
之前在想如何降低API的延遲,這些API里有幾個比較耗時的操作且是串列執行,那通過非同步執行的方式理論上可以降低運行的時間,如下圖所示: 具體的實現比較簡單,例如這樣: 用java8引入的 即可。 這裡不再贅述。 主要講一下這樣實踐遇到的坑和一些自己的理解。 性能測試 優化後的代碼需要和未修改(基準) ...
之前在想如何降低API的延遲,這些API里有幾個比較耗時的操作且是串列執行,那通過非同步執行的方式理論上可以降低運行的時間,如下圖所示:
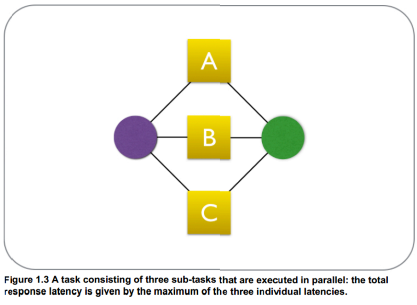
具體的實現比較簡單,例如這樣:
public class ParallelRetrievalExample {
final CacheRetriever cacheRetriever;
final DBRetriever dbRetriever;
ParallelRetrievalExample(CacheRetriever cacheRetriever,
DBRetriever dbRetriever) {
this.cacheRetriever = cacheRetriever;
this.dbRetriever = dbRetriever;
}
public Object retrieveCustomer(final long id) {
final CompletableFuture<Object> cacheFuture =
CompletableFuture.supplyAsync(() -> {
return cacheRetriever.getCustomer(id);
});
final CompletableFuture<Object> dbFuture =
CompletableFuture.supplyAsync(() -> {
return dbRetriever.getCustomer(id);
});
return CompletableFuture.anyOf(
cacheFuture, dbFuture);
}用java8引入的CompletableFuture即可。
這裡不再贅述。
主要講一下這樣實踐遇到的坑和一些自己的理解。
性能測試
優化後的代碼需要和未修改(基準)的版本做比較,要考慮在不同負載下的性能情況。
針對API的修改可以使用AB工具,比較方便,能通過設定不同的併發用戶模擬不同的負載。
測試是必要的,很多直覺上會提高性能的點可能會在實際表現上收到資源的限制等原因無法提高甚至不如優化前的性能。
適合處理的任務 & 線程池的設定
我們要優化怎樣的任務呢?
任務也就三大分類,計算密集,IO密集和混合,其中混合裡面也可以通過細化變為前兩類。
在一般的web開發中計算不太會成為瓶頸,主要是IO。
一些耗時的阻塞IO操作(資料庫,RPC調用)往往是導致介面慢的原因,這裡要優化的就是這類操作。
不過與其說是優化,更恰當的說法是讓這些阻塞操作非同步化,縮短整體的時間,這裡也要註意這些任務所在的位置,如果在API的最後面的邏輯里那優化他們也沒什麼必要,或者在不影響業務邏輯的情況下可以把他們置前。
我們需要的怎樣的線程池?
如上所說要優化的任務幾乎都是阻塞IO,也就意味著這些任務占用CPU的時間很短,主要是處在waiting狀態下,這種線程的增加最大的開銷就是記憶體,對上下文切換影響較小。
其次,線程數必定要有限,java的線程過於重量,不考慮CPU因素也需要考慮記憶體因素。
最後還要考慮線程池耗盡的情況,最差的情況是回到沒優化之前,也就是在調用者線程上執行。
CompletableFuture的runAsync和supplyAsync方法有不帶Executor的版本,首先看一下預設的線程池是否合適。
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();useCommonPool的判斷是根據ForkJoinPool的並行度,可以簡單地先認為多核下會返回true(也可以通過java.util.concurrent.ForkJoinPool.common.parallelism參數進行設定)。
而使用的commonPool()線程數量不是很多(預設和CPU核數相等),其次ForkJoinPool是設計用於短任務的運行,不適合做阻塞IO,我們要優化的主要慢操作幾乎都是阻塞IO帶來的。
接下去看需求比較接近的Executors.newFixedThreadPool,但通過實現不難發現他的隊列是無界的,如果線程耗盡新的任務就會等待,也無法使用拒絕策略。
只有定製了,根據上面說到的需求,定製如下:
private static final ThreadPoolExecutor IO = new ThreadPoolExecutor(20, 20, 0, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
new CallerRunsPolicy());線程數量定長,數量的多少可以根據測試情況做下調整,使用SynchronousQueue不產生隊列,拒絕策略使用在調用者線程上運行,滿足了所需。
這個線程池專門為IO密集任務使用,不要讓計算密集的代碼使用。
在實踐中遇到了使用這種方式結果測試時性能降低了5倍左右的情況,一看代碼中除了從資料庫獲取數據還有幾個for迴圈在做修改欄位的工作,導致上下文切換帶來了很大的開銷。
思考
上述實現中,限制線程數量的原因是因為線程的開銷(這裡主要是在記憶體上)過大,這就意味著在這裡使用了線程過重了,更好的實現應該使用類似綠色線程的技術,和系統線程進行1對多的映射。
此外這種場景下用事件驅動的方式可能會更好。
追究其核心原因還是java世界中同步阻塞操作還是占多數,而主要的優化手段底層還是使用了昂貴的線程,一些在其他語言/平臺上很容易實現的擴展在java上就會遇到問題。
此外,非同步沒有得到語言上的支持,造成非同步編程在java上比較麻煩和顯式,這點C#的async和await語法糖就要甜的多。
java之後的發展還是任重而道遠啊。
參考資料
reactive design pattern 上述的圖和ParallelRetrievalExample代碼取自這裡


