
Daemon Fault Tolerance Storm有一些不同的守護進程 Nimbus負責調度workers supervisors負責運行和殺死workers log views負責訪問日誌 UI負責顯示集群的狀態 What happens when a worker dies? 當一個wor ...
Daemon Fault Tolerance
Storm有一些不同的守護進程
- Nimbus負責調度workers
- supervisors負責運行和殺死workers
- log views負責訪問日誌
- UI負責顯示集群的狀態
What happens when a worker dies?
當一個worker死了以後,supervisor將會重啟它。如果在啟動過程中不斷的失敗,並且不能發送心跳給Nimbus,那麼Nimbus將重新調度這個worker。
What happens when a node dies?
分配到這台機器上的任務會超時,然後Nimbus將這些任務分給其它機器來做。
What happens when Nimbus or Supervisor daemons die?
Nimbus和Supervisor守護進程被設計成快速失敗的(當遇到不期望發生的情況時進程會自殺)並且是無狀態的(所有狀態都保持在zookeeper或者磁碟上)。
Nimbus和Supervisor必須運行在被監督的狀態下(PS:必須對它們進行監控)。因此,如果Nimbus或者Supervisor守護進程死了以後,它們會被立即重啟,就好像什麼事都發生一樣。
尤其是,Nimbus或者Supervisors的死亡對於worker進程沒有任何影響(PS:如果它們死了,沒有worker會受到影響)。這跟Hadoop不一樣,Hadoop中如果JobTracker死了,所有job都會丟失。
Is Nimbus a single point of failure?
如果你失去了Nimbus節點,worker仍然會正常工作。另外,如果worker死了,supervisor會重啟它。然而,如果沒有Nimbus,在某些情況下wokers不能被重新分配到其它機器上(比如:運行worker的機器掛了)。
自從1.0.0版本以後,Storm的Nimbus是高可用的。
Highly Available Nimbus Design
Problem Statement:
目前Storm master又叫做nimbus,nimbus是一個運行在單個機器上的受監督的進程。大多數情況下,nimbus失敗是短暫的,並且它會被supervisor重啟。然而,有時候當磁碟或者網路失敗發生的時候,nimbus就死了。在這種情況下topologies會正常運行,但是不能提交新的topologies了。為瞭解決這些問題,我們採用主備模式運行nimbus以此保證即使一個nimbus失敗了備用的那個可以接替它。
Leader Election(選舉):
nimbus伺服器用下麵的介面:
public interface ILeaderElector { /** * queue up for leadership lock. The call returns immediately and the caller * must check isLeader() to perform any leadership action. */ void addToLeaderLockQueue(); /** * Removes the caller from the leader lock queue. If the caller is leader * also releases the lock. */ void removeFromLeaderLockQueue(); /** * * @return true if the caller currently has the leader lock. */ boolean isLeader(); /** * * @return the current leader's address , throws exception if noone has has lock. */ InetSocketAddress getLeaderAddress(); /** * * @return list of current nimbus addresses, includes leader. */ List<InetSocketAddress> getAllNimbusAddresses(); }
在啟動的時候,nimbus檢查它本地是否有所有激活的topologies的code。一旦它得到這個檢查的狀態之後,它將調用addToLeaderLockQueue()方法。當一個nimbus被通知成為一個leader的時候,它會在假設自己是leadership角色之前再檢查它是不是有所有的code。如果它缺少任何一個激活的topology的code,那麼這個節點無法成為leadership角色,於是它將釋放這個lock,在它為了獲取leader lock之前它必須等待直到它獲得了所有的code。
第一個實現是基於zookeeper的。如果zookeeper連接丟失或者被重置,造成的結果就是失去lock,這種實現關心的是isLeader()的狀態變化。如果一個不是leader的nimbus收到一個請求,將拋異常。
下麵的步驟描述了一個nimbus故障轉移方案:假設,有4個topologies正在運行,3個nimbus結點,code-replication-factor = 2。我們假設“The leader nimbus has code for all topologies locally”在開始之前一直是true。非leader結點“nonleader-1”和“nonleader-2”各有2個topologies的code。假設Leader nimbus死了,硬碟壞了以至於沒有恢復的可能。這個時候nonleader-1收到了zookeeper的通知表示它現在是新的leader,於是在接受成為leadership角色之前它檢查它手上是不是有4個topologies(這些topologies在/storm/storms/目錄下)的code。它意識到它只有2個topologies的code以至於它必須放棄lock,並且查看/storm/code-distributor/topologyId目錄以找到從哪兒可以下載到它缺失的topologies。它發現從leader nimbus和nonleader-2那兒都可以。它嘗試從這兩個地方下載。nonleader-2也意識到它還缺2個topologies,並且按照之前相同的方法下載它所缺失的topologies。最終,它們當中至少有一個會獲得所有的code,於是那個nimber將接收leadership成為新的leader。
下麵的時序圖描述的是leader選舉和故障轉移是如何進行的:
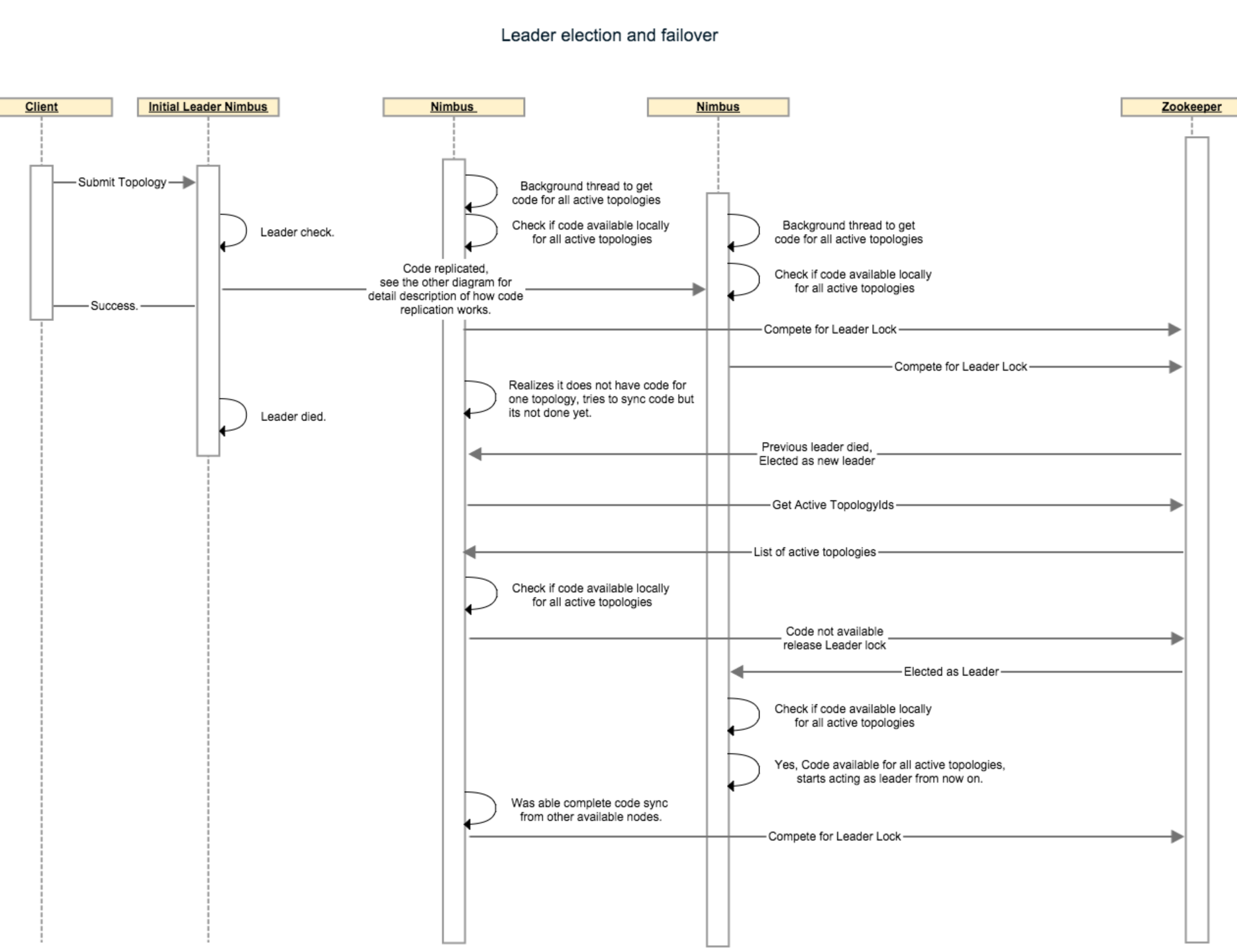
Nimbus state store:
目前,nimbus存儲2種數據,一種是元數據(比如supervisor info、assignment info)被存儲在zookeeper上,另一種是實際的topology配置和jars存儲在nimbus所在的主機的本地磁碟上。
為了能夠成功的故障轉移從主切換到備,nimbus state/data需要被覆制到所有的nimbus主機上或者需要被存儲到一個分散式的存儲設備上。正確的複製數據包含狀態管理、一致性檢查,並且即使不正確也很難測試出來。然而,許多storm用戶不想額外的依賴像HDFS那種副本存儲系統而且還想高可用。最終,我們想到用比特流協議來移動給定大小的代碼分佈,而且也是為了當supervisors數量很高的時候能獲得更好的伸縮性。為了支持比特流和所有基於副本存儲的文件系統,我們建議用下麵的介面:
/** * Interface responsible to distribute code in the cluster. */ public interface ICodeDistributor { /** * Prepare this code distributor. * @param conf */ void prepare(Map conf); /** * This API will perform the actual upload of the code to the distributed implementation. * The API should return a Meta file which should have enough information for downloader * so it can download the code e.g. for bittorrent it will be a torrent file, in case of something * like HDFS or s3 it might have the actual directory or paths for files to be downloaded. * @param dirPath local directory where all the code to be distributed exists. * @param topologyId the topologyId for which the meta file needs to be created. * @return metaFile */ File upload(Path dirPath, String topologyId); /** * Given the topologyId and metafile, download the actual code and return the downloaded file's list. * @param topologyid * @param metafile * @param destDirPath the folder where all the files will be downloaded. * @return */ List<File> download(Path destDirPath, String topologyid, File metafile); /** * Given the topologyId, returns number of hosts where the code has been replicated. */ int getReplicationCount(String topologyId); /** * Performs the cleanup. * @param topologyid */ void cleanup(String topologyid); /** * Close this distributor. * @param conf */ void close(Map conf); }
為了支持複製,我們允許用戶指定一個代碼複製因數,這個複製因數表示在開始topologies之前代碼必須被覆制到多少個nimbus主機上。我們把zookeeper上維護的激活的topologies的列表作為我們的權力,表示這些topologies代碼必須存在於nimbus主機上。任何一個沒有在zookeeper上標記為active的所有的topologies代碼的nimbus必須放棄它的lock,以至於其它的nimbus能夠成為leader。在所有的nimbus主機上都有一個後臺線程不斷的嘗試從其它的主機那裡同步代碼,所以只要還有一個種子主機上存在所有的active的topologies,那麼最終至少有一個nimbus會變成leadership。
下麵的步驟描述了對於一個topology在nimbus之間的代碼複製過程:當客戶端上傳了一個jar文件,傳就傳了,什麼也不會發生。而當客戶端提交了一個topology的時候,leader nimbus調用code distributor(代碼分發器)的upload函數,這將會在leader nimbus本地創建一個metafile文件。leader nimbus將在zookeeper上的/storm/code-distributor/topologyId目錄下寫一個新的入口,以此通知所有的非leader的nimbus它們應該下載這個新代碼。在用戶配置的超時時間內,客戶端必須等待leader nimbus確保至少有N個非leader nimbus已經完成了代碼複製。當一個非leader nimbus接收到關於這個新代碼的通知的時候,它從leader nimbus那裡下載這個meta file,並且通過調用代碼分發器的download函數下載這個metafile所代表的真實的代碼。一旦非leader nimbus完成了代碼下載,這個非leader nimubs會向zk的 /storm/code-distributor/topologyId目錄下寫一個新的入口以此表明這是一個可以下載代碼的metafile的位置,這樣做是為了以防萬一leader nimbus死了。然後leader nimbus繼續做它該做的事情。
下麵這個時序圖描述了在代碼分發過程中各個組件之間的通信:
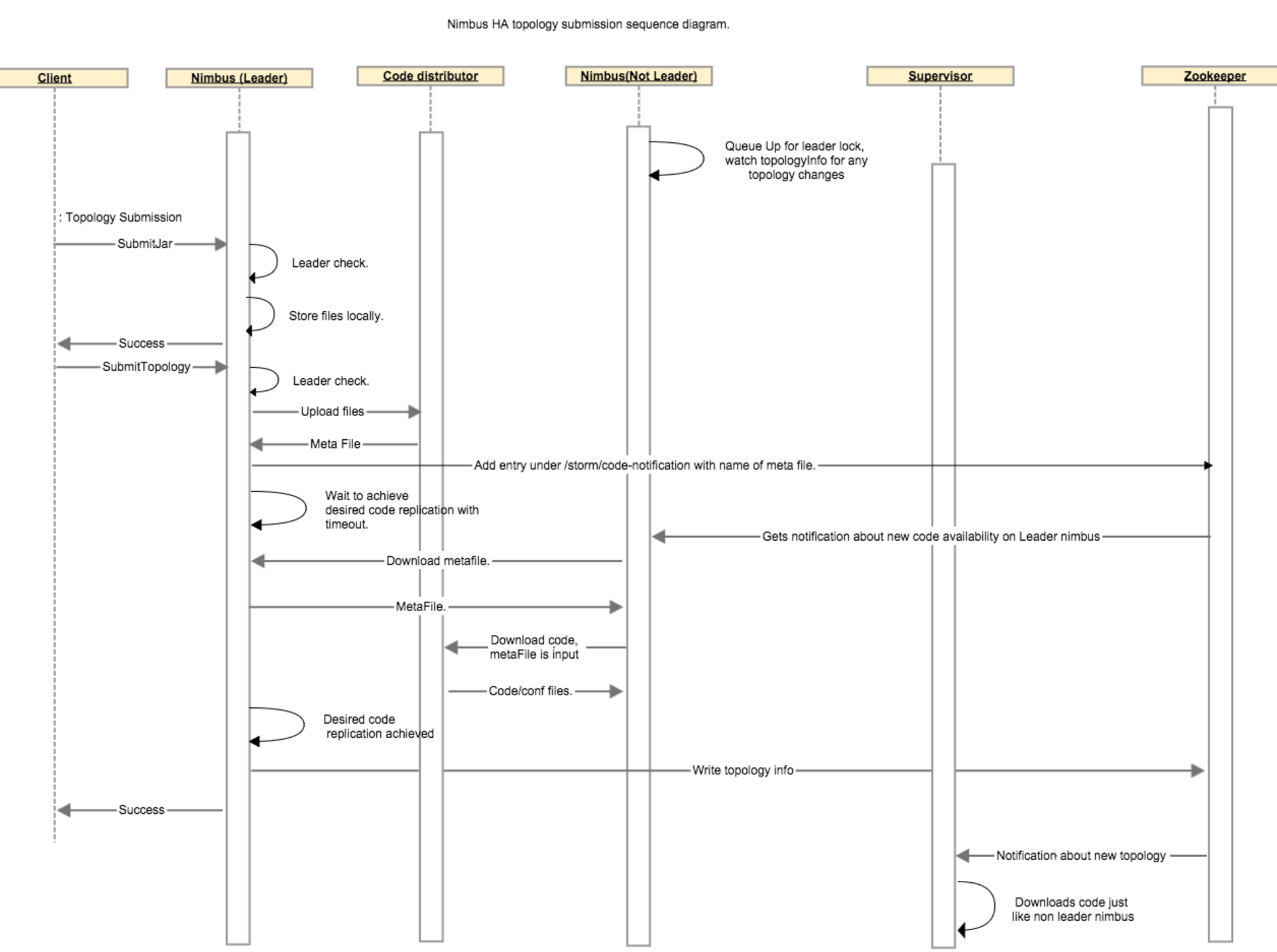
本節重點
守護進程容錯
1、如果worker死了,那麼supervisor會重啟它,如果還是失敗,則由nimbus重新指定機器運行它
2、如果worker所在的機器掛了,那麼這台機器上的所有未完成的任務將分配給其它機器去執行
3、如果nimbus或者supervisor死了,它們會被快速重啟,就好像什麼都沒發生一樣
4、nimbus和supervisor必須有監控,它們必須運行在監督之下
5、nimbus或者supervisor死了對worker進程沒有影響
高可用的Nimbus設計
1、Nimbus HA採用的是主備模式,主節點掛掉以後從節點會接替主節點
2、Nimbus存儲兩種類型的數據
- 元數據,包括supervisor info, assignment info(任務分配的信息)。這些信息保存在zookeeper中。
- 實際的topology配置和jars存儲在nimbus主機的本地磁碟上
3、為了能夠更好的故障轉移,這些狀態以及數據必須被覆制到所有的nimbus上或者存到一個分散式的存儲上。Storm內部使用的比特流協議來複制的。
4、用戶自定義副本因數來決定代碼必須被覆制到多少個nimbus上
5、每個nimbus都有一個後臺線程不斷的嘗試從其它主機那裡同步代碼
6、複製的流程如下:
(1)當leader nimbus收到一個客戶端提交的topology時,它調用代碼分發器的upload方法,這將在本地創建一個metafile來保存topology的元數據,緊接著zookeeper的/storm/code-distributor/topologyId目錄下寫一個新的數據,以此通知所有的nonleader nimbus它們應該下載這個新代碼;
(2)客戶端在提交這個topology以後一直處於等待狀態,直到leader nimbus確保至少有N個non leader nimbus已經完成了代碼複製,或者超時返回;
(3)當一個non leader nimbus收到這樣一個通知以後,首先從leader nimbus那裡下載metafile,然後下載真實的代碼,這些都完成以後它會往/storm/code-distributor/topologyId再寫一個入口以表明從它那裡可以下載代碼的metafile
7、leader選舉是基於zookeeper實現的
8、選舉的過程如下:
(1)nimbus在啟動的時候檢查自己本地是不是有所有的在zookeeper上標記為active狀態的topologies的代碼,如果沒有則不能入隊,有的話就調用addToLeaderLockQueue()函數以求獲得leadership lock;
(2)當一個non leader nimbus被通知它可以成為新的leader的時候,這個nimbus會再次檢查它本地是不是有所有的topologies的代碼,如果是不是,那麼它必須放棄lock,為了再次入隊獲得leadership lock它必須等待直到它收集到所有的代碼;如果是的話,那麼它將成為leader;
參考
http://storm.apache.org/releases/1.1.1/Daemon-Fault-Tolerance.html
http://storm.apache.org/releases/1.1.1/nimbus-ha-design.html


