
jdk1.8.0_144 HashMap作為最常用集合之一,繼承自AbstractMap。JDK8的HashMap實現與JDK7不同,新增了紅黑樹作為底層數據結構,結構變得複雜,效率變得更高。為滿足自身需要,也重新實現了很多AbstractMap中的方法。本文會圍繞HashMap,詳細探討HashM ...
jdk1.8.0_144
HashMap作為最常用集合之一,繼承自AbstractMap。JDK8的HashMap實現與JDK7不同,新增了紅黑樹作為底層數據結構,結構變得複雜,效率變得更高。為滿足自身需要,也重新實現了很多AbstractMap中的方法。本文會圍繞HashMap,詳細探討HashMap的底層數據結構、擴容機制、併發環境下的死迴圈問題等。
JDK8同JDK7一樣對Map.Entry進行了重新實現,改了個名字叫——Node,我想這是因為在紅黑樹中更方便理解,方法和JDK7大體相同只是取消了幾個方法。並且此時的Node節點(也就是Entry)結構更加完善:
1 static class Node<K,V> implements Map.Entry<K,V> { 2 final int hash; //節點hash值 3 final K key; //key值 4 V value; //value值 5 Node<K,V> next; //指向的下一個節點 6 7 //省略,由於JDK8的Map介面新增了幾個compare比較的方法,Node直接就繼承了 8 9 }
Node作為HashMap維護key-value的內部數據結構比較簡單,下麵是HashMap重新實現Map的方法。
public int size()
HashMap並沒有繼承AbstractMap的size方法,而是重寫了此方法。HashMap在類中定義了一個size變數,再此處直接返回size變數而不用調用entrySet方法返回集合再計算。可以猜測這個size變數是當插入一個key-value鍵值對的時候自增。
public boolean isEmpty()
判斷size變數是否0即可。
public boolean containsKey(Object key)
AbstractMap通過遍歷Entry節點的方式實現了這個方法,顯然HashMap覺得效率太低並沒有復用而是重寫了這個方法。
JDK8的HashMap底層數據結構引入了紅黑樹,它的實現要比JDK7略微複雜,我們先來看JDK7關於這個方法的實現。
1 //JDK7,HashMap#containsKey 2 public boolean containsKey(Object key) { 3 return getEntry(key) != null; //調用getEntry方法 4 }
getEntry實現的思路也比較簡單,由於JDK7的HashMap是數組+鏈表的數據結構,當key的hash值衝突的時候使用鏈地址法直接加到衝突地址Entry的next指針行程鏈表即可。所以getEntry方法的思路也是先計算key的hash值,計算後再找到它在散列表的下標,找到過再遍歷這個位置的鏈表返回結果即可。
JDK8加入了紅黑樹,在鏈表的個數達到閾值8時會將鏈表轉換為紅黑樹,如果此時是紅黑樹,則不能通過遍歷鏈表的方式尋找key值,所以JDK8對該方法進行了改進主要是需要遍歷紅黑樹,有關紅黑樹的具體演算法在此不多介紹。
1 //JDK8,HashMap#containsKey 2 public boolean containsKey(Object key) { 3 return getNode(hash(key), key) != null; //JDK8中新增了一個getNode方法,且將key的hash值計算好後作為參數傳遞。 4 } 5 //HashMap#getNode 6 final Node<K,V> getNode(int hash, Object key) { 7 //此方法相比較於JDK7中的getEntry基本相同,唯一不同的是發現key值衝突過後會通過“first instanceof TreeNode”檢查此時是否是紅黑樹結構。如果是紅黑樹則會調用getTreeNode方法在紅黑樹上進行查詢。如果不是紅黑樹則是鏈表結構,遍歷鏈表即可。 8 }
public boolean containsValue(Object value)
遍歷散列表中的元素
public V get(Object key)
在JDK8中get方法調用了containsKey的方法getNode,這點和JDk7的get方法中調用getEntry方法類似。
- 將參數key的hash值和key作為參數,調用getNode方法;
- 根據(n - 1) & hash(key)計算key值所在散列桶的下標;
- 取出散列桶中的key與參數key進行比較:
3.1 如果相等則直接返回Node節點;
3.2 如果不相等則判斷當前節點是否有後繼節點:
3.2.1 判斷是否是紅黑樹結構,是則調用getTreeNode查詢鍵值為key的Node 節點;
3.2.2 如果是鏈表結構,則遍歷整個鏈表。
public V put(K key, V value)
這個方法最為關鍵,插入key-value到Map中,在這個方法中需要計算key的hash值,然後通過hash值計算所在散列桶的位置,判斷散列桶的位置是否有衝突,衝突過後需要使用鏈地址法解決衝突,使之形成一個鏈表,從JDK8開始如果鏈表的元素達到8個過後還會轉換為紅黑樹。在插入時還需要判斷是否需要擴容,擴容機制的設計,以及在併發環境下擴容所帶來的死迴圈問題。
由於JDK7比較簡單,我們先來查看JDK7中的put方法源碼。
JDK7——HashMap#put
1 //JDK7, HashMap#put 2 public V put(K key, V value) { 3 //1. 首先判斷是否是第一次插入,即散列表是否指向空的數組,如果是,則調用inflateTable方法對HashMap進行初始化。 4 if (table == EMPTY_TABLE) { 5 inflateTable(threshold); 6 } 7 //2. 判斷key是否等於null,等於空則調用putForNullKey方法存入key為null的key-value,HashMap支持key=null。 8 if (key == null) 9 return putForNullKey(value); 10 //3. 調用hash方法計算key的hash值,調用indexFor根據hash值和散列表的長度計算key值所在散列表的下標i。 11 int hash = hash(key); 12 int i = indexFor(hash, table.length); 13 //4. 這一步通過迴圈遍歷的方式判斷插入的key-value是否已經在HashMap中存在,判斷條件則是key的hash值相等,且value要麼引用相等要麼equals相等,如果滿足則直接返回value。 14 for (Entry<K,V> e = table[i]; e != null; e = e.next) {//如果插入位置沒有散列衝突,即這個位置沒有Entry元素,則不進入迴圈。有散列衝突則需要遍歷鏈表進行判斷。 15 Object k; 16 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 17 V oldValue = e.value; 18 e.value = value; 19 e.recordAccess(this); 20 return oldValue; 21 } 22 } 23 //插入 24 modCount++;//記錄修改次數,在併發環境下通過迭代器遍歷時會拋出ConcurrentModificationException異常(Fail-Fast機制),就是通過這個變數來實現的。在迭代器初始化過程會將modCount賦給迭代器的ExpectedModCount,是否會拋出ConcurrentModificationException異常的實現就是在迭代過程中判斷modCount是否與ExpectedModCount相等。 25 //插入key-value鍵值對,傳入key的hash值、key、value、散列表的插入位置i 26 addEntry(hash, key, value, i); 27 }
1 //JDK7,HashMap#addEntry,這個方法是put方法的實現核心,在其中會判斷是否衝突,是否擴容。 2 void addEntry(int hash, K key, V value, int bucketIndex) { 3 //第一步判斷就是是否擴容,需要擴容的條件需要滿足以下兩個:1、Map中的key-value的個數大於等於Map的容量threshold(threshold=散列表容量(數組大小)*負載因數)。2、key值所對應的散列表位置不為null。 4 if ((size >= threshold) && (null != table[bucketIndex])) { 5 resize(2 * table.length); //關鍵的擴容機制,擴容後的大小是之前的兩倍 6 hash = (null != key) ? hash(key) : 0; //計算key的hash值 7 bucketIndex = indexFor(hash, table.length); //重新計算key所在散列表的下標 8 } 9 //創建Entry節點並插入,每次插入都會插在鏈表的第一個位置。 10 createEntry(hash, key, value, bucketIndex); 11 }
來看看HashMap是如何擴容的。JDK7HashMap擴容的大小是前一次散列表大小的兩倍2 * table.length
void resize(int newCapacity)
在這個方法中最核心的是transfer(Entry[], boolean)方法,第一個參數表示擴容後新的散列表引用,第二參數表示是否初始化hash種子。
結合源碼我們用圖例來說明HashMap在JDK7中是如何進行擴容的。
假設現在有如下HashMap,初始容量initialCapacity=4,負載因數loadFactor=0.5。初始化時閾值threshold=4*0.5=2。也就是說在插入第三個元素時,HashMap中的size=3大於閾值threshold=2,此時就會進行擴容。我們從來兩種情況來對擴容機制進行分析,一種是兩個key-value未產生散列衝突,第二種是兩個key-value產生了散列衝突。
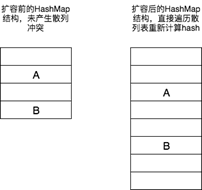
1. 擴容時,當前HashMap的key-value未產生散列衝突

此時當插入第三個key-value時,HashMap會進行擴容,容量大小為之前的兩倍,並且在擴容時會對之前的元素進行轉移,未產生衝突的HashMap轉移較為簡單,直接遍歷散列表對key重新計算出新散列表的數組下標即可。
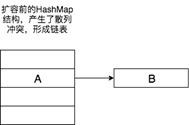
 2. 擴容時,當前HashMap的key-value產生散列衝突
2. 擴容時,當前HashMap的key-value產生散列衝突
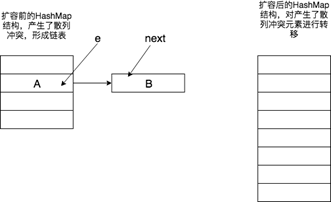
在對散列衝突了的元素進行擴容轉移時,需要遍歷當前位置的鏈表,鏈表的轉移若新散列表還是衝突則採用頭插法的方式進行插入,此處需要瞭解鏈表的頭插法。同樣通過for (Entry<K,V> e : table)遍歷散列表中的元素,判斷當前元素e是否為null。由例可知,當遍歷到第2個位置的時候元素e不為null。此時創建臨時變數next=e.next。
重新根據新的散列表計算e的新位置i,後面則開始通過頭插法把元素插入進入新的散列表。
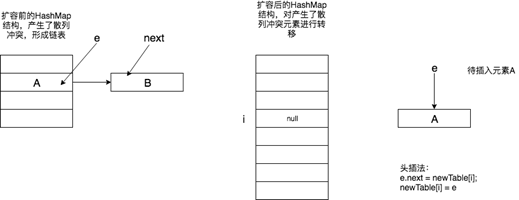
通過頭插法將A插入進了新散列表的i位置,此時指針通過e=next繼續移動,待插入元素變成了B,如下所示。

此時會對B元素的key值進行hash運算,計算出它在新散列表中的位置,無論在哪個位置,均是頭插法,假設還是在位置A上產生了衝突,頭插法後則變成瞭如下所示。
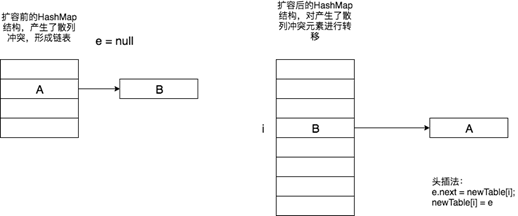
可知,在擴容過程中,鏈表的轉移是關鍵,鏈表的轉移通過頭插法進行插入,所以正是因為頭插法的原因,新散列表衝突的元素位置和舊散列表衝突的元素位置相反。
關於HashMap的擴容機制還有一個需要註意的地方,在併發條件下,HashMap不僅僅是會造成數據錯誤,致命的是可能會造成CPU100%被占用,原因就是併發條件下,由於HashMap的擴容機制可能會導致死迴圈。下麵將結合圖例說明,為什麼HashMap在併發環境下會造成死迴圈。
假設在併發環境下,有兩個線程現在都在對同一個HashMap進行擴容。
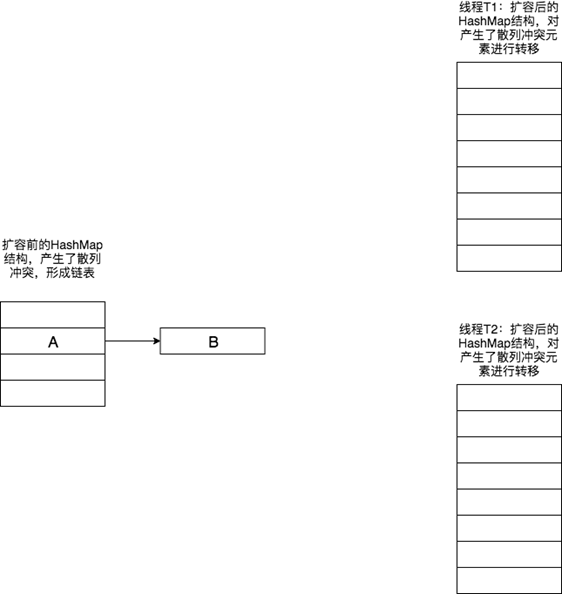
此時線程T1對擴容前的HashMap元素已經完成了轉移,但由於Java記憶體模型的緣故線程T2此時看到的還是它自己線程中HashMap之前的變數副本。此時T2對數據進行轉移,如下圖所示。
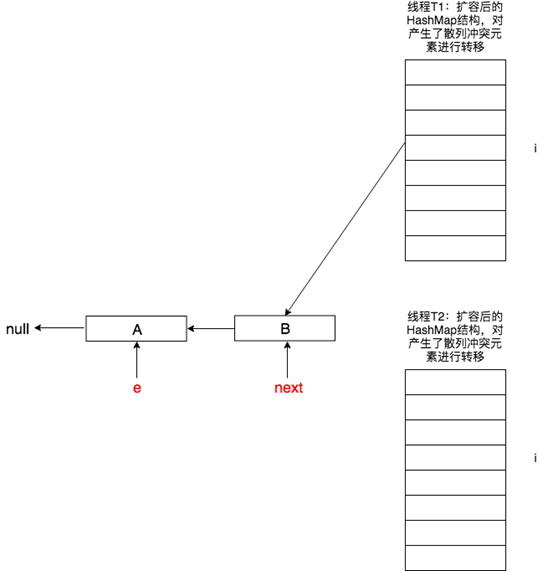
進一步地,在T2中的新散列表中newTable[i]指向了元素A,此時待插入節點變成了B,如下圖所示。
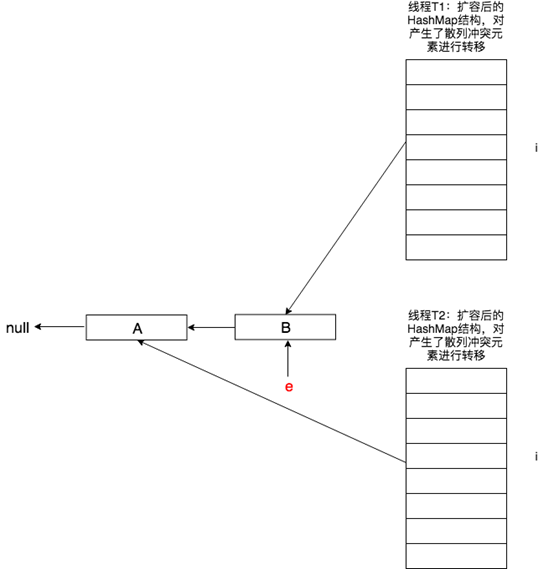
原本在正常情況下,next會指向null,但由於T1已經對A->B鏈表進行了轉置B->A,即next又指回了A,並且B會插入到T2的newTable[i]中。
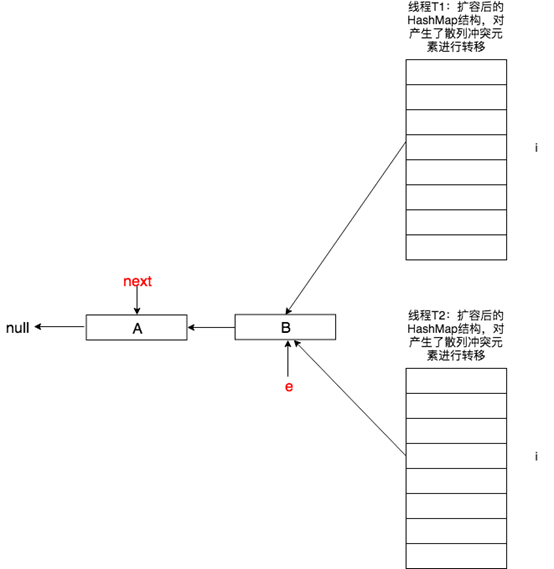
由於此時next不為空,下一步又會將next賦值給e,即e = next,反反覆復A、B造成閉環形成死迴圈。
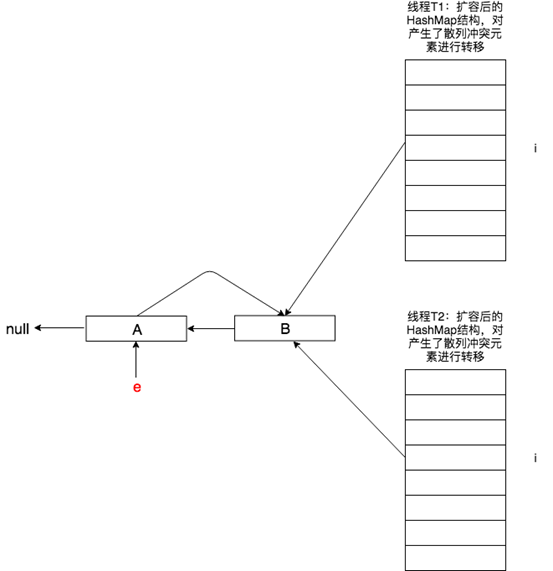
所以,千萬不要使用在併發環境下使用HashMap,一旦出現死迴圈CPU100%,這個問題不容易復現及排查。併發環境一定需要使用ConcurrentHashMap線程安全類。
探討了JDK7中的put方法,接下來看看JDK8新增了紅黑樹HashMap是如何進行put,如何進行擴容,以及如何將鏈表轉換為紅黑樹的。
JDK8——HashMap#put
1 //JDK8, HashMap#put 2 public V put(K key, V value) { 3 //在JDK8中,put方法直接調用了putVal方法,該方法有5個參數:key哈希值,key,value,onlyIfAbsent(如果為ture則Map中已經存在該值的時候將不會把value值替換),evict在HashMap中無意義 4 return putVal(hash(key), key, value, false, true); 5 }
所以關鍵的方法還是putVal。
1 //JDK8中putVal方法和JDK7中put方法中的插入步驟大致相同,同樣需要判斷是否是第一次插入,插入的位置是否產生衝突,不同的是會判斷插入的節點是“鏈表節點”還是“紅黑色”節點。 2 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { 3 //1. 是否是第一次插入,是第一次插入則復用resize演算法,對散列表進行初始化 4 if ((tab = table) == null || (n = tab.length) == 0) 5 n = (tab = resize()).length; 6 //2. 通過i = (n - 1) & hash計算key值所在散列表的下標,判斷tab[i]是否已經有元素存在,即有無衝突,沒有則直接插入即可,註意如果插入的key=null,此處和JDK7的策略略有不同,JDK7是遍歷散列表只要為null就直接插入,而JDK8則是始終會插入第一個位置,即使有元素也會形成鏈表 7 if ((p = tab[i = (n - 1) & hash]) == null) 8 tab[i] = newNode(hash, key, value, null); 9 //3. tab[i]已經有了元素即產生了衝突,如果是JDK7則直接使用頭插法即可,但在JDK8中HashMap增加了紅黑樹數據結構,此時有可能已經是紅黑樹結構,或者處在鏈表轉紅黑樹的臨界點,所以此時需要有幾個判斷條件 10 else { 11 //3.1 這是一個特殊判斷,如果tab[i]的元素hash和key都和帶插入的元素相等,則直接覆蓋value值即可 12 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) 13 e = p; 14 //3.2 待插入節點是一個紅黑樹節點 15 else if (p instanceof TreeNode) 16 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 17 //3.3 插入後可能繼續是一個鏈表,也有可能轉換為紅黑樹。在元素個數超過8個時則會將鏈表轉換為紅黑樹,所以第一個則需要一個計數器來遍歷計算此時tab[i]上的元素個數 18 else { 19 for (int binCount = 0; ; ++binCount) { 20 if ((e = p.next) == null) { 21 p.next = newNode(hash, key, value, null); //遍歷到當前元素的next指向null,則通過尾插法插入,這也是和JDK7採用頭插法略微不同的地方 22 if (binCount >= TREEIFY_THRESHOLD - 1) // tab[i]的數量超過了臨界值8,此時將會進行鏈表轉紅黑樹的操作,並跳出迴圈 23 treeifyBin(tab, hash); 24 break; 25 } 26 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) //這種情況同3.1,出現了和插入key相同的元素,直接跳出迴圈,覆蓋value值即可,無需插入操作 27 break; 28 p = e; 29 } 30 } 31 if (e != null) { //這種情況表示帶插入元素的key在Map中已經存在,此時沒有插入操作,直接覆蓋value值即可 32 V oldValue = e.value; 33 if (!onlyIfAbsent || oldValue == null) 34 e.value = value; 35 afterNodeAccess(e); 36 return oldValue; 37 } 38 } 39 ++modCount; //修改計數,在使用Iterator迭代器時會和這個變數比較,如果不相等,則會拋出ConcurrentModificationException異常 40 if (++size > threshold) //判斷是否需要擴容 41 resize(); 42 afterNodeInsertion(evict); //並無意義 43 return null; 44 }
從上面的JDK7和JDK8的put插入方法源碼分析來看,JDK8確實複雜了不少,在沒有耐心的情況下,這個“乾貨”確實顯得比較乾,我試著用下列圖解的方式回顧JDK7和JDK8的插入過程,在對比過後接著對JDK8中的紅黑樹插入、鏈表轉紅黑樹以及擴容作分析。


綜上JDK7和JDK8的put插入方法大體上相同,其核心均是計算key的hash並通過hash計算散列表的下標,再判斷是否產生衝突。只是在實現細節上略有區別,例如JDK7會對key=null做特殊處理,而JDK8則始終會放置在第0個位置;而JDK7在產生衝突時會使用頭插法進行插入,而JDK8在鏈表結構時會採用尾插法進行插入;當然最大的不同還是JDK8對節點的判斷分為了:鏈表節點、紅黑樹節點、鏈表轉換紅黑樹臨界節點。
對於紅黑樹的插入暫時不做分析,接下來是對JDK8擴容方法的分析。
1 // JDK8,HashMap#resize擴容,HashMap擴容的大小仍然是前一次散列表大小的兩倍 2 final Node<K,V>[] resize() { 3 //1. 由於JDK8初始化散列表時復用了resize方法,所以前面是對oldTab的判斷,是否為0(表示是初始化),是否已經大於等於了最大容量。判斷結束後newTab會擴大為oldTab的兩倍,同樣newThr(閾值)也是以前的兩倍。源碼略。 4 //2. 確定好newTab的大小後接下來就是初始化newTab散列表數組 5 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; 6 table = newTab; 7 //3. 如果是初始化(即oldTab==null),則直接返回新的散列表數組,不是則進行轉移 8 //4. 首先還是遍歷散列表 9 for (int j = 0; j < oldCap; ++j) { 10 //5. e = oldCap[i] != null,則繼續判斷 11 //5.1 當前位置i,是否有衝突,沒有則直接轉移 12 if (e.next == null) 13 newTab[e.hash & (newCap - 1)] = e; //這裡並沒有對要轉移的元素重新計算hash,對於JDK7來會通過hash(e.getKey()) ^ newCap重新計算e在newTab中的位置,此處則是e.hash & (newCap - 1),減少了重新計算hash的過程。擴容後的位置要麼在原來的位置上,要麼在原索引 + oldCap位置 14 //5.2 判斷是否是紅黑樹節點 15 else if (e instanceof TreeNode) 16 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); 17 //5.3 判斷是否是鏈表節點 18 else { 19 … 20 } 21 } 22 }
JDK8的擴容機制相比較於JDK7除了增加對節點是否為紅黑樹的判斷,其餘大致相同,只是做了一些微小的優化。特別在於在JDK8中並不會重新計算key的hash值。
public V remove(Object key)
如果已經非常清楚put過程,我相信對於HashMap中的其他方法也基本能知道套路。remove刪除也不例外,計算hash(key)以及所在散列表的位置i,判斷i是否有元素,元素是否是紅黑樹還是鏈表。
這個方法容易陷入的陷阱是key值是一個自定義的pojo類,且並沒有重寫equals和hashCode方法,此時用pojo作為key值進行刪除,很有可能出現“刪不掉”的情況。這需要重寫equals和hashCode才能使得兩個pojo對象“相等”。
剩下的方法思路大同小異,基本均是計算hash、計算散列表下標i、遍歷、判斷節點類型等等。本文在弄清put和resize方法後,一切方法基本上都能舉一反三。所以在看完本文後,你應該試著問自己以下幾個問題:
- HashMap的底層數據結構是什麼?
- HashMap的put過程?
- HashMap的擴容機制?
- 併發環境下HashMap會帶來什麼致命問題?
這是一個能給程式員加buff的公眾號



