
一、Spark on Standalone 1.spark集群啟動後,Worker向Master註冊信息 2.spark-submit命令提交程式後,driver和application也會向Master註冊信息 3.創建SparkContext對象:主要的對象包含DAGScheduler和Task ...
一、Spark on Standalone
1.spark集群啟動後,Worker向Master註冊信息

2.spark-submit命令提交程式後,driver和application也會向Master註冊信息


3.創建SparkContext對象:主要的對象包含DAGScheduler和TaskScheduler
4.Driver把Application信息註冊給Master後,Master會根據App信息去Worker節點啟動Executor
5.Executor內部會創建運行task的線程池,然後把啟動的Executor反向註冊給Dirver
6.DAGScheduler:負責把Spark作業轉換成Stage的DAG(Directed Acyclic Graph有向無環圖),根據寬窄依賴切分Stage,然後把Stage封裝成TaskSet的形式發送個TaskScheduler;
同時DAGScheduler還會處理由於Shuffle數據丟失導致的失敗;
7.TaskScheduler:維護所有TaskSet,分發Task給各個節點的Executor(根據數據本地化策略分發Task),監控task的運行狀態,負責重試失敗的task;
8.所有task運行完成後,SparkContext向Master註銷,釋放資源;
註:job的失敗不會重試

二、Spark on Yarn
yarn是一種統一的資源管理機制,可以通過隊列的方式,管理運行多套計算框架。Spark on Yarn模式根據Dirver在集群中的位置分為兩種模式
一種是Yarn-Client模式,另一種是Yarn-Cluster模式
yarn框架的基本運行流程圖
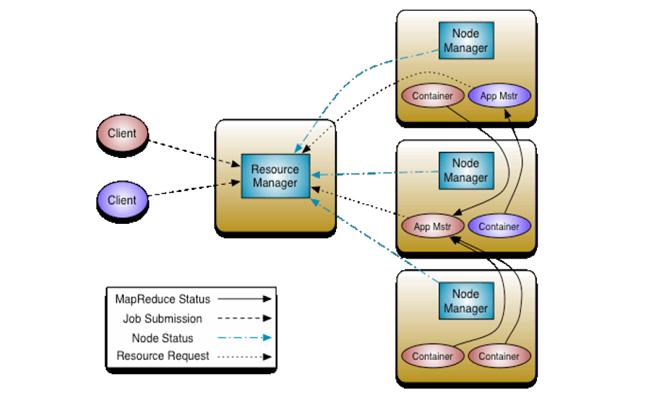
ResourceManager:負責將集群的資源分配給各個應用使用,而資源分配和調度的基本單位是Container,其中封裝了集群資源(CPU、記憶體、磁碟等),每個任務只能在Container中運行,並且只使用Container中的資源;
NodeManager:是一個個計算節點,負責啟動Application所需的Container,並監控資源的使用情況彙報給ResourceManager
ApplicationMaster:主要負責向ResourceManager申請Application的資源,獲取Container並跟蹤這些Container的運行狀態和執行進度,執行完後通知ResourceManager註銷ApplicationMaster,ApplicationMaster也是運行在Container中;
(1)client
yarn-client模式,Dirver運行在本地的客戶端上。
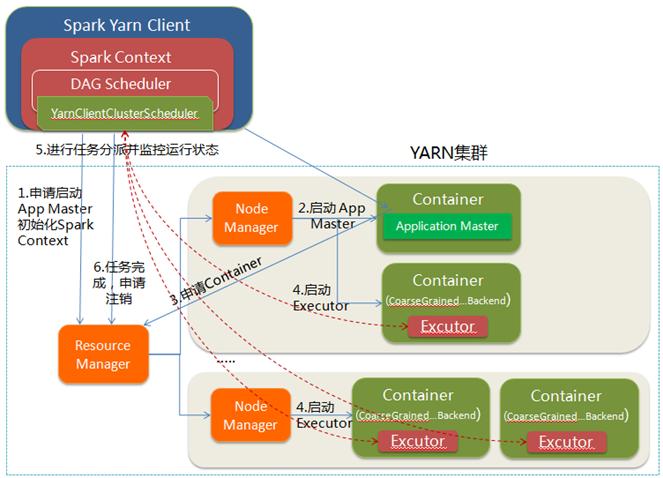
1.client向ResouceManager申請啟動ApplicationMaster,同時在SparkContext初始化中創建DAGScheduler和TaskScheduler
2.ResouceManager收到請求後,在一臺NodeManager中啟動第一個Container運行ApplicationMaster
3.Dirver中的SparkContext初始化完成後與ApplicationMaster建立通訊,ApplicationMaster向ResourceManager申請Application的資源
4.一旦ApplicationMaster申請到資源,便與之對應的NodeManager通訊,啟動Executor,並把Executor信息反向註冊給Dirver
5.Dirver分發task,並監控Executor的運行狀態,負責重試失敗的task
6.運行完成後,Client的SparkContext向ResourceManager申請註銷並關閉自己
(2)cluster
yarn-cluster模式中,當用戶向yarn提交應用程式後,yarn將分為兩階段運行該應用程式:
第一個階段是把Spark的Dirver作為一個ApplicationMaster在yarn中啟動;
第二個階段是ApplicationMaster向ResourceManager申請資源,並啟動Executor來運行task,同時監控task整個運行流程並重試失敗的task;
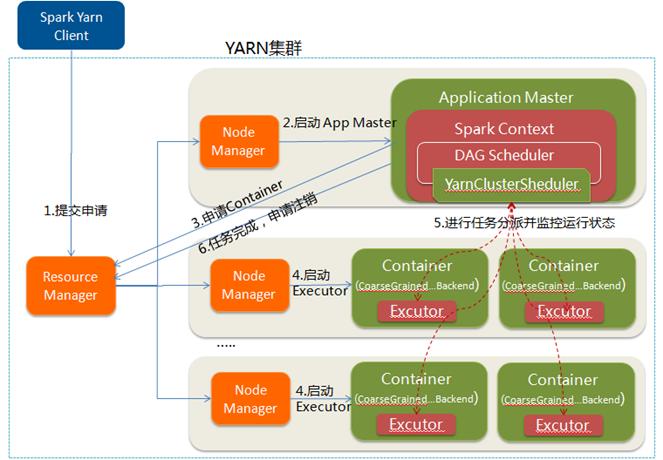
Yarn-client和Yarn-cluster的區別:
yarn-cluster模式下,Dirver運行在ApplicationMaster中,負責申請資源並監控task運行狀態和重試失敗的task,當用戶提交了作業之後就可以關掉client,作業會繼續在yarn中運行;
yarn-client模式下,Dirver運行在本地客戶端,client不能離開。
Dirver與集群間的通信主要有以下幾點:
1.註冊Dirver信息
2.根據寬窄依賴切分stage
3.註冊Application信息
4.分發task
5.監聽task的運行狀態
6.重試失敗的task
7.重試失敗的stage
Spark的數據本地化機制有以下5種:
1、PROCESS_LOCAL 進程本地化
2、NODE_LOCAL 節點本地化
3、NO_PREF 讀取的數據在資料庫中
4、RACK_LOCAL 機架本地化
5、ANY 跨機架
如何選擇數據本地化的級別?
TaskScheduler發送的task在Executor上無法執行時,TaskScheduler會降低數據本地化的級別,再次發送,如果還是無法執行,再降低一次數據本地化的級別,再次發送,直至可以執行。
預設每次等待3s,重試5次,之後降一級本地化級別。
如何提高數據本地化的級別?
task執行的等待時間延長,從原來的3s提高到6s
提高數據本地化的級別要註意,不要本末倒置
spark.locality.wait 預設3s
spark.locality.process 等待進程本地化的時間,預設與spark.locality.wait相等
spark.locality.node
spark.locality.rack
Spark shuffle階段的數據傳輸
MapOutputTrackerWorker(從):在spark集群的每個worker中,負責將本地的map output block信息發送給master中的MapOutputTrackerMaster
MapOutputTrackerMaster(主):在spark集群的master中,負責記錄各個worker節點的map output block信息
BlockManager:每個Executor中的BlockManager實例化的時候都會向Dirver中的BlockManagerMaster註冊信息,而BlockManagerMaster會創建BlockManagerInfo來管理元數據信息
BlockManagerMaster:在DAGScheduler對象中,管理元數據信息
BlockManagerSlaveEndpoint:在Executor端,負責接收BlockManagerMaster發送過來的信息
BlockTransferService:傳輸各個節點的block
MemoryStore、DiskStore


