今天思考on,where,having的執行順序,聯想到了整個sql語句的執行順序。 sql語句的執行順序為 (1) from (2) on (3) join (4) where (5) group by, count, sum, avg(6) having (7) select (8) disti ...
今天思考on,where,having的執行順序,聯想到了整個sql語句的執行順序。
sql語句的執行順序為
(1) from
(2) on
(3) join
(4) where
(5) group by, count, sum, avg
(6) having
(7) select
(8) distinct
(9) order by
(10)top
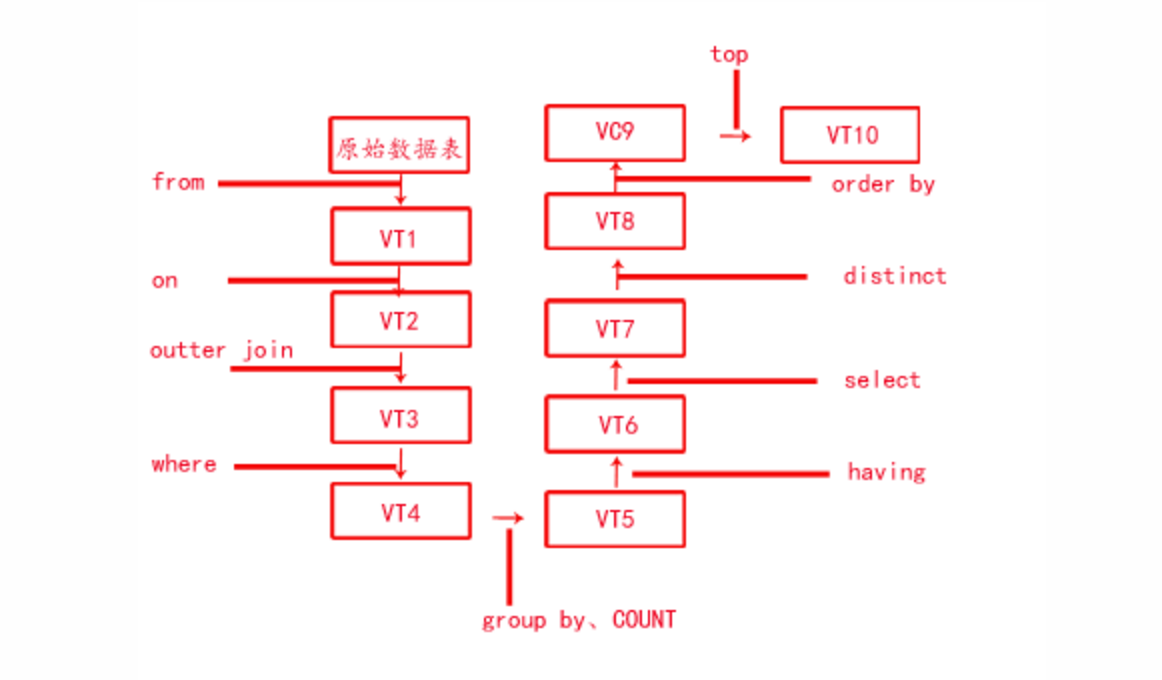
從這個順序中我們可以看出所有的查詢語句都是從from開始執行的,在執行過程中,每個步驟都會生成一個虛擬表,這個虛擬表將作為下一個執行步驟的輸入表。
1. from後如果存在多張表,那麼先取出前兩張表,以行數較小的表為基礎表,兩張表執行笛卡爾積,生成結果表vtb1
2. 將on中的邏輯表達式將應用到vtb1上,以篩選出滿足邏輯表達式的行,生成結果表vtb2
一般的sql編輯器都要求join和on搭配使用,因為如果沒有on,將生成笛卡爾積。如果你就是想要笛卡爾積作為結果的話,那麼on後的表達式可以寫1=1這種恆等式,來繞過join,on必須搭配的限制
3. 如果使用的是outer join,那麼就需要添加外部行,left outer jion將左表在第二步中過濾的行添加進來,反之將右表在第二步中過濾的行添加進來,生成虛擬表vtb3。
如果from後的表的數量大於2,那麼將vtb3作為第一張表,繼續重覆執行前三步,得到最終的vtb3。
4. 將where中的邏輯表達式將應用到vtb3上,以篩選出滿足邏輯表達式的行,生成結果表vtb4
5. 將group by後欄位中的唯一的值組合成為一組,得到虛擬表vtb5。之後的count,sum,avg等聚合操作都是針對組的
6. 將having中的邏輯表達式將應用到vtb5上,以篩選出滿足邏輯表達式的行,生成vtb6。(having篩選器是唯一應用到已分組數據的篩選器)
7. 將select的列從vtb6中篩選出來。生成vtb7
8. 依據distinct語句,將vtb7中相同的行移除,生成vtb8。如果使用了group by那麼就無需使用distinct,因為group by的結果中所有的行都不相同
9. 按照order_by指定的列排序vtb8,生成vtb9。排序是很消耗資源的,除非對結果有順序要求,否則建議不使用order by
10.根據top的列數返回給
在網上看到一張圖片,可以直觀的展示sql語句執行順序,希望對大家有所幫助