
happens before原則 我們編寫的程式都要經過優化後(編譯器和處理器會對我們的程式進行優化以提高運行效率)才會被運行,優化分為很多種,其中有一種優化叫做重排序,重排序需要遵守happens before規則,換句話說只要滿足happens before原則就可以進行重排序。 定義 :在JM ...
happens-before原則
我們編寫的程式都要經過優化後(編譯器和處理器會對我們的程式進行優化以提高運行效率)才會被運行,優化分為很多種,其中有一種優化叫做重排序,重排序需要遵守happens-before規則,換句話說只要滿足happens-before原則就可以進行重排序。
定義:在JMM中,如果一個操作執行的結果需要對另一個操作可見,那麼這兩個操作之間必須存在happens-before關係
註意:定義中所說的前一個操作happens-before後一個操作並不是說前一個操作必須要在後一個操作之前執行,而是指前一個操作的執行結果必須對後一個操作可見,考慮下述情況:
int a = 1; //操作A
int b = 2; //操作B單線程執行上述代碼塊規定操作A happens-before 操作B,也就是說操作A的結果對操作B是可見的,但是操作B對操作A中a=1的賦值並沒有依賴,即使操作A與操作B重排序了,它們之間的happens-before關係仍然存在,這個例子就說明瞭happens-before並不是對執行順序對約束,同時也是重排序的一種情況。
規則:
- 程式次序規則:一個線程內,按照代碼順序,書寫在前面的操作先行發生於書寫在後面的操作;
- 鎖定規則:一個unLock操作先行發生於後面對同一個鎖的lock操作;
- volatile變數規則:對一個變數的寫操作先行發生於後面對這個變數的讀操作;
- 傳遞規則:如果操作A先行發生於操作B,而操作B又先行發生於操作C,則可以得出操作A先行發生於操作C;
- 線程啟動規則:Thread對象的start()方法先行發生於此線程的每個一個動作;
- 線程中斷規則:對線程interrupt()方法的調用先行發生於被中斷線程的代碼檢測到中斷事件的發生;
- 線程終結規則:線程中所有的操作都先行發生於線程的終止檢測,我們可以通過Thread.join()方法結束、Thread.isAlive()的返回值手段檢測到線程已經終止執行;
- 對象終結規則:一個對象的初始化完成先行發生於他的finalize()方法的開始;
volatile關鍵字
可見性
volatile修飾的變數的一個特點是可見性:保證被volatile修飾的共用變數對所有線程可見,也就是當一個線程修改了一個被volatile修飾變數的值,其他線程可以立即得知新值,舉例:
volatile boolean shutdownRequested;
public void shutdown(){
shutdownRequested = true;
}
public void doWork(){
while(!shutdownRequested){
//do stuff
}
}錯誤用法:
public class VolatileVisibility {
public static volatile int i =0;
public static void increase(){
i++;
}
}
/**
volatile關鍵值不保證有序性,i++包括讀取一個值,然後寫回一個新值,新值比原來值加了1,這相當於兩個步驟,如果第二個線程在第一個線程讀取舊值和寫回新值期間讀取i的值,併進行加一操作,會發生更新重覆,存線上程安全問題
**/有序性
volatile修飾的變數的另一個特是有序性點:禁止指令重排優化,從而避免多線程環境下程式出現亂序執行的現象
//雙重校驗鎖
public class Singleton {
private static volatile Singleton instance = null;
private Singleton() { }
public static Singleton getInstance() {
if(instance == null) {
synchronized(Singleton.class) {
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}疑問:上述代碼Singleton變數為什麼要用volatile修飾?
解答:
instance = new Singleton()可以分為下述步驟完成:
memory = allocate(); //1:分配對象的記憶體空間
instance(memory); //2:初始化對象
instance = memory; //3:設置instance指向剛分配的記憶體地址 由於2,3步驟沒有數據依賴關係,因此2,3可以重排序並沒有違背單線程的happens-before規則,重排後如下:
memory = allocate(); //1.分配對象記憶體空間
instance = memory; //3.設置instance指向剛分配的記憶體地址,此時instance!=null,但是對象還沒有初始化完成!
instance(memory); //2.初始化對象根據volatile變數的可見性,在執行完3後,instance不為空,但是尚未實例化,但是此時如果有線程過來請求實例,就可能返回尚未實例化對象。
記憶體屏障
緩存一致性
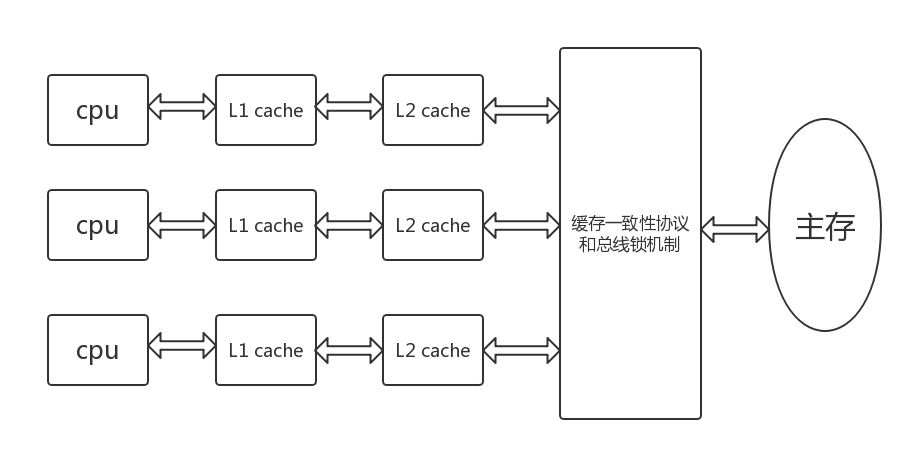
嗅探機制(snooping):所有記憶體傳輸都發生在一條共用的匯流排上,而所有的處理器都能看到這條匯流排:緩存本身是獨立的,但是記憶體是共用資源,嗅探(snooping)協議的思想是,緩存不僅僅在做記憶體傳輸的時候才和匯流排打交道,而是不停地在嗅探匯流排上發生的數據交換,跟蹤其他緩存在做什麼。所以當一個緩存代表它所屬的處理器去讀寫記憶體時,其他處理器都會得到通知,它們以此來使自己的緩存保持同步。只要某個處理器一寫記憶體,其他處理器馬上就知道這塊記憶體在它們自己的緩存中對應的段已經失效。
匯流排鎖機制(lock):在指令前面加上lock,那麼會鎖住匯流排和相應的緩存,其他指令會被阻塞,當lock後的指令執行完畢會將結果刷新到記憶體中去,根據嗅探機制,其他cpu中的緩存會失效,重新從記憶體中讀取,也就解決了緩存一致性問題
緩存一致性協議(MESI):cpu緩存有四個標記位:
M: Modify,修改緩存,當前CPU的緩存已經被修改了,即與記憶體中數據已經不一致了
E: Exclusive,獨占緩存,當前CPU的緩存和記憶體中數據保持一致,而且其他處理器並沒有可使用的緩存數據
S: Share,共用緩存,和記憶體保持一致的一份拷貝,多組緩存可以同時擁有針對同一記憶體地址的共用緩存段
I: Invalid,失效緩存,這個說明CPU中的緩存已經不能使用了
CPU的讀取遵循下麵幾點:
如果緩存狀態是I,那麼就從記憶體中讀取,否則就從緩存中直接讀取。
如果緩存處於M或E的CPU讀取到其他CPU有讀操作,就把自己的緩存寫入到記憶體中,並將自己的狀態設置為S。
只有緩存狀態是M或E的時候,CPU才可以修改緩存中的數據,將其他cpu緩存設置無效,修改後,緩存狀態變為M
記憶體屏障
- 硬體層的記憶體屏障分為兩種:Load Barrier 和 Store Barrier即讀屏障和寫屏障。
- 記憶體屏障有兩個作用:
阻止屏障兩側的指令重排序;
強制把寫緩衝區/高速緩存中的臟數據等寫回主記憶體,讓緩存中相應的數據失效。
- 對於Load Barrier來說,在指令前插入LoadBarrier,可以讓高速緩存中的數據失效,強制從新從主記憶體載入數據;對應的在讀volatile變數前加上Lfence
- 對於Store Barrier來說,在指令後插入StoreBarrier,能讓寫入緩存中的最新數據更新寫入主記憶體,讓其他線程可見,對應的在寫volatile變數後加上Sfence
參考資料
http://blog.csdn.net/u010031673/article/details/48153797
https://kb.cnblogs.com/page/504824/
https://www.cnblogs.com/dolphin0520/p/3920373.html
https://www.jianshu.com/p/195ae7c77afe
http://blog.csdn.net/iter_zc/article/details/42006811
https://www.jianshu.com/p/2ab5e3d7e510


