
由於 0.10.x 版 Kafka 與 0.8.x 版有很大的變化,這種變化對下游 Storm 有非常大的影響,0.10.x 版的 Kafka 不但增加了許可權管理的功能,而且還將 simple 和 high consumer 的 offsets 進行統一管理,也就意味著在 0.8.x 中 Storm ...
由於 0.10.x 版 Kafka 與 0.8.x 版有很大的變化,這種變化對下游 Storm 有非常大的影響,0.10.x 版的 Kafka 不但增加了許可權管理的功能,而且還將 simple 和 high consumer 的 offsets 進行統一管理,也就意味著在 0.8.x 中 Storm 需要去負責管理 offsets,而在 0.10.x 中,Storm 不需要關心 consumer 的 offsets 的問題,這對 KafkaSpout 的設計有很大的影響,本文就是對 Storm 對 0.10.x 版 Kafka 支持的實現部分的解析。
0.10.x 版 KafkaSpout 的實現
社區對新版 Kafka 的支持,總體分為兩種情況:
- 一種是選擇自動 commit 機制;
- 另一種是非自動 commit,就是將 commit 的權利交與 Storm 來控制。
下麵分別對這兩種情況進行分析。
Kafka Consumer 的一些配置會對 Storm 的性能很大影響,下麵的三個參數的設置對其性能的影響最大(預設值是根據MICROBENCHMARKING APACHE STORM 1.0 PERFORMANCE測試得到):
fetch.min.bytes:預設值 1;fetch.max.wait.ms:預設值 500(ms);Kafka Consumer instance poll timeout, 它可以在通過 KafkaSpoutConfig 的方法 setPollTimeoutMs 來配置,預設值是 200ms;
自動 commit 模式
自動 commit 模式就是 commit 的時機由 Consumer 來控制,本質上是非同步 commit,當定時達到時,就進行 commit。而 Storm 端並沒有進行任何記錄,也就是這部分的容錯完全由 Consumer 端來控制,而 Consumer 並不會關心數據的處理成功與否,只關心數據是否 commit,如果未 commit,就會重新發送數據,那麼就有可能導致下麵這個後果:
造成那些已經 commit、但 Storm 端處理失敗的數據丟失
丟失的原因
一些數據發送到 Spout 之後,恰好 commit 的定時到達,進行了 commit,但是這中間有某條或者幾條數據處理失敗,這就是說,這幾條處理失敗的數據已經進行 commit 了,Kafka 端也就不會重新進行發送。
可能出現的這種後果也確定了自動 commit 模式不能滿足我們的需求,為了保證數據不丟,需要數據在 Storm 中 ack 之後才能被 commit,因此,commit 還是應該由 Storm 端來進行控制,才能保證數據被正確處理。
非自動 commit 模式
當選用非自動的 commit 機制(實際上就是使用 Consumer 的同步 commit 機制)時,需要手動去設置 commit 的參數,有以下兩項需要設置:
offset.commit.period.ms:設置 spout 多久向 Kafka commit一次,在 KafkaSpoutConfig 的 setOffsetCommitPeriodMs 中配置;max.uncommitted.offsets:控制在下一次拉取數據之前最多可以有多少數據在等待 commit,在 KafkaSpoutConfig 的 setMaxUncommittedOffsets 中配置;
spout 的處理過程
關於 Kafka 的幾個 offset 的概念,可以參考 offset的一些相關概念
KafkaSpout 的處理過程主要是在 nextTuple() 方法,其處理過程如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public void nextTuple() { if (initialized) { if (commit()) {// Step1 非自動 commit,並且定時達到 commitOffsetsForAckedTuples();// 對所有已經 ack 的 msgs 進行 commit } if (poll()) {//Step2 拉取的數據都已經發送,並且未 commit 的消息數小於設置的最大 uncommit 數 setWaitingToEmit(pollKafkaBroker()); //將拉取的所有 record 都放到 waitingToEmit 集合中,可能會重覆拉取數據(由於一些 msg 需要重試,通過修改 Last Committed Offset 的值來實現的) } if (waitingToEmit()) {//Step3 waitingToEmit 中還有數據 emit();//發送數據,但會跳過已經 ack 或者已經發送的消息 } } else { LOG.debug("Spout not initialized. Not sending tuples until initialization completes"); } } |
上面主要分為三步:
- 如果是非自動 commit,並且 commit 定時達到,那麼就將所有已經 ack 的數據(這些數據的 offset 必須是連續的,不連續的數據不會進行 commit)進行 commit;
- 如果拉取的數據都已經發送,並且未 commit 的消息數(記錄在
numUncommittedOffsets中)小於設置的最大 uncommit 數,那麼就根據更新後的 offset (將 offset 重置到需要重試的 msg 的最小 offset,這樣該 offset 後面的 msg 還是會被重新拉取)拉取數據,並將拉取到的數據存儲到waitingToEmit集合中; - 如果
waitingToEmit集合中還有數據,就發送數據,但在發送數據的過程中,會進行判斷,只發送沒有 ack 的數據。
KafkaSpout 如何進行容錯
舉個示例,如下圖所示
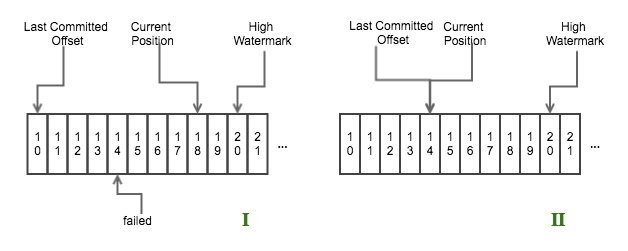
consumer offset
- 圖1表示一個
nextTuple()迴圈結束之後,offset 為14那條數據處理失敗,而offset 為15-18的數據處理成功; - 圖2表示在下次迴圈 Step 1 結束之後、Step 2 開始之前,Consumer 會將 the last committed offset 重置到 offset 為14的位置。
也就是說從 offset 為14開始,後面的數據會重新發送。
有人可能會問,那樣的話會不會造成數據重覆發送?
Storm 是如何解決這個問題的呢?答案就是 Storm 會用一個 map 記錄已經 ack 的數據(acked),Storm 在進行 commit 的時候也是根據這個 map 的數據進行 commit 的,不過 commit 數據的 offset 必須是連續的,如上圖所示,只能將 offset 為11-13的數據 commit,而15-18的數據由於 offset 為14的數據未處理成功而不能 commit。offset 為11-13的數據在 commit 成功後會從 map 中移除,而 offset 為15-18的數據依然在 map 中,Storm 在將從 Kafka 拉取的數據加入到 waitingToEmit 集合時後,進行 emit 數據時,會先檢測該數據是否存在 acked 中,如果存在的話,就證明該條數據已經處理過了,不會在進行發送。
這裡有幾點需要註意的:
- 對已經 ack 的 msg 進行 commit 時,所 commit 的 msg 的 offset 必須是連續的(該 msg 存儲在一個 TreeMap 中,按 offset 排序),斷續的數據會暫時接著保存在集合中,不會進行 commit,如果出現斷續,那就證明中間有數據處理失敗,需要重新處理;
- storm 處理 failed 的 msg,會保存到一個專門的集合中,在每次拉取數據時(是拉取數據,不是發送數據,發送數據時會檢測該數據是否已經成功處理),會遍歷該集合中包含的所有 TopicPartiion,獲取該 partition 的 Last Committed Offset;
這樣設計有一個副作用就是:如果有一個 msg 一直不成功,就會導致 KafkaSpout 因為這一條數據的影響而不斷地重覆拉取這批數據,造成整個拓撲卡在這裡。
Kafka Rebalance 的影響
Kafka Rebalance 可以參考Consumer Rebalance.
KafkaSpout 實現了一個內部類用來監控 Group Rebalance 的情況,實現了兩個回調函數,一旦發現 group 的狀態變為 preparingRabalance 之後
onPartitionsRevoked這個方法會在 Consumer 停止拉取數據之後、group 進行 rebalance 操作之前調用,作用是對已經 ack 的 msg 進行 commit;onPartitionsAssigned這個方法 group 已經進行 reassignment 之後,開始拉取數據之前調用,作用是清理記憶體中不屬於這個線程的 msg、獲取 partition 的 last committed offset。
潛在的風險點
這部分還是有可能導致數據重覆發送的,設想下麵一種情況:
如果之前由於一個條消息處理失敗(Partition 1),造成部分數據沒有 commit 成功,在進行 rebalance 後,恰好 Partition 1 被分配到其他 spout 線程時,那麼當前的 spout 就會關於 Partition 1 的相關數據刪除掉,導致部分已經 commit 成功的數據(記錄在 acked 中)被刪除,而另外的 spout 就會重新拉取這部分數據進行處理,那麼就會導致這部分已經成功處理的數據重覆處理。


