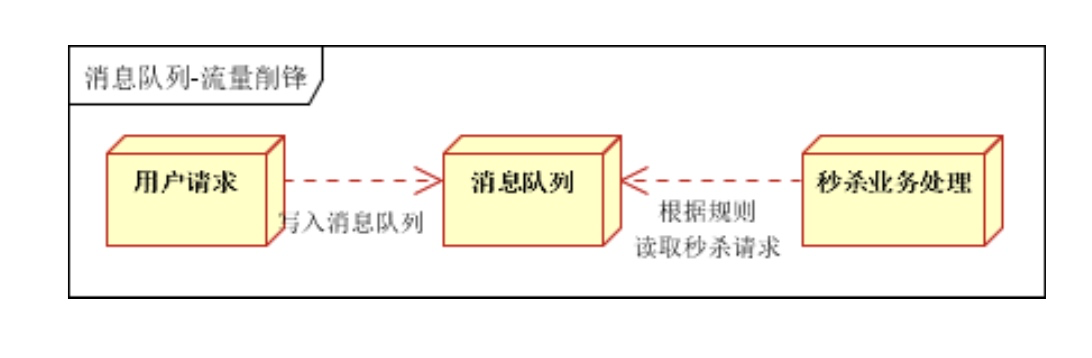
- 流量削峰
關於ZooKeeper介紹
ZooKeeper是一種分散式協調服務,用於管理大型主機。在分散式環境中協調和管理服務是一個複雜的過程。ZooKeeper通過其簡單的架構和API解決了這個問題。ZooKeeper允許開發人員專註於核心應用程式邏輯,而不必擔心應用程式的分散式特性。
Apache ZooKeeper是由集群(節點組)使用的一種服務,用於在自身之間協調,並通過穩健的同步技術維護共用數據。ZooKeeper本身是一個分散式應用程式,為寫入分散式應用程式提供服務。
ZooKeeper主要包含幾下幾個組件:
- Client(客戶端):我們的分散式應用集群中的一個節點,從伺服器訪問信息。對於特定的時間間隔,每個客戶端向伺服器發送消息以使伺服器知道客戶端是活躍的。類似地,當客戶端連接時,伺服器發送確認碼。如果連接的伺服器沒有響應,客戶端會自動將消息重定向到另一個伺服器。
- Server(伺服器):伺服器,我們的ZooKeeper總體中的一個節點,為客戶端提供所有的服務。向客戶端發送確認碼以告知伺服器是活躍的。
- Ensemble:ZooKeeper伺服器組。形成ensemble所需的最小節點數為3。
- Leader: 伺服器節點,如果任何連接的節點失敗,則執行自動恢復。Leader在服務啟動時被選舉。
- Follower:跟隨leader指令的伺服器節點。
ZooKeeper的應用場景:
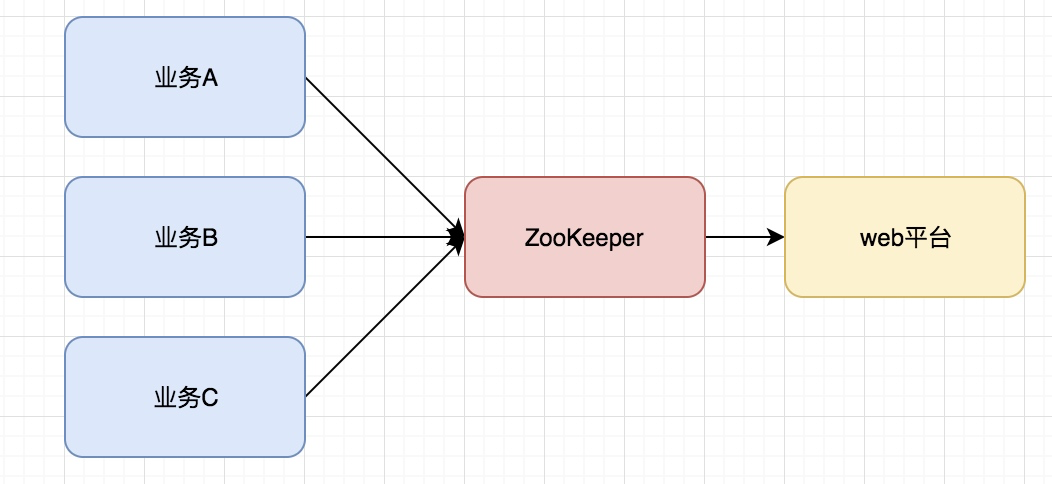
- 服務註冊&服務發現

- 配置中心
- 分散式鎖
Zookeeper是強一致的多個客戶端同時在Zookeeper上創建相同znode,只有一個創建成功
關於Log Agent
這個就是我們後面要通過代碼實現的一步分內容,主要實現的功能是:
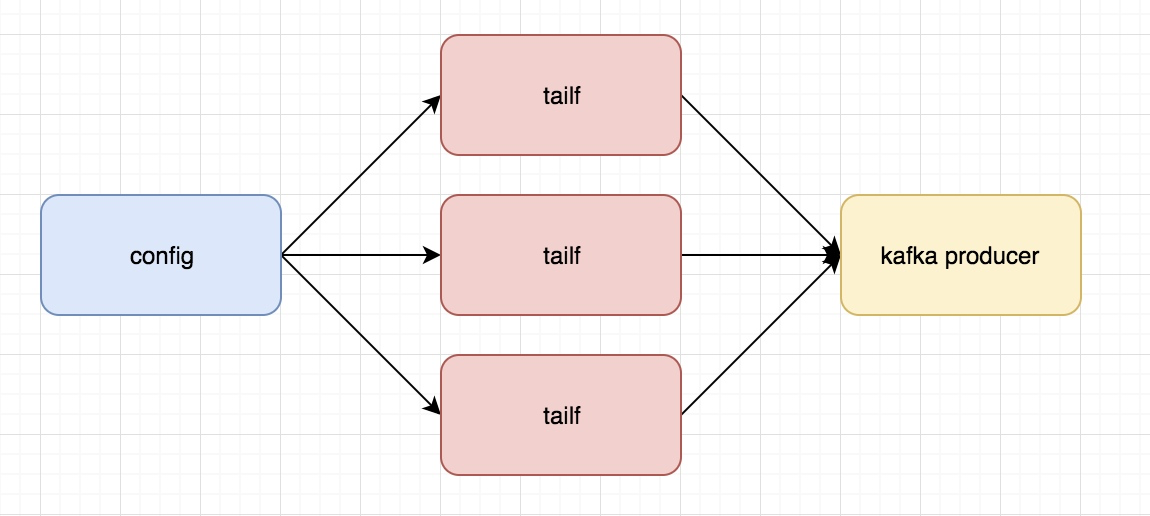
類似於我們在linux下通過tail的方法讀日誌文件,講讀取的內容發給Kafka
這裡需要知道的是,我們這裡的tailf是可以動態變化的,當配置文件發生變化是,可以通知我們程式自動增加需要增加的tailf去獲取相應的日誌併發給kafka producer
主要由一下幾部目錄組成:
- Kafka
- tailf
- configlog
小結
以上是對整個要開發的系統的一個總的概括,以及架構的一個構建,並且各個組件的實現,接下來會一個一個實現每個部分的功能,下一篇文章會實現上述組件中log Agent的開發


