
一、hdfs的概念 Hadoop 實現了一個分散式文件系統(Hadoop Distributed File System),簡稱HDFS。 Hadoop是Apache Lucene創始人Doug Cutting開發的使用廣泛的文本搜索庫。它起源於Apache Nutch,後者是一個開源的網路搜索引擎 ...
一、hdfs的概念
Hadoop 實現了一個分散式文件系統(Hadoop Distributed File System),簡稱HDFS。 Hadoop是Apache Lucene創始人Doug Cutting開發的使用廣泛的文本搜索庫。它起源於Apache Nutch,後者是一個開源的網路搜索引擎,本身也是Luene項目的一部分。Aapche Hadoop架構是MapReduce演算法的一種開源應用,是Google開創其帝國的重要基石。
什麼是文件系統呢,其實我們最熟悉的windows用的是NTFS文件系統,linux用的是EXT3等等的,那歸根結底不管什麼存儲方式,不同的文件系統裡面存儲文件是什麼形式,它都是用來存儲文件的,那麼HDFS也是一樣的,那我們就可以把它理解為類似於Win的HDFS的一種存儲文件的方式。
二、hdfs實現思想和概念
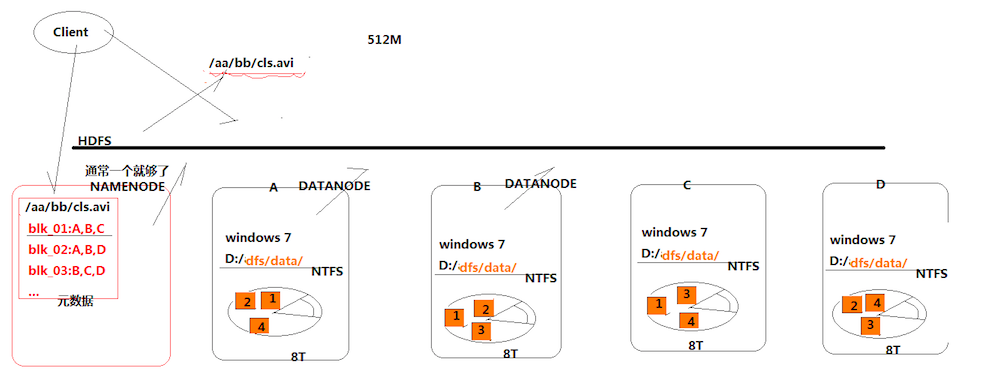
首先有一個概念叫分散式存儲,它與普通的存儲方式最大的區別在於,它將文件數據切分存放在多台伺服器上面,從而減輕了一臺伺服器的存儲壓力。那麼hdfs也是一種分散式存儲的系統,具體怎麼存儲的如上圖所示。
首先,我們又ABCD四個存儲的伺服器,有一個待存儲的文件叫cls.avi,那麼既然是分散式存儲的,那麼我們可以先將帶存儲文件切分為4塊,在圖中以1234個小方塊表示,那麼,我們可以將1234分別先存儲到ABCD四個伺服器裡面,然後ABCD分別用NTFS將其保存起來。
那麼這樣初步實現了將數據分塊存儲,然後需要取數據的時候,從四台伺服器將數據取出來然後拼接起來,這樣就初步實現了數據分佈化。但是這樣存儲面臨一種問題,也就是說,如果我其中的一臺伺服器,比如說A壞掉了,那麼最終我取出來的文件便會不全,那麼為瞭解決這種問題,hdfs將文件的塊存儲在多台伺服器裡面,如上圖中,塊1存儲在ABC,塊2存儲在ABD等等,那麼如果說,我想取出塊1,那麼即便A壞了,我也可以從BC裡面取,那麼最終我取出來的數據還是完整的。
接著,還有一個問題,我是如何知道哪些塊存儲在哪些伺服器上面的呢?那麼hdfs提供了一個類似於路由伺服器的功能,也就是所謂的namenode,前面所說的存儲的伺服器叫做datanode。那麼namenode主要的功能便是,在數據塊被存儲的時候,將數據存儲信息記錄下來,比如說塊1:ABC,塊2:ABD等等,那麼到客戶端需要取出數據的時候,可以根據這些存儲信息去對應的伺服器上面獲取數據即可,而且我們不太需要關心namenode的併發壓力問題,因為這些存儲信息的大小都會很小,不像datanode那樣需要存儲數據塊。
三、總結
1.hdfs是通過分散式集群來存儲文件的,文件被存儲的時候分塊多個block塊
2.某一個block塊存儲在多台數據伺服器datanode裡面的
3.block塊於datanode的存儲關係是映射的,信息存儲在namenode裡面
4.這樣存儲的好處是其中一臺機器發生故障,不會影響到數據的存儲與讀取
hdfs主要是負責存儲,那麼如何快速的將這些存儲的大量數據讀取並且返回給客戶端,那麼便是MapReduce需要去做的了。博主也是剛剛接觸hadoop不久,上面的只是博主個人所學的見解,如果有不對的地方,還請大家多多指教。


