
MySQL SQL語句的優化,查詢慢日誌,使用工具分析慢查詢日誌,優化的策略 ...
如何獲取有性能問題的SQL
1、通過用戶反饋獲取存在性能問題的SQL
2、通過慢查詢日誌獲取性能問題的SQL
3、實時獲取存在性能問題的SQL使用慢查詢日誌獲取有性能問題的SQL
首先介紹下慢查詢相關的參數
1、slow_query_log 啟動定製記錄慢查詢日誌
設置的方法,可以通過MySQL命令行設置set global slow_query_log=on
或者修改/etc/my.cnf文件,添加slow_query_log=on
2、slow_query_log_file 指定慢查詢日誌的存儲路徑及文件
建議日誌存儲和數據存儲分開存儲
3、long_query_time 指定記錄慢查詢日誌SQL執行時間的閾值
① 記錄所有符合條件的SQL
② 數據修改語句
③ 包括查詢語句
④ 已經回滾的SQL
註意:
時間可以精確到微秒,存儲的單位是秒,預設值為10秒,例如我們想查詢1微秒的值,這裡就要設置成0.001秒
4、log_queries_not_using_indexes 是否記錄未使用索引的SQL
5、log_output 設置慢日誌查詢的保存格式(如果需要保存為文件請修改成FILE)慢查詢使用日誌中記錄的信息
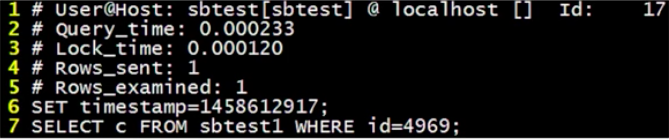
1、第一行記錄的信息為使用sbtest做的測試
2、第二行記錄的信息為慢查詢日誌的時間
3、第三行記錄的信息為所使用鎖的時間
4、第四行記錄的信息為返回的數據行數
5、第五行記錄的信息為掃描數據的行數
6、第六行記錄的信息為時間戳
7、第七行記錄的信息為查詢的SQL語句使用慢查詢獲取有性能問題的SQL
常使用的慢查詢日誌分析工具(mysqldumpslow)
介紹:彙總除查詢條件外其他完全相同的SQL,並將分析結果按照參數中所指定的順序輸出

慢查詢日誌實例
慢查詢的相關配置設置
命令行執行參數查看分析的結果
]# cd /var/lib/mysql/log
]# mysqldumpslow -s r -t 10 slow-mysql 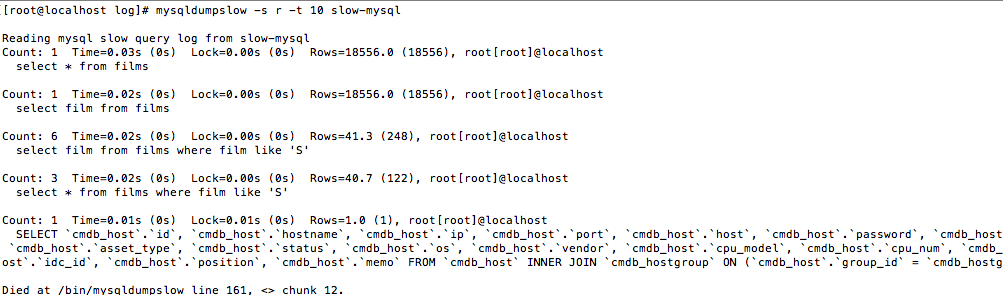
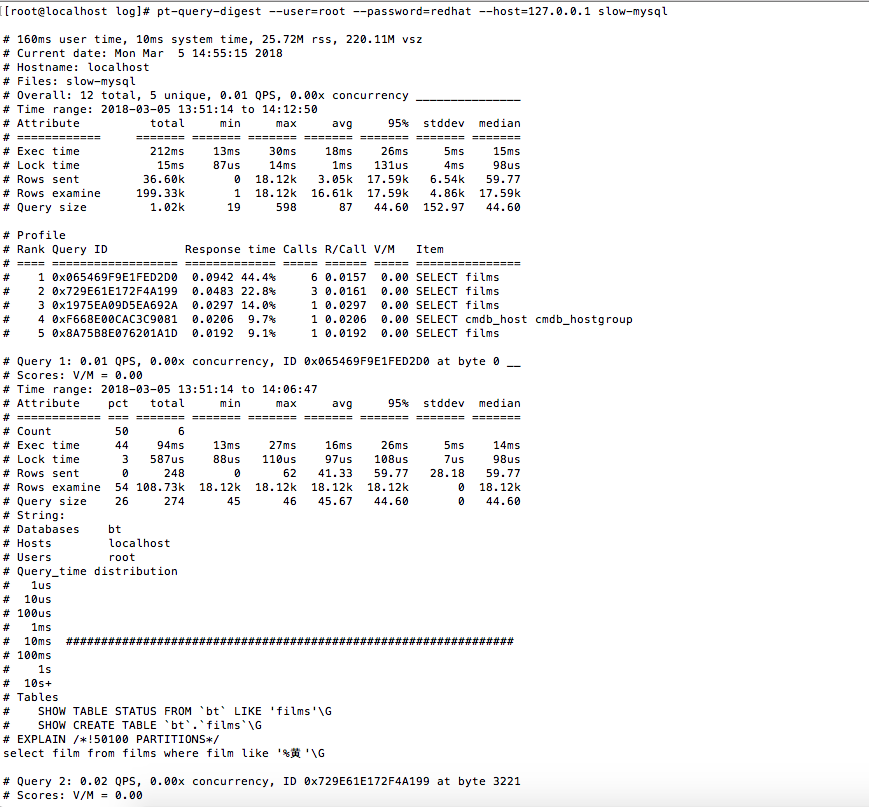
常使用的慢查詢日誌分析工具(pt-query-digest)
使用工具前,需要先安裝該工具,如果已有,可略過下麵的安裝步驟
1、perl模塊
]# yum install -y perl-CPAN perl-Time-HiRes perl-IO-Socket-SSL perl-DBD-mysql perl-Digest-MD5
2、切換至src目錄下載rpm包
]# cd /usr/local/src
]# wget https://www.percona.com/downloads/percona-toolkit/3.0.7/binary/redhat/7/x86_64/percona-toolkit-3.0.7-1.el7.x86_64.rpm
3、安裝工具包
]# rpm -ivh percona-toolkit-3.0.7-1.el7.x86_64.rpm
執行命令分析慢查詢日誌
]# pt-query-digest --user=root --password=redhat --host=127.0.0.1 slow-mysql > slow.rep分析的結果如下
MySQL伺服器處理查詢請求的整個過程
1、客戶端發送SQL請求給伺服器
2、伺服器檢查是否存在在緩存伺服器中命中該SQL
3、伺服器端進行SQL解析,預處理,再由優化器對應執行計劃
4、根據執行計劃,調用存儲引擎API來查詢數據
5、將結果返回給客戶端查詢緩存對SQL性能的影響
1、優先檢查整個查詢是否命中查詢緩存中的數據
2、通過一個對大小寫敏感的哈希查找實現的查詢緩存的優化參數
query_cache_type 設置查詢緩存是否可用
ON,OFF,DEMAND
註意:DEMAND表示只有在查詢語句中使用SQL——CACHE和SQL_NO_CACHE來控制是否需要緩存
query_cache_size 設置查詢緩存的記憶體大小
query_cache_limit 設置查詢緩存可用存儲的最大值
query_cache_wlock_invalidate 設置數據表被鎖後是否返回緩存中的數據(預設是關閉的,建議也是關閉的此選項)
query_cache_min_res_unit 設置查詢緩存分配的記憶體塊最小的值會造成MySQL生成錯誤的執行計劃的原因
1、統計信息不准確
2、執行計劃中的成本估算不等同於實際的執行計劃的成本
3、MySQL優化器所認為的最優可能與你所認為的最優不一樣
4、MySQL從不考慮其他併發的查詢,這可能會影響當前查詢數據
5、MySQL有時候也會基於一些固定的規則來生成執行計劃
6、MySQL不會考慮不受其控制的成本MySQL優化器可優化的SQL類型
1、重新定義表的關聯順序
優化器會根據統計信息來決定表的關聯順序
2、將外鏈接轉換成內連接
where條件和庫表結構等
3、使用等價變換規則
(5=5 and a > 5)將會被改寫成 a > 5
4、優化count(), min()和max()
select tables optimized away
優化器已經從執行計劃中移除了該表,並以一個常數取而代之
5、將一個表達式轉換為常數表達式
6、使用等價變換規則
7、子查詢優化
8、對in()條件進行優化如何確定查詢處理各個階段所消耗的時間
使用profile
set profiling = 1;
執行查詢:
show profiles;
show profile for query N;
查詢的每個階段所消耗的時間使用profile查看語句所消耗的時間

特定的SQL查詢優化
1、利用主從切換的原理進行大表的表結構修改,例如,現在從伺服器上修改,修改完畢以後,進行主從切換,再在原來老的主上進行大表的修改,存在一定的風險。
2、在主伺服器上創建於一個新的表,表結構就是將要修改大表後表結構,再把老表的數據重新導入到新表中,併在老表中建立一系列的觸發器,把老表的數據同步更新到新表中,當老表中的數據全部同步到新表以後,再對老表加排它鎖,把新表改成老表的名稱,刪除重命名的老表,如下圖所示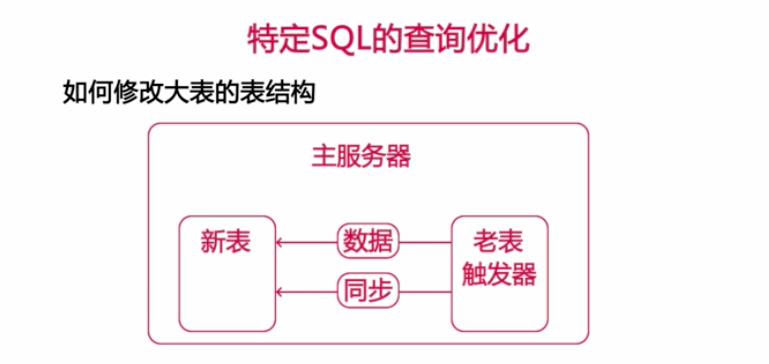
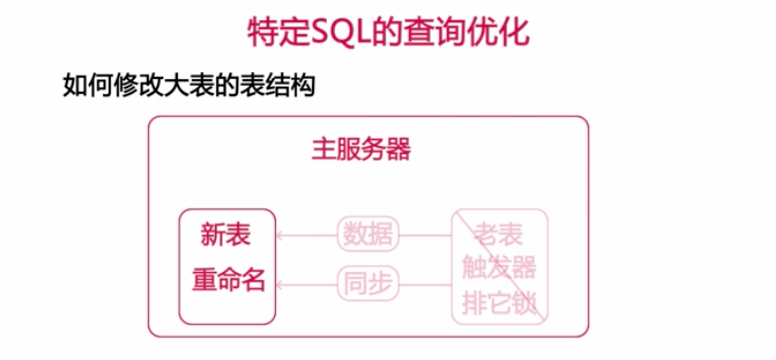
使用pt-online-schema-change命令來修改大表,具體操作如下圖所示

上圖的參數解釋
--alter 所使用的sql語句
--user 資料庫的登錄用戶
--password 登錄用戶的密碼
D 指定所有修改表的資料庫名稱
t 表的名稱
--charset 指定資料庫的字元串
--excute 執行

