
最近開始大面積使用ES,很多地方都是知其然不知其所以然,特地翻看了很多資料和大牛的文檔,簡單彙總一篇。內容多為摘抄,說是深入其實也是一點淺嘗輒止的理解。希望大家領會精神。 首先學習要從官方開始地址如下。 es官網原文:https://www.elastic.co/guide/en/elasticse ...
最近開始大面積使用ES,很多地方都是知其然不知其所以然,特地翻看了很多資料和大牛的文檔,簡單彙總一篇。內容多為摘抄,說是深入其實也是一點淺嘗輒止的理解。希望大家領會精神。
首先學習要從官方開始地址如下。
es官網原文:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html#index-refresh
索引(Index)
ES將數據存儲於一個或多個索引中,索引是具有類似特性的文檔的集合。類比傳統的關係型資料庫領域來說,索引相當於SQL中的一個資料庫,或者一個數據存儲方案(schema)。索引由其名稱(必須為全小寫字元)進行標識,並通過引用此名稱完成文檔的創建、搜索、更新及刪除操作。一個ES集群中可以按需創建任意數目的索引。
如果不懂這塊可以看我的寫的上一篇入門的內容 http://www.cnblogs.com/wenBlog/p/8482326.html
我們瞭解索引的寫操作後可知,更新、索引、刪除文檔都是寫操作,這些操作必須在primary shard完全成功後才能拷貝至其對應的replicas上,預設情況下主分片等待所有備份完成索引後才返回客戶端。
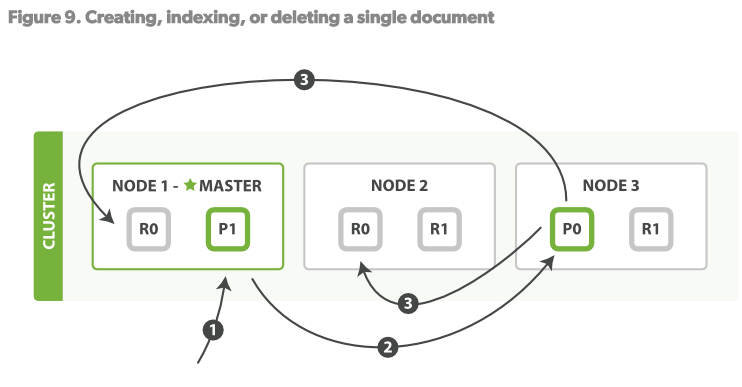
步驟:
- 客戶端向Node1 發送索引文檔請求
- Node1 根據文檔ID(_id欄位)計算出該文檔應該屬於shard0,然後請求路由到Node3的P0分片上
- Node3在P0上執行了請求。如果請求成功,則將請求並行的路由至Node1,Node2的R0上。當所有的Replicas報告成功後,Node3向請求的Node(Node1)發送成功報告,Node1再報告至Client。
當客戶端收到執行成功後,操作已經在Primary shard和所有的replica shards上執行成功了
讀操作
一個文檔可以在primary shard和所有的replica shard上讀取。見Figure10
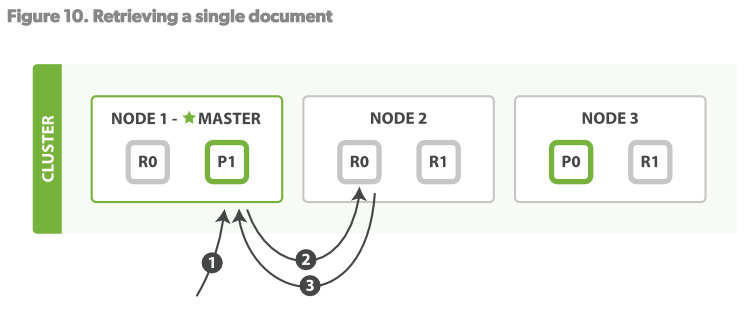
讀操作步驟:
1.客戶端發送Get請求到NODE1。
2.NODE1使用文檔的_id決定文檔屬於shard 0.shard 0的所有拷貝存在於所有3個節點上。這次,它將請求路由至NODE2。
3.NODE2將文檔返回給NODE1,NODE1將文檔返回給客戶端。 對於讀請求,請求節點(NODE1)將在每次請求到來時都選擇一個不同的replica。
shard來達到負載均衡。使用輪詢策略輪詢所有的replica shards。
更新操作
更新操作,結合了以上的兩個操作:讀、寫。見Figure11
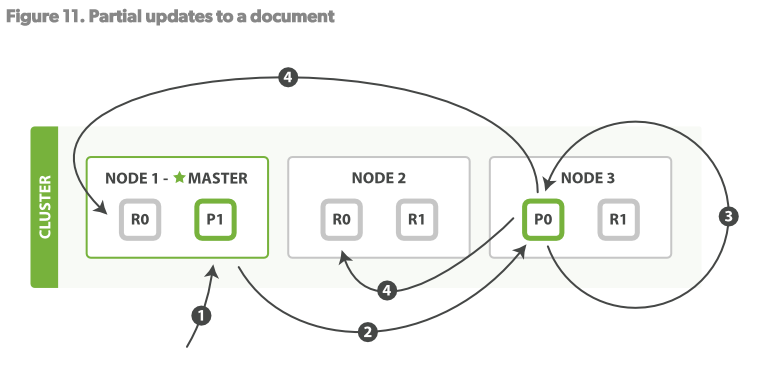
步驟:
1.客戶端發送更新操作請求至NODE1
2.NODE1將請求路由至NODE3,Primary shard所在的位置
3.NODE3從P0讀取文檔,改變source欄位的JSON內容,然後試圖重新對修改後的數據在P0做索引。如果此時這個文檔已經被其他的進程修改了,那麼它將重新執行3步驟,這個過程如果超過了retryon_conflict設置的次數,就放棄。
4.如果NODE3成功更新了文檔,它將並行的將新版本的文檔同步到NODE1和NODE2的replica shards重新建立索引。一旦所有的replica
shards報告成功,NODE3向被請求的節點(NODE1)返回成功,然後NODE1向客戶端返回成功。
2.6 SHARD
本節將解決以下問題:
- 為什麼搜索是實時的
- 為什麼文檔的CRUD操作是實時的
- ES怎麼保障你的更新在宕機的時候不會丟失
- 為什麼刪除文檔不會立即釋放空間
2.6.1不變性
寫到磁碟的倒序索引是不變的:自從寫到磁碟就再也不變。 這會有很多好處:
不需要添加鎖。如果你從來不用更新索引,那麼你就不用擔心多個進程在同一時間改變索引。
一旦索引被內核的文件系統做了Cache,它就會待在那因為它不會改變。只要內核有足夠的緩衝空間,絕大多數的讀操作會直接從記憶體而不需要經過磁碟。這大大提升了性能。
其他的緩存(例如fiter cache)在索引的生命周期內保持有效,它們不需要每次數據修改時重構,因為數據不變。
寫一個單一的大的倒序索引可以讓數據壓縮,減少了磁碟I/O的消耗以及緩存索引所需的RAM。
當然,索引的不變性也有缺點。如果你想讓新修改過的文檔可以被搜索到,你必須重新構建整個索引。這在一個index可以容納的數據量和一個索引可以更新的頻率上都是一個限制。
2.6.2動態更新索引
如何在不丟失不變形的好處下讓倒序索引可以更改?答案是:使用不只一個的索引。 新添額外的索引來反映新的更改來替代重寫所有倒序索引的方案。 Lucene引進了per-segment搜索的概念。一個segment是一個完整的倒序索引的子集,所以現在index在Lucene中的含義就是一個segments的集合,每個segment都包含一些提交點(commit point)。見Figure16。新的文檔建立時首先在記憶體建立索引buffer,見Figure17。然後再被寫入到磁碟的segment,見Figure18。

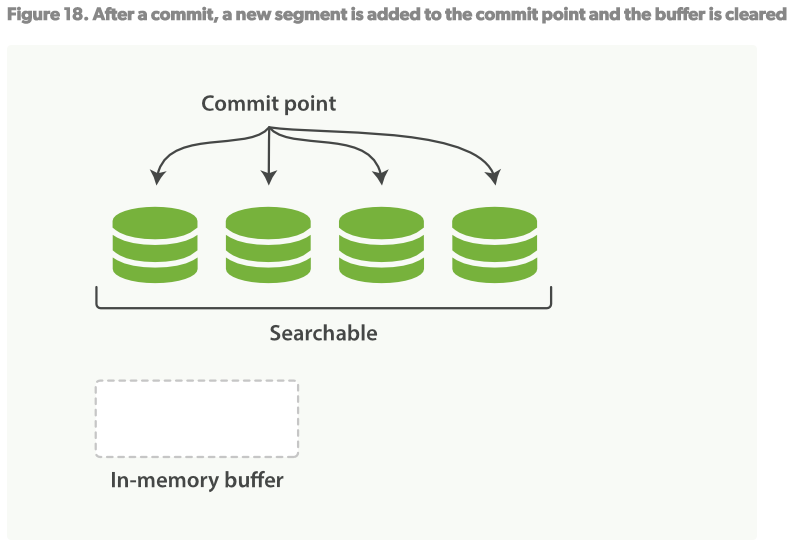
一個per-segment的工作流程如下:
1.新的文檔在記憶體中組織,見Figure17。
2.每隔一段時間,buffer將會被提交: 一個新的segment(一個額外的新的倒序索引)將被寫到磁碟 一個新的提交點(commit point)被寫入磁碟,將包含新的segment的名稱。 磁碟fsync,所有在內核文件系統中的數據等待被寫入到磁碟,來保障它們被物理寫入。
3.新的segment被打開,使它包含的文檔可以被索引。
4.記憶體中的buffer將被清理,準備接收新的文檔。
當一個新的請求來時,會遍歷所有的segments。詞條分析程式會聚合所有的segments來保障每個文檔和詞條相關性的準確。通過這種方式,新的文檔輕量的可以被添加到對應的索引中。
刪除和更新
segments是不變的,所以文檔不能從舊的segments中刪除,也不能在舊的segments中更新來映射一個新的文檔版本。取之的是,每一個提交點都會包含一個.del文件,列舉了哪一個segmen的哪一個文檔已經被刪除了。 當一個文檔被”刪除”了,它僅僅是在.del文件里被標記了一下。被”刪除”的文檔依舊可以被索引到,但是它將會在最終結果返回時被移除掉。
文檔的更新同理:當文檔更新時,舊版本的文檔將會被標記為刪除,新版本的文檔在新的segment中建立索引。也許新舊版本的文檔都會本檢索到,但是舊版本的文檔會在最終結果返回時被移除。
2.6.3實時索引
在上述的per-segment搜索的機制下,新的文檔會在分鐘級內被索引,但是還不夠快。 瓶頸在磁碟。將新的segment提交到磁碟需要fsync來保障物理寫入。但是fsync是很耗時的。它不能在每次文檔更新時就被調用,否則性能會很低。 現在需要一種輕便的方式能使新的文檔可以被索引,這就意味著不能使用fsync來保障。 在ES和物理磁碟之間是內核的文件系統緩存。之前的描述中,Figure19,Figure20,在記憶體中索引的文檔會被寫入到一個新的segment。但是現在我們將segment首先寫入到內核的文件系統緩存,這個過程很輕量,然後再flush到磁碟,這個過程很耗時。但是一旦一個segment文件在內核的緩存中,它可以被打開被讀取。
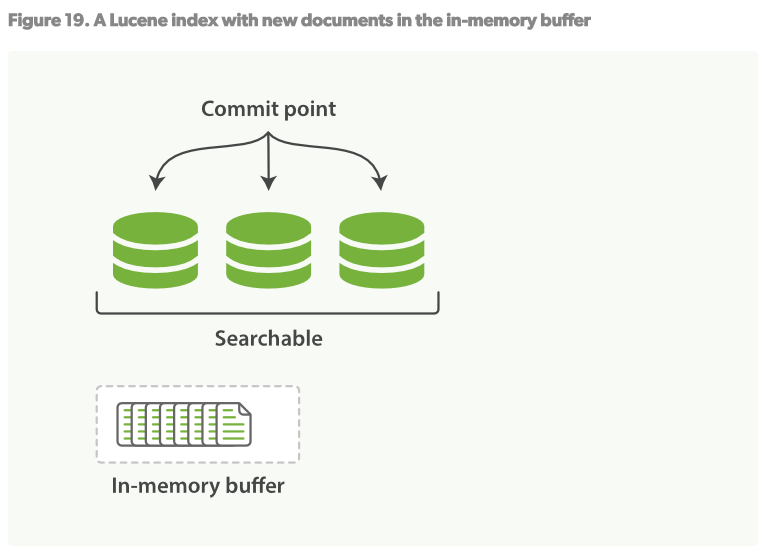
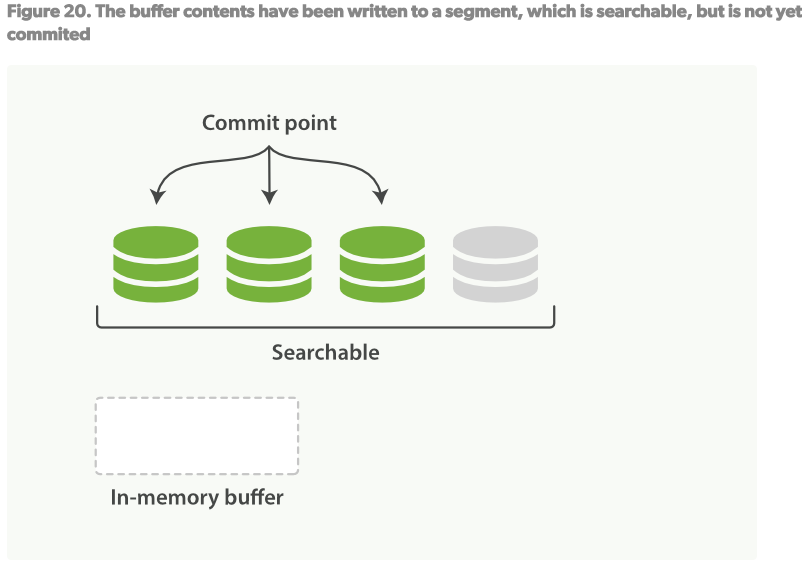
2.6.4更新持久化
不使用fsync將數據flush到磁碟,我們不能保障在斷電後或者進程死掉後數據不丟失。ES是可靠的,它可以保障數據被持久化到磁碟。 在2.6.2中,一個完全的提交會將segments寫入到磁碟,並且寫一個提交點,列出所有已知的segments。當ES啟動或者重新打開一個index時,它會利用這個提交點來決定哪些segments屬於當前的shard。 如果在提交點時,文檔被修改會怎麼樣?不希望丟失這些修改:
1.當一個文檔被索引時,它會被添加到in-memory buffer,並且添加到Translog日誌中,見Figure21.
2.refresh操作會讓shard處於Figure22的狀態:每秒中,shard都會被refreshed:


- 在in-memory buffer中的文檔會被寫入到一個新的segment,但沒有fsync。
- in-memory buffer被清空
3.這個過程將會持續進行:新的文檔將被添加到in-memory buffer和translog日誌中,見Figure23
4.一段時間後,當translog變得非常大時,索引將會被flush,新的translog將會建立,一個完全的提交進行完畢。見Figure24
- 在in-memory中的所有文檔將被寫入到新的segment
- 內核文件系統會被fsync到磁碟。
- 舊的translog日誌被刪除
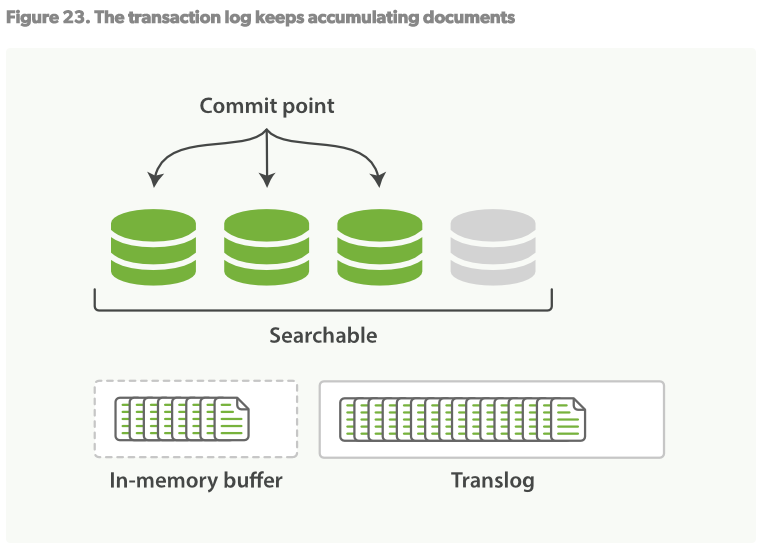

translog日誌提供了一個所有還未被flush到磁碟的操作的持久化記錄。當ES啟動的時候,它會使用最新的commit point從磁碟恢復所有已有的segments,然後將重現所有在translog裡面的操作來添加更新,這些更新發生在最新的一次commit的記錄之後還未被fsync。
translog日誌也可以用來提供實時的CRUD。當你試圖通過文檔ID來讀取、更新、刪除一個文檔時,它會首先檢查translog日誌看看有沒有最新的更新,然後再從響應的segment中獲得文檔。這意味著它每次都會對最新版本的文檔做操作,並且是實時的。
2.6.5 Segment合併
通過每隔一秒的自動刷新機制會創建一個新的segment,用不了多久就會有很多的segment。segment會消耗系統的文件句柄,記憶體,CPU時鐘。最重要的是,每一次請求都會依次檢查所有的segment。segment越多,檢索就會越慢。
ES通過在後臺merge這些segment的方式解決這個問題。小的segment merge到大的,大的merge到更大的。。。
這個過程也是那些被”刪除”的文檔真正被清除出文件系統的過程,因為被標記為刪除的文檔不會被拷貝到大的segment中。
合併過程如Figure25:

1.當在建立索引過程中,refresh進程會創建新的segments然後打開他們以供索引。
2.merge進程會選擇一些小的segments然後merge到一個大的segment中。這個過程不會打斷檢索和創建索引。
3.Figure26,一旦merge完成,舊的segments將被刪除
- 新的segment被flush到磁碟
- 一個新的提交點被寫入,包括新的segment,排除舊的小的segments
- 新的segment打開以供索引
- 舊的segments被刪除
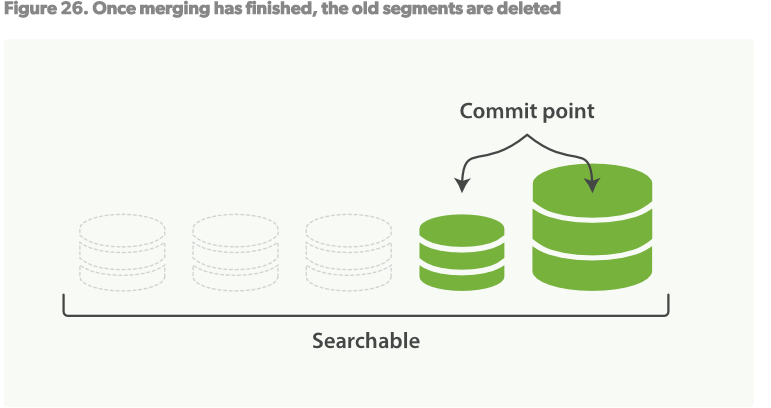
merge大的segments會消耗大量的I/O和CPU,嚴重影響索引性能。預設,ES會節制merge過程來給留下足夠多的系統資源。
近實時搜索,段數據刷新,數據可見性更新和事務日誌
理想的搜索解決方案是這樣的:新的數據一添加到索引中立馬就能搜索到。第一眼看上去,這不正是ElasticSearch的工作方式嗎,即使是多伺服器環境也是如此。但是真實情況不是這樣的(至少現在不是),後面會講到為什麼它是似是而非。首先,我們往新創建的索引中添加一個新的文檔,命令如下:
curl -XPOST localhost:9200/test/test/1 -d '{ "title": "test" }'
接下來,我們在替換文檔的同時查找該文檔。我們用如下的鏈式命令來實現這一點:
curl -XPOST localhost:9200/test/test/1 -d '{ "title": "test2" }' ; curl
localhost:9200/test/test/_search?pretty
上面命令的結果類似如下:
{"ok":true,"_index":"test","_type":"test","_id":"1","_version":2}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [ {
"_index" : "test",
"_type" : "test",
"_id" : "1",
"_score" : 1.0, "_source" : { "title": "test" }
} ]
}
}
第一行是第一個命令,即索引命令的返回結果。可以看到,數據更新成功。因此,第二個命令,即查詢命令查詢到的文檔title域值應該為test2。但是,可以看到結果並不如人所願。這背後發生了什麼呢?
在揭開前一個問題的答案之前,我們先退一步,來瞭解底層的Apache Lucene工具包是如何讓新添加的文檔對搜索可見的。
更新索引並且將改動提交
從 第1章 介紹ElasticSearch 的 介紹Apache Lucene一節中,我們已經瞭解到,在索引過程中,新添加的文檔都是寫入到段(segments)中。每個段都是有著獨立的索引結構,這意味著查詢與索引兩個過程是可以並行存在的,索引過程中,系統會不定期創建新的段。Apache Lucene通過在索引目錄中創建新的segments_N文件來標識新的段。段創建的過程就稱為索引的提交。Lucene可以一種安全的方式實現索引的提交——我們可以確定段文件要麼全部創建成功,要麼失敗。如果錯誤發生,我們可以確保索引狀態的一致性。
回到我們的例子中,第一條命令添加文檔到索引中,但是沒有提交。這就是它的工作方式。然而,索引數據的提交也不能保證數據是搜索可見的。Lucene工具包使用一個名為Searcher的抽象類來讀取索引。索引提交操作完成後,Searcher對象需要重新打開才能載入到新創建的索引段。這整個過程稱為更新。出於性能的考慮,ElasticSearch會將推遲開銷巨大的更新操作,預設情況下,單個文檔的添加並不會觸發搜索器的更新,Searcher對象會每秒更新一次。這個頻率已經比較高了,但是在一些應用程式中,需要更頻繁的更新。對面這個需求,我們可以考慮使用其它的解決方案或者再次核實我們是否真的需要這樣做。如果確實需要,那麼可以使用ElasticSearch API強制更新。比如,上面的例子中,我們可以執行如下的命令強制更新:
curl –XGET localhost:9200/test/_refresh
如果在搜索前執行了上面的命令,那麼ElasticSearch就可以搜索到修改後的文檔。
修改Searcher對象預設的更新時間
Searcher對象的預設更新時間可以通過使用index.refresh_interval參數來修改,該參數無論是添加到ElasticSearch的配置文件中或者使用update settings API都可以生效。例如:
curl -XPUT localhost:9200/test/_settings -d '{
"index" : {
"refresh_interval" : "5m"
}
}'
上面的命令將使Searcher每5秒鐘自動更新一次。請記住在更新兩個時間點之間添加到索引的數據對查詢是不可見的。


總結
本篇從索引的創建操作和原理等方面介紹了ES索引的一些內容,很多都來自各位大神的總結。經過使用ES越來越多開始作為資料庫的輔助。希望大家多多指點。


